- Emberek százait rúgta ki az Android- és Pixel-csapatból a Google
- Váratlan támogatókat talált Elon Musk az OpenAI elleni peréhez
- Az Alphabet és az NVIDIA is beszállt a cégbe, ami a következő AI-nagyágyú lehet
- Pár nap, és humanoid robotok is futják már a félmaratont
- Google AI segíti az amerikai áramhálózat fejlesztését
- Synology NAS
- Flip (IPTV, otthoni internet, vezetékes telefon)
- Telekom otthoni szolgáltatások (TV, internet, telefon)
- Linux kezdőknek
- Milyen routert?
- Emberek százait rúgta ki az Android- és Pixel-csapatból a Google
- ASUS routerek
- Manjaro Linux
- One otthoni szolgáltatások (TV, internet, telefon)
- Commodore 64
-

IT café
A legtöbb kérdésre (igen, talán arra is amit éppen feltenni készülsz) már jó eséllyel megtalálható a válasz valahol a topikban. Mielőtt írnál, lapozz vagy tekerj kicsit visszább, és/vagy használd bátran a keresőt a kérdésed kulcsszavaival!

Új hozzászólás Aktív témák
-
válasz
 Sanyi19
#51042
üzenetére
Sanyi19
#51042
üzenetére
ha olcsóbb lesz 20 % előrelépéssel nem annyira rossz a 5060 Ti. A jótol is messze van,de vállalható középkategóriás kártya. lehet. Angliában megérkeztek az első 5070-5080 kártyák amik MSRP ár alatt elérhetőek voltak. [link]
Talán májusban helyre áll a készlet és az árak is alakulni fognak. -
#51041
 deathcrow42
őstag
tomgabor
#51040
deathcrow42
őstag
tomgabor
#51040
-

S_x96x_S
addikt
(USA VÁM) nvidia: Taiwan --> Mexico --> USA.
"Tariff Armageddon? | GPU Loopholes, Mexico Supply Chain Shift, Wafer Fab Equipment Vulnerabilities, Optical Module Pricing Surge, Datacenter Equipment UPS, Generators, Transformers, Switchgear, Power Distribution Equipment, Chillers, Cooling, Pumps, OEM & ODM Supply Chain, Lasers, Softbank Impact, Nvidia Balance Sheet Usage"
https://semianalysis.com/2025/04/10/tariff-armageddon-gpu-loopholes/"Parts and accessories” reveal a much higher dependence on Asia. Taiwan dominates, but China is a significant player, too. Given the increasing mix shift to GB200, NVIDIA imports may shift more towards Taiwan moving forward. However, given the USMCA driven loophole, the supply chain may try to re-export these components through Mexico to incur zero tariffs"
"
Here is a quick recap on the supply chain flow of Nvidia’s Oberon and HGX products.
1. The GPU packages are shipped from TSMC to FII (Foxconn) and Wistron for board assembly.
2. Wistron and FII assemble the GPUs onto different configurations of boards, including HGX universal baseboard (UBB) and Bianca board (GB200).
3. The boards are then sold back to Nvidia by Wistron and FII.
4. Nvidia sells the boards to different ODM’s for L6-L11 assembly, where they assemble the boards into GPU server chassis and racks."
""" -

Raymond
titán
válasz
 yarsley
#51031
üzenetére
yarsley
#51031
üzenetére
Mindegy lesz ennel a kartyanal szerintem. Messze a legolcsobb 16GB NV kartya es most a savszel is eleg ahhoz hogy a VRAM-ba belefero LLM+KV$+ctx olyan 25-30 tok/s generaljon. Kettobe pedig a Qwen2.5 32B es Gemma3 27B belefer Q6-al a Mistral 24B pedig Q8-al is es azok is elmennek 15 tok/s korul "csupaszon" es 25-30-al ha van draft modell is. A Deepseek R1 Distill verzioi 32B meretben is OK, a QwQ 32B is ugyan belefer, de 15 tok/s azert ott lehet valakinek az idegeire menne mert bonyolultabb valaszoknak 10-15K token is megvan a "gondolkodas" es hat 10-15 percet varni a valaszra nem az igazi.
-
#51033
 s.bala31
őstag
ScomComputer
#51026
s.bala31
őstag
ScomComputer
#51026
s.bala31
őstag
válasz
 ScomComputer
#51026
üzenetére
ScomComputer
#51026
üzenetére
Kíváncsi vagyok mi lesz majd a vámokkal, szerintem azokat is visszavonja nem csak 90 napra. Talán sikerült jobb belátásra téríteni mert olyan mint egy elszabadult hajóágyú

-
-
#51030
 Busterftw
nagyúr
ScomComputer
#51026
Busterftw
nagyúr
ScomComputer
#51026
Busterftw
nagyúr
válasz
ScomComputer
#51026
üzenetére
Jensennek nagyon bejonnek ezek a vacsorak (tavalyi hir)

Elon Musk and Larry Ellison begged Nvidia CEO Jensen Huang for AI GPUs at dinner -
#51028
 b.
félisten
ScomComputer
#51026
b.
félisten
ScomComputer
#51026
válasz
ScomComputer
#51026
üzenetére
Ügyes

-
#51027
 hokuszpk
nagyúr
ScomComputer
#51026
hokuszpk
nagyúr
ScomComputer
#51026
hokuszpk
nagyúr
válasz
ScomComputer
#51026
üzenetére
+ a golfozók is előnyben !

-
#51026
 ScomComputer
veterán
ScomComputer
veterán
-

Yutani
nagyúr
válasz
 S_x96x_S
#51019
üzenetére
S_x96x_S
#51019
üzenetére
Ez még sz@rabb lesz, mint fentebb írtam. Megcsináltam matekot, Geekbench Vulkan alapján 3060 Ti +20%. Ne legyen igaz!

Szerk: Mondjuk a GB viszony nem feltétlenül egy az egyben fordul le a játékokban nyújtott tempóra. GB alapján 5-6% van a 3060Ti és 4060Ti között, TPU fDH- 14-15%. Talán van még remény.
-
S_x96x_S
addikt
"NVIDIA GeForce RTX 5060 Ti 16 GB GPU Benchmarks & Specs Leak: Up To 14% Faster Than 4060 Ti"
https://wccftech.com/nvidia-geforce-rtx-5060-ti-16-gb-benchmarks-specs-leak-14-percent-faster-4060-ti/"the NVIDIA GeForce RTX 5060 Ti 16 GB GPU scores 140,147 points in the Vulkan and 146,234 points in the OpenCL tests. This is a lead of 14% and 13% over the RTX 4060 Ti which is decent but not groundbreaking. The RTX 5060 Ti will support all the latest Blackwell GPU features such as DLSS 4, Multi-Frame Generation, Reflex 2, and more."
-
#51011
 yarsley
aktív tag
deathcrow42
#51000
yarsley
aktív tag
deathcrow42
#51000
yarsley
aktív tag
válasz
 deathcrow42
#51000
üzenetére
deathcrow42
#51000
üzenetére
200 ezertől kezdődő 5060TI az nem rossz, 16GB vrammal.
200k-ért 4070 super teljesítmény nem lenne rossz, meg nem lenne annyira látványos ugrás se, de magszám meg órajel alapján ez csak 7700XT - 6800 szint lesz ami meg 2025-ben inkább kiábrándító, legalábbis nekem.
-
#51010
deathcrow42
őstag
Hát ez így nagyon nem egyértelmű. Drágább a 9070, gyorsabb ugyanannyival. DLSS > FSR, támogatottságban pláne. 9070 több VRAM, de azért a 45 játék x 3 felbontás alapján nincs durva bottleneck.
Blender meg productivity esetén meg egyértelműen nvidia.
-
#51008
S_x96x_S
addikt
gainwardgs
#51004
S_x96x_S
addikt
válasz
 gainwardgs
#51004
üzenetére
gainwardgs
#51004
üzenetére
> meg hát 128bit
A GDDR7 azért sokat segít a memory bandwidth-nél;

