-

IT café
A legtöbb kérdésre (igen, talán arra is amit éppen feltenni készülsz) már jó eséllyel megtalálható a válasz valahol a topikban. Mielőtt írnál, lapozz vagy tekerj kicsit visszább, és/vagy használd bátran a keresőt a kérdésed kulcsszavaival!

Új hozzászólás Aktív témák
-
válasz
 paprobert
#24540
üzenetére
paprobert
#24540
üzenetére
Én arra gondolok, hogy a 20 TFLOPS -ha igaz lesz- valami dual, vagy quadro GPU ból fog állni,így nem lesz nehéz nekik esetleg a 10 TFLOPS vagy az alatti terület lefedése.
nehezen hiszem el a 20 TFLOPS teljesítményt egy GPU val.[ Szerkesztve ]
"A számítógépek hasznavehetetlenek. Csak válaszokat tudnak adni." (Pablo Picasso) "Never underrate your Jensen." (kopite7kimi)
-
válasz
paprobert
#24574
üzenetére
A lényeget leírtam helyette

Időközben megjött a hivatalos Nvidia driver amivel elérhető az RT pascalokon is.[link]
letölthető hozzá az UE4 techdemo is , összesen 3 darab techdemo.[link]
Összesen 9 GB a 3 demó.GTX 1070 nel, hát hogy is mondjam...
[ Szerkesztve ]
"A számítógépek hasznavehetetlenek. Csak válaszokat tudnak adni." (Pablo Picasso) "Never underrate your Jensen." (kopite7kimi)
-
válasz
paprobert
#25038
üzenetére
jah nem erőltették meg magukat

DE a fényes borítás nekem tetszik ahogy írták is feljebb, a Quadro dizájnját próbálják rávinni a REF kártyákra.
[ Szerkesztve ]
"A számítógépek hasznavehetetlenek. Csak válaszokat tudnak adni." (Pablo Picasso) "Never underrate your Jensen." (kopite7kimi)
-

Abu85
HÁZIGAZDA
válasz
paprobert
#26073
üzenetére
A 240 Hz-nek sem az a lényege, hogy jól meg tudja csinálni a kijelző, hanem hogy papíron rá lehessen írni. 120/144 Hz fölött nincs akkora haszna ennek, mint amennyi problémát behoz a panel hiányosságai miatt. De a lényeg, hogy papírja legyen a 240 Hz-ről, mert a gémerek így hajlandók többet adni érte. Azért senki sem fizetne többet, ha azt írnák rá, hogy 240 Hz, de kapod a jókora over/undershootot, majd ha ezeket valahogy próbálod kezelni, akkor jön a haloing, stb. Ez majd akkor kiderül, ha kipróbálod.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
válasz
paprobert
#26220
üzenetére
Egyetértek veled.
sajnos a piac azt üzente nvidianak, hogy kisebb előny már elég lehet ahhoz hogy drágábban több kártyát adjanak el, lásd 1070Ti VS Vega vagy most a Super széria.
Egyebkent nem volt nekik a Turing olcsó gyártású, mert totál elvittek TSMC tol és atalakitattak saját maguknak gyartosorokat. Ugye itt volt a szennyeződés. Nekik talán az volt a lényeg, hogy ekkora méretben jó legyen a kihozatal.Szerintem meg merik kockáztatni de bármi lehetséges amúgy.
[ Szerkesztve ]
"A számítógépek hasznavehetetlenek. Csak válaszokat tudnak adni." (Pablo Picasso) "Never underrate your Jensen." (kopite7kimi)
-

Jack@l
veterán
válasz
paprobert
#26220
üzenetére
Mire kijön, addigra már rég nem a 2 éves kártyával kell versenyre kelniük.
A hozzászólási jogosultságodat 2 hónap időtartamra korlátoztuk (1 hsz / 10 nap) a következő ok miatt: Az ÁSZF III 10/8. pontjának megsértése - trollkodás - miatt. Többször és többen is kértek már, hogy hozzászólás írásakor használd a linkelés funkciót, mert ennek elmaradása sokak számára zavaró.
-