RTX 4060 TI - 288 Gb/s - GDDR6; 18 Gbps; 128 bit
RTX 5060 TI - 448 Gb/s - GDDR7; 28 Gbps; 128 bit( adatokat innen másoltam )
-
#51007
 4264adam
veterán
gainwardgs
#51006
4264adam
veterán
gainwardgs
#51006
4264adam
veterán
válasz
gainwardgs
#51006
üzenetére
1440p-n használtam
-
#51005
4264adam
veterán
gainwardgs
#51004
4264adam
veterán
válasz
gainwardgs
#51004
üzenetére
semmi baj nincs a 128 bittel. bootleneck nélkül ment a 4060Ti 16GB is rajta ha kell a Vram mennyiség a 128 bit és GDDR6 tökéletes párosítás még mindig PCI-E 3.0 lapban is. PCI-E 4- 5.0 lapban meg főleg
-
#51004
 gainwardgs
veterán
deathcrow42
#51000
gainwardgs
veterán
deathcrow42
#51000
gainwardgs
veterán
válasz
deathcrow42
#51000
üzenetére
Igen sovány lesz az a gpu, meg hát 128bit

-
#51003
deathcrow42
őstag
b.
#51001
-
#51001
b.
félisten
deathcrow42
#51000
válasz
deathcrow42
#51000
üzenetére
Linked van hozzá?[NVIDIA Sends MSRP Numbers to Partners: GeForce RTX 5060 Ti 8 GB at $379, RTX 5060 Ti 16 GB at $429]
Azért így sem egy kiemelkedő deal, remélem benéz 200 K alá is.Kösz közben megtaláltam.

Hogyan fog ez beleférni a 4-500 dolláros 16 GB GDDR7 rammodulok árazásába?![;]](//cdn.rios.hu/dl/s/v1.gif)
-
#51000
deathcrow42
őstag
Hoppá!
The entry‑level 8 GB variant is set at an MSRP of ¥3,199 (roughly $379), while the 16 GB version carries an MSRP of ¥3,599 (about $429)
200 ezertől kezdődő 5060TI az nem rossz, 16GB vrammal.
Igen, tudjuk, hogy az elején lesz vagy 250k, de baszki 220k környékén simán jó vétel lesz az 5060TI 16GB.
-
D55
senior tag
Tehát akkor ha jól értem a CUDA magok által értett low level utasításkészlet olyan radikális változásokon megy keresztül generációnként, hogy ennek HAL (driver) szinten kell mindig töredelmesen utánamenniük, hogy az egységes API-t biztosító CUDA könyvtárak működését az új hardware-hez is biztosítani tudják. És akkor gyakorlatilag a 32 bites címzésre nem fordították már le a Blackwell architektúráját is támogató új library-t, hanem ennek a 32 bites címtérben meghívható függvénytárnak már csak egy korábbi, Ada-ig kompatibilis változatát tartalmazzák a drivercsomagok.
-
#50998
Busterftw
nagyúr
Alogonomus
#50997
Busterftw
nagyúr
válasz
 Alogonomus
#50997
üzenetére
Alogonomus
#50997
üzenetére
Igen a hir szerint 5070-el kezdik, szerintem nem meglepo, 5090/5080 mar eleg jol allnak a keszletek es az AMD-ra nem ott kell reagalni mennyiseggel, hanem a 5070 szintjen.
Szerintem a 5060 is ezert lett eltolva, igy lehet jobb indulo keszlet.
-
#50997
 Alogonomus
őstag
Busterftw
#50994
Alogonomus
őstag
Busterftw
#50994
Alogonomus
őstag
válasz
 Busterftw
#50994
üzenetére
Busterftw
#50994
üzenetére
Az irány jó, de azért valószínűleg nem véletlen, hogy elsőre csak a legkisebb terhelést jelentő leggyengébb kártyán tesznek próbát az SK Hynix modulokkal. Viszont így talán az 5060-ak is Hynix memóriával érkezhetnek, míg a komolyabb kártyák megmaradnak a Samsung egységeinél.
-

Abu85
HÁZIGAZDA
Mi köze az ARM-nak ahhoz, hogy nincs 32 bites CUDA runtime?
Használhatják, hiszen van hozzá támogatás. Ezt kellene az NV-nek is csinálni, és nem lenne annyi bug a meghajtókban.
A ZLUDA az egyetlen reális lehetőség arra, hogy a GPU-s PhysX valaha is működőképes legyen még az RTX 50-es VGA-kon.
#50995 D55 : Nem, ez nem hardveres gond. Egyszerűen hiányzik a 32 bites CUDA runtime. Az NVIDIA nem írta meg a szoftvert. Túl drágának tarthatták, így nem fért bele a költségkeretbe. Azért vegyétek számításba, hogy az NV már egy AI cég. A K+F AI-ra megy, és ha ezért be kell áldozni mást, mondjuk a GPU-s PhysX-et, akkor beáldozzák, mert az AI-ból jön vissza a pénz, a GPU-s PhysX-ből nem. Az NV egy profitorientált cég, ha valamit túl drágának ítélnek, és nincs reális megtérülése, akkor nem írják meg a szoftvert. Tök mindegy, hogy mennyire érinti hátrányosan a játékosokat, ez már nem a fő piac. Ha emiatt bepipulnak a userek és nem vesznek több GeForce-ot, akkor több kapacitás marad a drágábban eladható AI gyorsítókra, tehát az NV-vel ezzel nem csesznek ki, csak több pénzt fognak keresni akkor, ha nem kell több GeForce-ot gyártani.
-
D55
senior tag
Jól gondolom, hogy a probléma gyökere valami olyasmi akkor, hogy a Blackwell CUDA magjai low level nem esznek meg már 32 bites címzésű utasításokat, ezt szüntették volna meg most hw szinten a korábbi generációkhoz képest? Vagy eleve voltak eddig is akkora eltérések az egyes generációk utasításkészletében, hogy HAL szintjén mindig implementálni kellett a különböző generációk között egységes API-t nyújtó kódfordítást és ebből került most ki szimplán high level oldalról (illetve nem került be a Blackwell targethez már) a régi 32 bites címzésű könyvtár amit a régi PhysX 2 runtime használt?
-
Busterftw
nagyúr
Igy is eleg jol allnak a keszletek, most mar nem csak a Samsung szallit GDDR7-et.
NVIDIA now using SK hynix GDDR7 memory for GeForce RTX 50 series -
Gondolom ez mögött más van,nem a hihetetlen meglátásod, akár tippre a Cuda for Arm van az egész mögött az őszi CPU bejentés mellé.
Majd jelezd az AMD nél is a mérnököknek hogy az Rx 500-at sokan használják még a Pascal mellett...
A ZLUDA egy garázsprojekt AMD fanoknak,nem lehet komolyan venni , erre senki nem fog alapozni aki komolyan , professzionális vagy munka szinten akarja hazsnálni a CUDA szolgáltatásait. -
Abu85
HÁZIGAZDA
válasz
Busterftw
#50991
üzenetére
A ZLUDA van messze a legközelebb ahhoz, hogy ez az egész egyáltalán működjön, mert pont azt biztosítja, amit az NV már nem szállít.
Kibaszottul hangsúlyozom, hogy ehhez nem nyílt PhysX kell. Nem a PhysX-szel van probléma, hanem a futtatási környezet hiányával. A kód a játékokon belül működik, azt értelme sincs cserélni, mert nem amiatt nem futnak az effektek. Új futtatási környezet kell, ami meg tudja enni a kódot, és el tudja juttatni a GPU-ra. Ez tényleg nem világos?

-
Busterftw
nagyúr
-
-
Jó szerintem - és ez csak az én véleményem - túl van ez spilázva kissé. Más gyártóknál már driveres támogatás sincs 3 generációval ezelötti kártyákra..
Szerintem túl lehet ezt élni valahogy hogy a 64 bites Physix támogatás fut az 5000-es szérián már.
Kényelmetlen, de egy olcsó 20 euros másodkártya megoldja a problémát szerintem akinek nagyon hiányzik egy 5070-5090 mellett akár csökkentett PCIE sávszéllel szerelt lapban is. -
#50987
Abu85
HÁZIGAZDA
huskydog17
#50984
Abu85
HÁZIGAZDA
válasz
 huskydog17
#50984
üzenetére
huskydog17
#50984
üzenetére
Oké, akkor segítek.
Tehát vannak játékok, amelyekben nem megy a GPU-s PhysX a GeForce RTX 50-es sorozaton. De fontos megérteni, hogy nem a játék baszódott el, hanem a 32 bites CUDA támogatása nincs meg. Konkrétan hiányzik a runtime, ami a játékba épített kódot futtatni tudja.
A megnyitott kód sem kompatibilis azzal, amit a játékok tartalmaznak, mert a szóban forgó címek még valamelyik PhysX 2 verziót használták, és az 5.6.0 lett megnyitva. Tehát jelentős eltérés van a korábban szállított és a most megnyitott kódok között.
De nem ez a gond, hanem az, hogy akkor sem érnénk el semmit, ha az adott játékban szállított PhysX 2 GPU-s kódját nyitná meg az NVIDIA, mert az alapprobléma nem ez a kód, ez le van szállítva valamilyen köztes nyelvre lefordítva, de a futtatási környezet már nem létezik a hardver felé. Tehát ahhoz, hogy ez működjön a jövőben, egy másik futtatási környezetre van szükség. Hiába cseréled a kódokat a játékban valahogyan, attól még futtatási környezeted nem lesz.
Ennek több megoldása van egyébként:
- Az egyik, hogy átírják kódokat compute shaderre, de az nagy meló, viszont ehhez csak DirectCompute futtatási környezet kell, az meg ugye ott van még mindig az összes meghajtóban.
- A másik, hogy használod a HIP-et. A kódra ráereszted a Hipify-t, de ez sem túl előnyös, mert maga a HIP kód is igényli a CUDA futtatási környezetet. Tehát ezzel a módszerrel csak azt oldanád meg, hogy AMD-n működjön a GPU-s PhysX, de GeForce RTX 50-en továbbra sem fog. Akkor működne csak, ha az NVIDIA írna direkt támogatást a HIP-hez.
- A harmadik megoldás a játék visszafejtése, és a 32 bites bináris átfordítása 64 bitessé. De annyi buktatója van ennek, hogy szinte lehetetlen megcsinálni, anélkül, hogy meglenne a közösségnek az eredeti játék teljes forráskódja. És itt tényleg csak az a gond, hogy 32 bitből nehéz forráskód nélkül 64 bites programot csinálni. Ezt nem oldja meg a nyílt PhysX, mert ettől pont az a tényező hiányzik még, amire szükség lenne: a játék forráskódja. Azzal nem nyers semmit, hogy kicseréled mondjuk a PhysX-re vonatkozó dll-t, mert vagy a 32 bites CUDA runtime, vagy a 64 bites futtatási állomány fog hiányozni.
A ZLUDA azért reális alternatíva, mert az a gyökerénél kapja el a problémát. Nem foglalkozik azzal, hogy átírja a játékot, mert eleve nem az a gond. A runtime hiányzik, és mivel a ZLUDA nem igényel 32 bites CUDA runtime-ot, a CUDA kód futtatásához, ezért pont megkerüli azt a problémát, ami hiányzik a GeForce RTX 50-es sorozatnál. Ezzel a módszerrel nem kell átírni a játékot, nem szükséges visszafejteni azt, nem szükséges a játék forráskódja, mert a 32 bites CUDA runtime-ot cseréli egy olyanra, ami képes gépi kódot generálni a GPU-kra. Azokra is, amelyeknél az NVIDIA nem akarja, hogy kapjanak emészthető kódot, például a GeForce RTX 50-es sorozat.
Egyébként nem muszáj a ZLUDA, más hasonló kezdeményezés is jó, de muszáj azt a tényezőt célozni, ami hiányzik, és az a 32 bites CUDA runtime. Mert hiába cseréled a GPU-s kódokat a PhysX-ben, ettől még runtime-ot nem ad az NVIDIA neked a meghajtóban, ami lefordítja a kicserélt kódot a Blackwell GPU-kra. Tehát nekünk nem a játékot kell babrálni, hanem másik runtime-ot kell írni, ami az NVIDIA hozzájárulása nélkül is kódot generál a GPU-kra.
---
Ami történik a PhysX-szel az nem a régi játékok futtathatóságát szolgálja. Az NVIDIA projekteket indít, fejleszt és zár le. Nagyon tipikus policy ennél a cégnél, hogy ha egy projektet már nem akarnak fejleszteni, akkor megnyitják. És ezért nyitották meg a mostani kódokat, mert a jövőben már nem akarnak ehhez hozzátenni. Ugyanígy tettek a GameWorks bizonyos effektjeivel, stb. Az a célja ennek, hogy a jövőben egy ponton túl nem lesz support. Ott a forráskód és mindenki megoldhatja maga a problémáját, az NV ebből kiszállt, mert nem látják már a hasznot a projektben. A GameWorks után most a PhysX jutott el erre a szintre. Az NVIDIA mindig így csinálja. Ha lelőnek belsőleg egy projektet, akkor megnyitják, hogy vihesse mindenki.
Egyébként más cég is így csinálja. Ha volt egy zárt projekt, amire már nem akarnak figyelni, akkor azt meg szokták nyitni. Ez a jelzés, hogy a projekt már nem fókusz, de aki akarja használhatja tovább, ha karbantartja a saját kódját.
-
#50985
S_x96x_S
addikt
huskydog17
#50984
S_x96x_S
addikt
válasz
huskydog17
#50984
üzenetére
> Amúgy a ZLUDA pont nem a PhysX-et veszi célba,
szerepel a Roadmap -en.
https://vosen.github.io/ZLUDA/blog/zluda-update-q1-2025/""
Roadmap update -> PhysX
As you might have read here, here and on multiple other sites, NVIDIA dropped support for 32-bit PhysX in their latest generation of GPUs, leaving a number of older games stranded.
This reignited the debate about ZLUDA’s PhysX support. After reading through it several times, it’s clear to me that there is a path in ZLUDA to rescuing those games and getting them to run on both AMD and NVIDIA GPUs.
I broke down the implementation into tasks here. If you can program Rust and want to make a lot of people happy, I encourage you to contribute. I won't be able to work on it myself because I'll be busy with PyTorch support, but I'll help in any way I can.
"""
> Ha bárki bármilyen okból szeretné megtudni, hogy hogyan működnek a GPU-s PhysX,
> Flex és Flow effektek, annak most már ott a forráskód, nincs szükség reverse
> engineering-re.az is érdekes probléma,
de a ZLUDA nem igazán a PhysX forráskód átírására fókuszál,
hanem a 32 bites PTX -ek 64 bites környezetbe való forditására és implementálására.
Vagyis a PhysX belső működése helyett a régi binárisok kompatibilitása a cél.
----
https://github.com/vosen/ZLUDA/milestone/6
32bit PhysX support on NVIDIA and AMD:
We can verify that PhysX FluidMark works on NV RTX 5XXX GPUs and AMD GPUs.
This should also automatically make games work, but we will rely on the community to verify it more closely
#355 Add a compiler pass to convert 32 bit PTX to 64 bit PTX
#354 Create 32bit CUDA -> 64 bit CUDA RPC server
#353 Implement missing PTX instruction in ZLUDA for 32 bit PhysX
#352 Collect CUDA logs from FluidMark -
#50984
 huskydog17
addikt
Abu85
#50980
huskydog17
addikt
Abu85
#50980
huskydog17
addikt
OK, ez a te elméleted, majd meglátjuk, hogy a gyakorlat ismét sokadszorra megcáfol-e téged, nem ez lenne az első tévedésed.
A forráskód megnyitása tökéletes arra, hogy szabványos kódot lehessen csinálni belőle, projekttől függetlenül. Minden olyan projekthez nagy segítség lehet, ami CUDA kódból akar szabványos kódot csinálni, hiszen reverse engineering helyett ott a forráskód, ami masszívan meggyorsítja és leegyszerűsíti a dolgokat.
Ezen felül az érintett régi játékokat a fejlesztők kiadók sokkal könnyebben ki tudnák javítani, innentől teljes kontrolljuk van PhysX feature felett is. Az egy más kérdés, hogy ezek a kiadók nem valószínű, hogy időt és pénzt fognak szánni rá, de a lehetőség innentől megvan rá. Például egy ex-fejlesztő írhat akár egy nem hivatalos fix-et a forráskód segítségével vagy segíthet egy moddernek és akkor hirtelen jön egy mod ami megoldja az adott játéknál a gondot.
Ha bárki bármilyen okból szeretné megtudni, hogy hogyan működnek a GPU-s PhysX, Flex és Flow effektek, annak most már ott a forráskód, nincs szükség reverse engineering-re. Ez minden érdeklődőnek óriási segítség. Kiváló tanulási lehetőség is egyben, továbbá azokat a kódokat innentől tovább lehet fejleszteni, illetve azok alapján egy jobb saját fejlesztésű fizikai motort is lehet írni.A ZLUDA - vagy bármely más hasonló kaliberű projekt - fejlesztői amennyiben meg akarják oldani a 32 bites GPU PhysX problémát, azt eddig kizárólag reverse engineering-gel tudták volna elkezdeni, ami ugye fekete doboz, nem sokra mennek vele, de most, hogy nyílt a forráskód, már nem kell vakon fejleszteni, azaz de, pont, hogy a nyílt forráskód fogja megoldani a dolgot, mert úgy sokkal könnyebb. Értelmes fejlesztő nem fog reverse engineering-et alkalmazni, amikor ott a forráskód.