GeryFlash
veterán
válasz
paprobert
#26715
üzenetére
Az első időkben sehol nem lesz +50%-os csúcskártya konzolhoz kéepst. Vagy ha úgy érted hogy számítás teljesítményben akkor igen, de tippre ha a két új generáció hoz is az előzőhöz képest +50%-ot akkor se fogják azt hozni azt a minőséget 4K 60FPS-ben mint a konzolok. Mondjuk baj is lenne ha dayOne konzolgeneráció legelején tudná azt PC hardver mint a konzol.
Mármint ez nem a konzolosoknak baj hanem en bloc mindenkinek aki a következő 7 évben egyre szebb játékot szeretne látni, remélhetőleg most nem az lesz mint a jelenlegi érában, hogy a konzol nyitócímek és a konzol generáció végeikben nagy grafikai különbség nincs. Miközben az ezt megelőző konzoloknál mindig volt generáció közbeni fejlődés.Hi, i'm new to APHEX TWIN, so i was wondering how much the IQ requirements was to enjoy his stuff. and understand all the underlying themes, because its really complex stuff. I have IQ of 119 but i heard that you need atleast 120 is it true?
-
#26785
 huskydog17
addikt
paprobert
#26771
huskydog17
addikt
paprobert
#26771
válasz
paprobert
#26771
üzenetére
Igen, legalábbis egyelőre ez a terv.
"At the moment we don’t benefit from any additional performance that modern APIs like Vulkan or DX12 or dedicated hardware like the latest generation of graphics cards could give us. But of course, we will optimize the feature to achieve an uplift performance from these APIs and graphics cards. "
Gameplay csatornám: https://www.youtube.com/channel/UCG_2-vD7BIJf56R14CU4iuQ
-