Amúgy a ZLUDA pont nem a PhysX-et veszi célba, hanem a gép tanulást, továbbá egyetlen egy fejlesztője van, így én ott nem várnék a közeljövőben megoldást a PhysX témára, de még a távoli jövőben sem. Na most innentől bárki tud írni másik translation layert, nem kell arra várni, hogy a ZLUDA egy szem fejlesztőjének egyszer talán lesz kedve PhysX-el foglalkozni, amikor nem az a fő szempont. A világon biztosan nem ő az egyetlen olyan fejlesztő, aki képes CUDA translation layert írni, ráadásul a forráskód megnyitása után biztosan nem.
Sokkal valószínűbb, hogy egy másik fejlesztőtől jön majd egy másik translation layer akár egy nem hivatalos mod formájában, ami előbb fogja megoldani a gondot, mint a ZLUDA, ugyanis amíg a ZLUDA a gép tanulásra fókuszál, addig más fejlesztő fókuszálhat kizárólag a PhysX-re, ott a lehetőség.Az AMD tavaly nem véletlen állította le a a ZLUDA finanszírozását, mert jogi szempontból a reverse enginnering nem teljesen állta meg a helyét. Inkább megelőzték a bajt és időben leállították.
A forráskód megnyitása ezt a gondot is kiküszöböli.Szerinted a forráskód semmit nem fog segíteni, szerintem pedig pont ez fogja megmenteni az érintett régi játékokat, majd az idő megmondja kinek fog jobban működni a jósgömbje.
-
#50980
Abu85
HÁZIGAZDA
huskydog17
#50959
Abu85
HÁZIGAZDA
válasz
huskydog17
#50959
üzenetére
Ezzel a nem működő játékokat nem lehet helyrerakni. Nem a PhysX a gond, hanem a CUDA 32 bites futtatási környezetének hiánya. Azt egy nyílt PhysX nem oldja meg, mert egyrészt attól még nem tudod kicserélni a játékban a kódot, másrészt nem tudod a 32 bites binárist átalakítani 64 bitessé.
Ezt a problémát a ZLUDA kezdeményezése tudja megoldani, ami lehetővé tenné a meglévő kód futtatását a 32 bites CUDA futtatási környezet nélkül is.
-
Hát, ez ilyen ízlésbeli dolog - nekem a széthúzásba beletartozna a value proposition megőrzése vagy a változás nyílt(abb) kommunikálása. Hívhatjuk sunnyogós széthúzásnak
A fanyalgás onnan jön, hogy pl. a 4060-as kártya jóval gyengébb ajánlat volt, mint az 1060-2060-3060 vonalon bármi (pedig már a 3060 sem volt hardcore acélos), és ha összeveted akár a 4080-nal, akkor látszik, hogy az inkább egy átpozícionált 4050, csak több fogyasztással, miközben ugyanazokat a marketing-üzeneteket rakták mellé, mint a korábbi 60-asoknak. Nyilván a 4090-nel összevetve sokkal hangzatosabb %-okat kapsz, és jobban clickelt cikkek készülnek belőle
Most meg ugyanez az 5070-nel.Nekem az 5050 8GB VRAM-mal és egy egyszerű aktív hűtéssel is jó lenne, szintén 70-80W fogyasztással. De egyre inkább úgy fest, idén bringát veszek
-

lenox
veterán
Ujrapozicionalas, ugy hogy nagyobb a kulonbseg a 70 es 80 kozott az a szethuzas, nem?
Igy van, azert is nem ertem a fanyalgast, 90-ek overkill kartyak, csak mert blackwellnel extra overkill, attol nem lesz az 5060 rosszabb.
Egy 75 wattos 5050 16 gb tammal es passziv hutessel, nekem ilyen kene. Egy RTX 2000 Ada-t faragok, az jo lenne, csak meg passziv hutes nincs hozza.
-
Igen, csak ez nem széthúzás, hanem a korábbi SKU-k újrapozícionálása és új nevek bevezetése - gondolom ezzel próbálják eltakarni, hogy valójában mekkora áremelés is történt.
HD casual gamingre az 1060 bőven sok volt, és most a 4060 is bőven az. Én pont azért szeretnék egy értelmes 50-es kártyát, mert fullHD-ben mindenre elég lenne. -
lenox
veterán
Pascalnal 1070-tol 1080-ig 3 szint volt, elotte 2, Ada-nal 5. Van logikaja, hogy arban es felepitesben is kicsit szethuzzak, en nem latok semmilyen dramatikus visszavagast. Az arak nyilvan mennek fel, sok okbol. Szerintem az erdekes meg, hogy HD casual gamingre melyik generacioban melyik alkalmas, szerintem ott se az jon ki, hogy regen a 1060 is eleg volt, most meg mar csak az 5080, hanem pont forditva.
-
S_x96x_S
addikt
Mi számítson 1 GPU-nak?
az nvidia új definíciója:
( "a Blackwell (~B300 ) valójában 2 GPU - egy Blackwell chip-en" )
és a sw licenszelés - GPU -ra vonatkozik.
( vagyis a változás a vevőknek nem jó, de a részvényeseknek jó ... )--------
"Nvidia’s AI suite may get a whole lot pricier, thanks to Jensen’s GPU math mistake"
Old naming convention didn't just 'screw up' the NVLink nomenclature - it left money on the table
https://www.theregister.com/2025/04/01/nvidia_ai_enterprise_cost"""
At its GPU Technology Conference last month,
Nvidia broke with convention by shifting its definition of what counts as a GPU.
"One of the things I made a mistake on:
Blackwell is really two GPUs in one Blackwell chip,"
CEO Jensen Huang explained on stage at GTC.
"We called that one chip a GPU and that was wrong.
The reason for that is it screws up all the NVLink nomenclature."
However, Nvidia's shift to counting GPU dies, rather than SXM modules, as individual GPUs doesn't just simplify NVLink model numbers and naming conventions.
It could also double the number of AI Enterprise licenses Nvidia can charge for....
If we had to guess, we'd wager in the year since Nvidia unveiled Blackwell, the GPU giant realized it was leaving subscription software revenues on the table.
We say it looks like because when we asked Nvidia how the naming change would impact AI Enterprise licensing, they told us pricing details hadn't been finalized yet.
"Pricing details are still being finalized for B300 and no details to share on Rubin beyond what was shown in the GTC keynote at this time," a spokesperson, who clarified that this also included AI Enterprise pricing, told El Reg.
"" -
#50972
 gbors
nagyúr
deathcrow42
#50971
gbors
nagyúr
deathcrow42
#50971
válasz
deathcrow42
#50971
üzenetére
Mindkettőt érdemes nézni, csak más okokból. Ha a kettőt sikerült összekeverni - na abból lesznek veretes marhaságok
-
#50971
deathcrow42
őstag
Yutani
#50969
-
Azért írtam, hogy sokkal kevésbé ordító. De lehet, hogy félreérthető volt - azt akartam mondani, hogy a csökkenés megfigyelhető, de jóval kisebb mértékben. Ill. ha messzebbre mész vissza, akkor:
5070 - 57.1 %
4070 - 60.5 %
3070 - 67.6 %
2070 - 78.2%
1070 - 75%
970 - 81%
670 - 87.5%Azaz 6 generációváltás alatt a relatív xx70 "ALU-tartalom" 2/3-ára csökkent az xx80-hoz képest, ami generációnként átlagosan 7% visszavágást jelent. Ezalatt a 70-es kártya MSRP-je 37.6%-kal nőtt, a 80-asé pedig 100%-kal, tehát az átpozícionálást az árak is tükrözik bizonyos mértékben.
-
lenox
veterán
#50935 alapjan feldolgozokat nezve legnagyobb chiphez viszonyitva:
3070 - 54.7 %
4070 - 31.9 %
5070 - 25 %x080-hoz kepest:
3070 - 67.6 %
4070 - 60.5 %
5070 - 57.1 %Csak egybitesen szamolva jon ki, hogy ez ugyanaz, elsonel 46%-ara, masodiknal 84%-ara esett ket gen alatt a viszony, Tehat ahhoz kepest, hogy az nv fele akkora chipet ad a 70-es kategoriaban, mint korabban, valojaban minimalisan nott a 70 vs 80 kozotti lepcso.
-
Rossz topic...
-
Ha a 80-as az alap, akkor is jól megfigyelhető ez a trend, főleg, ha a Keplertől indulsz el, de persze sokkal kevésbé ordító a dolog. Most nincs időm / kedvem óriási táblázatokat készíteni, de valahogy így néz ki az átpozícionálás 8-10 év távlatában:
80 helyett 80 (ha ez az alap)
70 helyett 70Ti
60 helyett 70
50 helyett 60A vásárlónak persze az az érdekes, hogy mennyi pénzért mennyi teljesítményt kap (legalábbis a racionális vásárlónak
), és ha az 5000-es kártyák elérhetőek lennének MSRP áron, akkor nem lenne ez a generáció annyira tragikus. -

DudeHUN
senior tag
Az, hogy miből mennyi van egy chipben az attól függ mekkora. Főleg azonos csíkszélen. Ha kisebb a die és azonos az átlag tranzisztorsűrűség...
Btw. én nem írtam, hogy a legnagyobb kategóriát kell nézni. Az most az átlagnál nagyobb is. De, az tény rtx estén ez 400mm2 pár éve még a 70-es széria volt. A TDP meg nagyot nő, mert gyárilag meg vannak tolva. A GTX 9x, 10x volt még ekkora, viszont ott a többi rendben volt és nem volt extra feldolgozó.
Pl. RTX 2070 445mm2 volt 175W mellett, RTX 5080 378mm2 360W mellett. -
lenox
veterán
válasz
 DudeHUN
#50961
üzenetére
DudeHUN
#50961
üzenetére
Hat szerintem a feldolgozok szama, a membandwidth, az orajel, a tdp az ami alig no, es igazibol csak rancfelvarras, nem uj arch, ezert kicsi az ugras, de szerinted nem ezen mulik, hanem a mm2-en, raadasul nem is csak az adott kategoria, hanem a legnagyobb chip mm2-en. Meg atgondolom
. -
DudeHUN
senior tag
Pedig az érdekes. És ezért van szó arról, hogy kevesebbet kapsz arányaiban többért. Ezért is érződik kisebbnek egy-egy generációs ugrás. Plusz mellé eléggé túljáratva jönnek, hogy minél jobbnak hasson a teljesítmény. Nagyobbat lehet UV-val nyerni, mint OC-zni a kártyákat.
-
#50959
huskydog17
addikt
huskydog17
addikt
NVIDIA PhysX and Flow libraries are now fully open source
Eddig a PhysX CPU része volt nyílt, már kb. 6 éve, most megnyitották a GPU gyorsítás részét is, így a PhysX teljes mértékben nyílt forráskódú lett. Ezzel az NVIDIA megnyitotta az utat, hogy a régi 32 bites GPU-PhysX játékok gond nélkül működhessenek Blackwell szérián is, a lehetőség innentől adott. (Mondjuk eddig is adott volt, ha a játé készítője 64 bitesre portolta volna a játékot.)
Így akár modderek is rendbe tudják rakni az érintett régi játékokat.Ezen felül a Flow nevű, GPU gyorsított folyadékszimuláció is teljesen nyílt forráskódú lett.
Szerintem ez az NVIDIA válasza a PhysX backlash-re, amit jogosan kaptak, szerintem ezzel részükről le is tudták és úgy gondolom ez így rendben is van, ugyanis innentől bárki rendbe tudja tenni a problémás PhysX játékokat, a lehetőség innentől adott. Ezen felül nem csak rendbe tenni lehet az ériontett címeket, hanem tovább lehet fejleszteni az implementációkat. Ez a lépés rengeteg új lehetőséget nyit meg a játék fejlesztők lett.
Flow 2.2.0 és PhysX SDK 5.6.0 forráskód GPU kóddal
A témában egy másik érdekesség:
Az SCS Software sok év után lecseréli a fizikai motort az Euro Truck Simulator 2 (ETS2) és American Truck Simulator (ATS) játékaiban, ahol az eddig használt Bullet motort PhysX-re cserélik. Az SCS viszont kizárólag CPU alapú PhysX-et használ, ami már sok éve nyílt forráskódú.
Az SCS közleménye a témában:
"In 1.54, we are adopting the NVIDIA PhysX physics engine as an alternative to the current Bullet physics engine for low-level simulation of physics in the game world that players interact with. This shift allows players to experience more precise collision detection results and more robust behaviour during scenarios involving collisions between vehicles and obstacles or other vehicles. PhysX also offers our teams better debugging tools, which indirectly benefits players by helping resolve bugs more efficiently.
One of the most noticeable improvements brought by PhysX can already be experienced in our recently introduced Driving Academy game mode. For example, collisions with cones and obstacles are now more accurate and objects no longer appear to "levitate" slightly above the ground after interaction, a flaw that occurred with Bullet. While players may not see drastic changes, certain interactions should exhibit slightly improved behaviour.
During the Open Beta, many players expressed concerns about hardware limitations due to recent news that 32-bit version of PhysX would no longer be supported by certain GPUs. However, the PhysX implementation we use runs entirely on the CPU, meaning players can enjoy PhysX without worrying about graphics card compatibility.
With the release of version 1.54, PhysX is now the default physics engine for all gameplay. Players who prefer the previous Bullet physics engine can switch back by using the "-bullet" command line argument in their Steam launch options." -