paprobert
senior tag
válasz
paprobert
#26951
üzenetére
Illetve hozzátenném, hogy a 7nm már másfél éves, és az Nvidia nem a második nagy cég aki tömeggyártat rajta (mint az AMD volt anno), hanem a sorban már a sokadik.
Tehát a node-dal való kollektív tapasztalata az egész félvezetőiparnak sokkal nagyobb, nem kevés elérhető és szabadon igazolható mérnökkel akik meg tudják kímélni a céget a bukdácsolástól, emiatt lehet bátrabbnak lenni.
[ Szerkesztve ]
640 KB mindenre elég. - Steve Jobs
-
válasz
paprobert
#27306
üzenetére
Nem erre gondolok, konkrétan az NVIDIA panaszkodott. Valószínűnek tartom, hogy az árazásba beleálmodták, hogy az emberek zabálni fogják az RTX-et, közben meg a többség ár / teljesítmény alapon értékelte a kártyákat, és kevesellte a 15-20%-os előrelépést.
Elég beszédes amúgy, hogy míg az RTX 2080 MSRP-je 699 USD volt, a GTX 1080-é pedig 599 USD, cca. 2 hónappal az indulás után Németországban mind a custom 2080-ak, mind a custom 1080-ak hasonló áron voltak elérhetők (650-700 EUR között, ha jól emlékszem).
Pedro... amigo mio... ma is konzervvért iszunk! Kár lenne ezért a tehetséges gyerekért...
-
válasz
paprobert
#27308
üzenetére
Értem, miért merül fel benned a gondolat, de ezzel most nem értek egyet. Pont a S széria az egyik indikáció arra, hogy az eredeti árak túl magasak voltak. A 2060S szinte egy az egyben a 2070 - jóárasítva, de úgy, hogy közben nem kellett semmit leárazni.
Pedro... amigo mio... ma is konzervvért iszunk! Kár lenne ezért a tehetséges gyerekért...
-
Abu85
HÁZIGAZDA
válasz
paprobert
#27335
üzenetére
Van egy maximális fogyasztási limit, de a PlayStation 5 speciel hamarabb ütközik bele a belső buszrendszer clock limitjébe. Azért is 2,23 GHz a beállított órajel, mert a Sony konzolja még az első generációs RDNA kicsit módosított buszrendszerét használja, és nem az újhoz tervezettet. Ennyi részegységre ez is elég, de nem tud ennél magasabb órajelen működni. Maguk a multiprocesszorok képesek lennének többre is, az RDNA2 mintákon a clock limit 2,7 GHz. Ez a Navi 10-nél 2,1 GHz volt.
(#27336) lenox: Valahogy ki kell verni a bullshitet az emberek fejéből.
Maga az AMD AVFS rendszere nem definiál alapórajelet. Nincs szüksége rá. A régebbi AVFS esetében egy PowerTune órajel volt definiálva, és onnan számolt mindent. Az RDNA-nál csak egy DPM limit van a BIOS-ban az órajelre, és abból van számolva minden. Plusz meg van adva egy úgynevezett clock limit, ami például a Navi 10-es GPU-knál 2,1 GHz. Ez a felső limitje annak, amire maga a hardver elméletben képes, de különböző okok miatt sosem tudja beállítani. Ez arra szolgál, hogy a rendszer túl tudja lépni magát a DPM limitet is, vagyis hiába van maximum órajelnek 1755 MHz ráírva a Radeon RX 5700 XT-re, egyszerűen lehetnek olyan alkalmazások, ahol beállít 1800 MHz-et, amíg a clock limitet nem lépi át. A különbség az, hogy amíg a DPM limiten belül marad az órajel, addig a hardver szabadon dönthet arról, hogy mi a következő 1 ezredmásodperces DPM ciklus órajele, míg a DPM limitet túllépve muszáj a DPM limit maximumát beállítani a következő 1 ezredmásodpercre, ahonnan a hardver megint szabadon dönthet.