paprobert
őstag
válasz
 Raymond
#50954
üzenetére
Raymond
#50954
üzenetére
A 128 bites VGA-k a "már nem csak grafikus adapter, hanem csinál is valamit" kártyák voltak historikusan. Klasszikus *50 *50Ti kártyák.
Ez igazából nem változott, lassan 20 éve, ugyanazt a szerepet töltik be. Csak már súlyosabb pénzt kérnek értük.
A YT komment csúsztat, de erről beszél. Az, ami el lett csalva a termékskála tetején "csúcstermék-szegmentációval", az így jelenik meg lent.
-
lenox
veterán
válasz
 KRoy19
#50940
üzenetére
KRoy19
#50940
üzenetére
Nincs koze ahhoz, hogy en mivel vagyok elegedett, ahhoz van koze, hogy onkenyes a viszonyitasi alap, kb. semmi nem indokolja, hogy azt valassza valaki, amibol marketing celbol csinalnak parat, es amugy 5x-os aron tudjak eladni masik piacon, tehat egeszen biztosan nem azert van hogy mindenki azt vegye. Sokkal jogosabb egy olyan osszehasonlitas, hogy x penzert melyik generacioban mit lehet venni,de csak azert szarabbnak gondolni egy 5070-et, mert az 5090 eroforrasai naggobb mertekben nottek az elozo genhez kepest, az ahogy mar irtam, szerintem hulyeseg. Mindenki azt gondol amit akar, en pl. ezt. Meg azt is gondolom, hogy a userek sokkal nagyobb reszenek erdekesebb a 60-70, mint a 90, keresni egy olyan mutatot, ami azt suggalja, hogy a 60-70-nel visszalepes tortent, pedig tudjuk, hogy nem, az hangulatkeltes. Az arakon van mit fanyalogni, de ha mas is ad erte annyit, akkor sajnos ez ilyen.
-
S_x96x_S
addikt
válasz
 tomgabor
#50950
üzenetére
tomgabor
#50950
üzenetére
> Azt tudjuk, hogy Jensenék itt is megemelik az árakat vagy csak Amerikába?
egyenlőre még mindenki éberen figyel;
mivel a gyógyszerek és a chipek MÉG nincsenek megadóztatva
... de ez hamarosan változik ..."Trump says that chip tariffs are starting 'very soon'"
https://www.tomshardware.com/tech-industry/trump-says-that-chip-tariffs-are-starting-very-soon
" Trump administration is preparing separate tariffs for sectors like semiconductors, pharmaceuticals, and possibly critical minerals. Apparently, Trump expects to impose tariffs on chips 'very soon.'"viszont, ha az nVidia 75%-os árréssel dolgozik, akkor csak a "vasra" rakódik vám;
ami alaphangon minimum +6,5% ;
Vagyis lehet, hogy csak +10%-al meg lehet úszni a kiskereskedelmi ár növekedést.
"For example, if there is a 25% tariff on an Nvidia AI GPU that the company sells for $50,000 with a 75% gross margin, then Nvidia will have to declare a value of $12,500 and pay an import duty of $3,125. Such a tariff will either hurt Nvidia's margins or make its GPUs more expensive for buyers in America. For Elon Musk's next-generation data centers, which are set to contain a million GPUs, this means $3.125 billion of additional cost"---
véleményem szerint
A gyárak - áttelepítési költségeit ( p.. Kínából áttelepíteni a gyártást ; vagy átmozgatni az USA-ba )
úgyis szétterítik globálisan ;
vagyis én itthon is - egy pici áremelkedésre számítok - középtávon.
Persze rövid távon lehetnek nagyobb kilengések mindkét irányba. -
S_x96x_S
addikt
válasz
KRoy19
#50948
üzenetére
> hanem ,hogy az előző generációkban
> a 80-as class hol helyezkedett el spec/teljesítmény tekintetében
> az abszolút csúcshoz képest.A régebbi generációkban a "csúcs" - az NVLINK-es GPU -volt.
Ami most már nincs. RIP
( persze nem volt tökéletes - de mégis szerintem az volt a csúcs. )
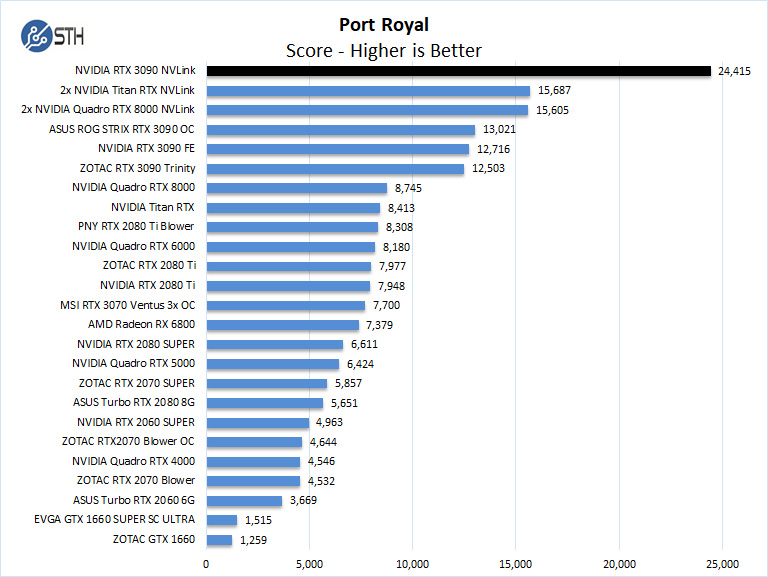 "NVIDIA has been slowly phasing out the consumer edge connector for this. However, one card in the lineup includes a NVLink edge connector, the RTX 3090."
"NVIDIA has been slowly phasing out the consumer edge connector for this. However, one card in the lineup includes a NVLink edge connector, the RTX 3090."
https://www.servethehome.com/dual-nvidia-geforce-rtx-3090-nvlink-performance-review-asus-zotac/4/ -

KRoy19
őstag
válasz
S_x96x_S
#50947
üzenetére
Hogy jönnek ide a budapesti ingatlanok?
Itt nem az a lényeg, hogy mennyibe kerülnek a VGA-k, hanem ,hogy az előző generációkban a 80-as class hol helyezkedett el spec/teljesítmény tekintetében az abszolút csúcshoz képest.
Nem egyszer volt már rá példa, hogy 2000+ dollár volt az abszolút csúcs, de arra még soha nem volt példa, hogy ekkora szakadék legyen teljesítmény/spec tekintetében a csúcs és a 80-as class között. Persze ez már a 4000-es szériánál is megfigyelhető volt, de az 5000-esnél még durvább. -
S_x96x_S
addikt
válasz
KRoy19
#50940
üzenetére
> Nincs itt fanyalgás, ezek nyers adatok
> és mindenki eldöntheti, hogy milyen konklúziót von le belőlük.a bázis nem mindegy
vagyis az - hogy mit veszünk alapnak az összehasonlításnál.(irona++) és ha meg akarsz lepődni, akkor a Budapesti Ingatlan Négyzetméter árakat vetitsd a csúcs 090 -GPU MSRP áraira.
És a nyers adatok szerint tuti, hogy több GPU-t tudsz venni;
És akkor vajon mi lesz a konkluzió> Szerintem itt is ugyan az a shrinkflation folyik mint bármelyik más piacon
inkább a verseny hiánya;
- Ha a Samsung és az Intel is jó chipeket tudna gyártani, akkor a TSMC árrése csökkene.
- és ha az AMD és az Intel - sokkal jobb GPU -kat készítene,
akkor az nVidia még gyorsabban veszítené el az árazási erejét.----- mert amúgy ...
"Nvidia Downgraded by HSBC as GPU Pricing Power Weakens"
https://www.gurufocus.com/news/2761999/nvidia-downgraded-by-hsbc-as-gpu-pricing-power-weakens"""
Top-rated analyst Frank Lee said Nvidia has seen strong momentum over the past two years, largely thanks to premium pricing on its AI GPUs. But that dynamic appears to be shifting. Lee pointed out that Nvidia's latest products — including the B300 GPU and GB300 rack system — aren't commanding significant price hikes over earlier versions.
He also flagged that the company's upcoming Vera Rubin system doesn't expand GPU count per rack, sticking with 72 units — the same as the current Blackwell system. Any increase won't come until Rubin Ultra arrives in 2027.
Due to these concerns, HSBC cut its price target on Nvidia from $175 to $120 and lowered both revenue and earnings estimates for fiscal 2026.
Still, Lee isn't walking away from the stock completely. He noted that longer-term opportunities in robotics and autonomous AI could eventually drive growth. But in the near term, Nvidia may face slower demand from cloud providers or a pause in large-scale AI orders from customers like DeepSeek.
""" -
válasz
KRoy19
#50945
üzenetére
igen lehet így is értelmezni de ahogy lenox értelmezte úgy is mert az 5080 fölé te tehetsz 30000 cudamagot is még bármekkora áron az xx80 akkor majd 30% lesz
Az xx80 ésxx70 kártyák mindegyik generációban 10.000 körüli cuda magszámmal mentek és a 70 -70Ti is és 3 generáció óta hasonló .
Bármelyik megközelítés lehet valid, mindegyiket el tudom fogadni,de én is hasonlóan látom alapjában véve mint ti, főleg az miatt mert bevezették az xx90 kártyákat pont ez miatt, hogy tudjanak csúsztatni a szinteken. -
gV
őstag
válasz
KRoy19
#50940
üzenetére
még ha csak 90g-ra fogyott volna... de csökkentették a kakaó tartalmát is
 -> nem veszem többé.
-> nem veszem többé.
_______Multiple Pre-built Gaming PCs Listed with "~$299" NVIDIA GeForce RTX 5060 Graphics Cards | TechPowerUp
ez még rendben, talán. igazából lehetett volna ennél is -$50. viszont ez:
NVIDIA GeForce RTX 5060 Ti 16 GB SKU Likely Launching at $499, According to Supply Chain Leak | TechPowerUp
mi a franc? $500? hahó nV $550 az 5070. $450 max. -
DudeHUN
senior tag
? De nem ez a lényege. Hanem, hogy arányaiban az elérhető képességéhez képest generációk óta kevesebbet kapsz a pénzedért. Ez a fogyasztó szemszögéből nem jó trend.
Persze itt is okohaltó a verseny és a többi túl jól menő ágazat. Egyrészt még mindig nagyobb teljesítményre képesek kb. azonos die méret esetén (tehát árazhatják és ponzícionálhatják magasabbra), plusz nekik már sokadlagos piac a desktop.
Viszont szóba kell ezt hozni és kell valami legalább minimális fék erre a trendre. Legalábbis (gondolom) nekünk az a jó, ha minél többet tudunk kisajtolni a pénzünkért. -
KRoy19
őstag
Nincs itt fanyalgás, ezek nyers adatok és mindenki eldöntheti, hogy milyen konklúziót von le belőlük.
Ha te elégedett vagy a fejlődés mértékével/milyenségével és a hozzá tartozó árazással, akkor tök jó, de nem kell mindenkinek azt gondolnia mint neked.Szerintem itt is ugyan az a shrinkflation folyik mint bármelyik más piacon, hogy fogják és eladják például a 90g-os csokit a régi 100g-os árán és örülünk, hogy nem lett drágább.
-
lenox
veterán
válasz
DudeHUN
#50938
üzenetére
Pl. mert abbol joval tobbet adnak el. De a 60-ashoz is lehetne. Mindenhol van szep elorelepes, azon fanyalogni, hogy a konzumer piacon alig par peldanyban eladott legnagyobb szeria nagyobbat lep elore, mint az atlag, szerintem hulyeseg. De persze ha a fanyalgas a crl, akkor ez is megteszi.
-
DudeHUN
senior tag
Miért hasonlítanád a 80-as szériához? Szerintem, ha már belekötünk a die méret alapján is nézhetnénk a dolgokat, mert az is ugrál generációnként.
Az is durva, hogy az Nvidia közel akkora chipet (nagyobb teljesítményt is tud azért) mennyivel drágábban adja, mint az AMD (9070XT vs RTX 5080). GDDR7 ide vagy oda. -
Yutani
nagyúr
A 3060 Ti-ből is 5080 lett (4070 Ti köztessel), és az ára is két és félszeresére nőtt. Az még csúnyább.
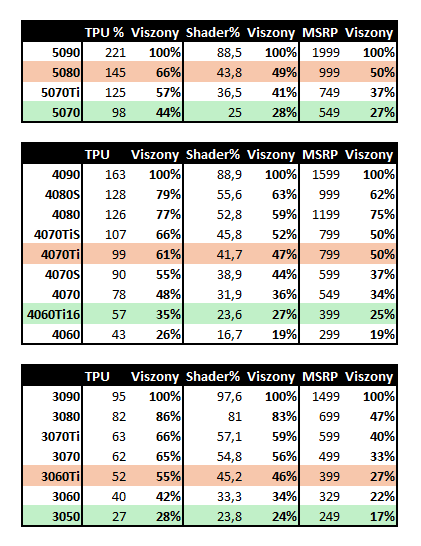
Itt az én ábrám, legutóbbi 5070 TPU 4k raszter alapján, a CUDA számok a x090 kártyákhoz arányítva (3090Ti kihagyva), és mellette az MSRP arányok.
Az megfigyelhető, hogy a sebesség nőtt generációról generációra hasonló CUDA szám mellett, de a kategóriák butításával megoldják, hogy a csúcsmodell egyre távolabb legyen teljesítményben az alatta lévőktől. Az 5080 második kártyaként most olyan távol van az 5090-től, mint korábban a 4070TiS a 4090-től. Ilyen csalással teszik indokolttá a csúcsmodell árát. Bravó Jensen, szép munka!
-
yarsley
aktív tag
Érzésre nem igazán egymáshoz árazták, csak az egekbe. 9070 XT-ből alig van készlet, szóval piszkosul nagy felárat mernek rá rakni a kereskedők. Viszont 9070-ből valamiért kaptunk nagyobb készletet több fajta gyártótól is, egyből megindult lefelé az ára. Míg két héttel ezelőtt igaz volt amit írtál most már van 2 kártya 310 alatt egy meg 300k alatt is.
Szerintem ugyan ez fog történni az Nvidia kártyákkal is HA tartósan érkezik a készlet.
-
-

Egon
nagyúr
-
#50922
 Komplikato
veterán
bitblueduck
#50921
Komplikato
veterán
bitblueduck
#50921
Komplikato
veterán
válasz
 bitblueduck
#50921
üzenetére
bitblueduck
#50921
üzenetére
Azért a 7600GT v2 még jobban odavert, volt olyan gyári darab ami 100% közeli tuninggal jött ki. Nem is nagyon ugrottak a népek a 7800-ra.
Na olyan refresh se lesz többé az életben. -
S_x96x_S
addikt
Inside Nvidia's GeForce 6000 Series
https://chipsandcheese.com/p/inside-nvidias-geforce-6000-series
"GeForce 6's pixel and vertex shader pipelines are more flexible than ever, and shows Nvidia is taking programmable shaders seriously. Many of the capabilities introduced in GeForce 6 may seem excessive for current gaming workloads."
-
S_x96x_S
addikt
válasz
yarsley
#50915
üzenetére
> Talán ha ezt fenntartja NVIDIA akkor nyárra lesznek MSRP áron is kártyák,
optimista vagy
- nyáron már mást értünk MSRP alatt;
- a gyártók már elkezdték a vám beépítését az árakba
- és sajnos az EU árakba is beépítik ( ~ szétterítik ) az árnövekedést; vagyis mi az EU-ban részben hozzájárulunk a gyártás átszervezésének a költségéhez."2025 Tariff Impacts at Puget Systems"
https://www.pugetsystems.com/blog/2025/03/28/2025-tariff-impacts-at-puget-systems/
"GPU & Accelerators: 10% price increase. This is the worst news in this post because these components have a high cost to begin with, so even a smaller percent increase means a bigger dollar increase! They are actually impacted by a 20% tariff, but we believe the market has already built in some cost increase in anticipation of tariff changes. We’ll reassess after 2-4 weeks. Further, the tariffs here have the potential to increase from 20% to 45% on June 1, but we hope that US policy changes between now and then will dampen that increase. Brace yourself for that potential!" -
yarsley
aktív tag
válasz
 $p@rr0w
#50903
üzenetére
$p@rr0w
#50903
üzenetére
Én nem nagyon reménykednék super refreshben, mert egyrészt már az elején mondták, hogy nem terveznek (illetve volt ilyen leak), másrészt tavaly azért kaptunk super refresht mert a sima kártyák nem fogytak. Nah idén nem lesz ilyen probléma, mert alacsony a készlet.
Minden egyes GPU-ra szánt wafferen "buknak", mert sokkal jobban megérné DC kártyákat gyártani, szóval jó esetben rászánnak annyi kapacitást hogy MSRP felett legyenek nem sokkal az árak, rosszabbik esetben meg marad a mostani alacsony készlet MSRP +30-40%-os árakkal.
Egyébként ugyan ez a helyzet AMD oldalon is, procikat vagy DC kártyákat nekik is sokkal jobban megéri gyártani... -
[Apple finally steps up AI game, reportedly orders around $1B worth of Nvidia GPUs]
Főleg így szükség lesz alternatívára... -
#50909
b.
félisten
deathcrow42
#50908
válasz
deathcrow42
#50908
üzenetére
Ha megnézed az elérhetőséget inkább 16-18 hónap lenne az optimistán nézve. Szerintem kb május végére, június elejére lesznek készletek most.
-
#50908
deathcrow42
őstag
b.
#50906
-
#50904
 Quadgame94
őstag
deathcrow42
#50902
Quadgame94
őstag
deathcrow42
#50902
Quadgame94
őstag
válasz
deathcrow42
#50902
üzenetére
Rubin biztos nem. Ez arch. ennyit tud. Árban, szegmentálásban tudnak hozni valamit és ennyi. Mondjuk még a mostani kártyák sem kaphatóak normális áron... szóval mit is várunk? Szerintem sokan elégedettek lennének a teljesítménnyel, itt az árakkal van gond.
-

$p@rr0w
őstag
Jó lenne ha igazad lenne, és telitődne a piac, levive az árakat, de szerintem csak a szokásos super változatok jönnek refresh jelleggel mint újdonság. Ha jön is új generáció az lesz mint a többi piacon: minimális előrelépés azonos áron és nem mintha a mostani 2 éves generációknál nagy ugrások lennének...
-
#50902
deathcrow42
őstag
b.
#50901
Szerintem nem fog, hanem hasonló tik-tok lesz, mint eddig. Most márciusban jelentették be a Blackwell Ultrát, így szerintem a gaming szegmensben is majd az év végén jön a "jóárasított" 5080 meg 5070, mint a négyes gen esetén. Mondjuk kérdés, hogy az 5080 chip az már kimaxolt, szal az 5080 meg az 5090 közé csak valami csökött ropcsökkentett 5090 jöhetne más névvel.
Tavaly áprilisban jelentették be a szerveroldali Blackwellt, idén jött a gaming Blackwell
Idén márciusban jelentették be a szerveroldali Blackwell ultrát... szerintünk mi jöhet vajon az év végén? -
válasz
$p@rr0w
#50900
üzenetére
Szerintem jövőre jön új Nvidia generáció, úgy értve ezt, hogy nem fog 2 év eltelni. A CPU bejelentéshez ősszel én kapcsolnék már valami tervet pletykát.
Az Intel ( ha valóban ők gyártják a gaming szériát) tökéletes lehet az MCM debütáláshoz. Persze sok a ha, és itt hozzátenném, ha valóban a gyártásuk ott tart amit írnak.












































![;]](http://cdn.rios.hu/dl/s/v1.gif)
















 -> nem veszem többé.
-> nem veszem többé.






 Szerintem nem bírod olyan kicsire törni a kártyát, hogy ne fájjon, ha akár a legkisebb darabját betuszkolják valamelyik testnyílásodba...
Szerintem nem bírod olyan kicsire törni a kártyát, hogy ne fájjon, ha akár a legkisebb darabját betuszkolják valamelyik testnyílásodba... 














Új hozzászólás Aktív témák
Hirdetés
A topikban az OFF és minden egyéb, nem a témához kapcsolódó hozzászólás gyártása TILOS!
MIELŐTT LINKELNÉL VAGY KÉRDEZNÉL, MINDIG OLVASS KICSIT VISSZA!!
A topik témája:
Az NVIDIA éppen érkező, vagy jövőbeni új grafikus processzorainak kivesézése, lehetőleg minél inkább szakmai keretek között maradva. Architektúra, esélylatolgatás, érdekességek, spekulációk, stb.


- IKEA Livboj vezetéknélküli mobiltöltő eladó
- REFURBISHED és ÚJ - Lenovo ThinkPad Ultra Docking Station (40AJ) dokkoló
- Xiaomi Redmi Note 10s 128GB, Kártyafüggetlen, 1 Év Garanciával
- 15,6" Dell Latitude laptopok: E6540, E5550, E5570, 5580, 5590, 5500, 5501, 5510/ SZÁMLA + GARANCIA
- Samsung Galaxy A23 128GB, Kártyafüggetlen, 1 Év Garanciával
Állásajánlatok

Cég: Laptopszaki Kft.
Város: Budapest

Cég: PCMENTOR SZERVIZ KFT.
Város: Budapest