Régen volt olyan, hogy voltak definiált állapotok. Úgynevezett DPM lépcsők, és azok között ugrált a hardver. Ezek a szintek konkrétan bele voltak írva a BIOS-ba.
Például ezek a Vega 10 DPM lépcsői: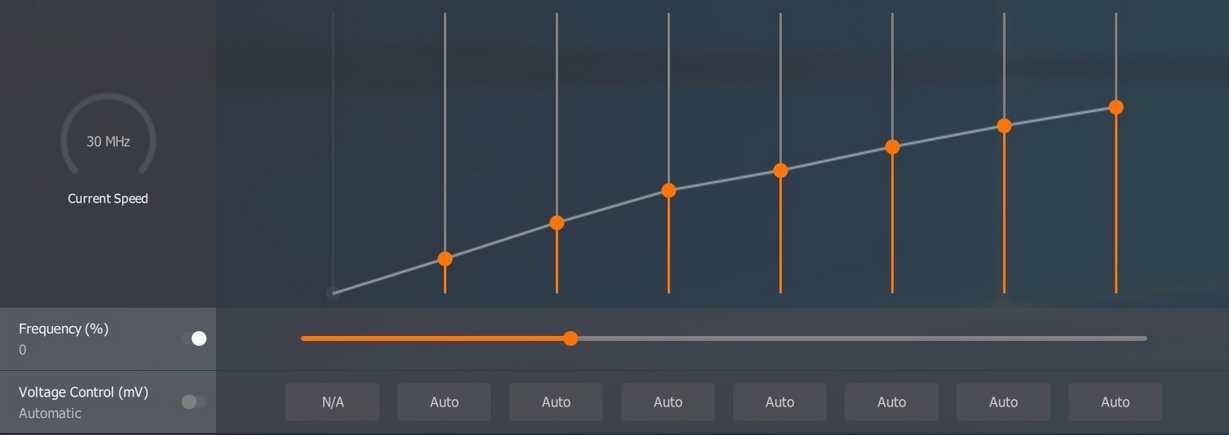
A Vega 20-tól került bevezetésre a legforróbb pont meghatározásra, és azzal, hogy az AMD ezt már konkrétan ki tudja olvasni, át is álltak a finomszemcsés DPM mechanizmusra.
Ez a Navi 10 görbéje erre vonatkozóan: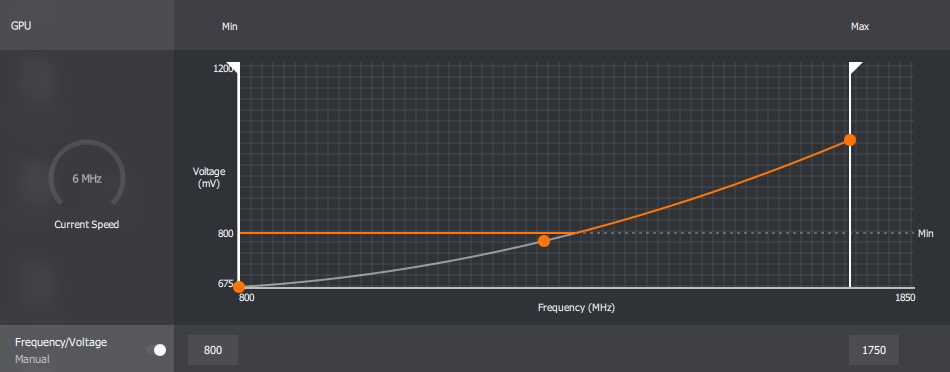
Itt vált ez az egész bonyolulttá, mert a finomszemcsés DPM mechanizmussal nincsenek előre meghatározott állapotok, mindent a hardver számol ki valós időben. Ez tette lehetővé azt is, hogy ne csak a hőmérsékletre legyen ilyen számítás, hanem terhelésre is. A különbség annyi, hogy amíg a PC-s dizájnokban az AMD hőtérképet számol, addig a PlayStation 5-ben terheléstérképet.[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
válasz
paprobert
#27340
üzenetére
Ez egy specifikus eset. Egyik konzol sem az az RDNA2, amit jön PC-be. Az egyes részegységek azok, de a buszrendszer, ami összeköti a CU-kat még az első RDNA-ból származik. Ennek az előnye, hogy eleve kész volt, tehát csak használni kellett, illetve bőven kibír annyi multiprocesszort, amennyi a konzolokba került. A hátránya, hogy nem visel el ~2,23 GHz körülinél nagyobb órajelet. Az új buszrendszer, ami az RDNA2-ben jön már bőven elvisel. Emiatt ez a korlát a PS5-nél.
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
válasz
paprobert
#27740
üzenetére
Nvidia az utóbi 3 genben a gyártástechnológiát is módosította a kártyáik architektúráihoz. Mindenhol külön módosított gyártósort kaptak, de a Turing volt a legegyedibb,ahol külön csíkszélt is kaptak hozzá, csak ők gyártottak rajt.
A kisebb Pascal a Samsungnál egy továbbfejlesztett csíkszélen készült egyedi paraméterekkel a GTX kártyákhoz.
Biztos vagyok benne, hogy ez most is így lesz, sok szempontból hozni fogják vagy meg is haladják a 7 nm általános dizájn elemeit. A pletykált 320-350 wattos TDP ami valójában TGP egy pletykára alapul szintén,de ugyan ez a pletyka írja azt hogy ismét 700mm2 fölött lesz a csúcs GPu ami azt jelenti, hogy a 12nm-n készített Turinghoz nézve kb 1000 mm2 lenne ugyan azon a gyártáson az Ampere.
Van sok tényező amit nem tudunk, szerintem lesznek meglepetések az Ampereben amiről majd csak a megjelenés napján foguk tudni.
Én arra tippelek hogy a kisebb kártyák lesznek Samsungnál a nagyobbak TSMC nél.
Erre utalhatott az a pletyka hónapokkal ezelőtt, hogy a felső kategória nem lesz olcsóbb, de az alsóbbak valószínűleg igen.[ Szerkesztve ]
"A számítógépek hasznavehetetlenek. Csak válaszokat tudnak adni." (Pablo Picasso) "Never underrate your Jensen." (kopite7kimi)
-

poci76
aktív tag
-
-
#27892
 Petykemano
veterán
paprobert
#27890
Petykemano
veterán
paprobert
#27890
Petykemano
veterán
válasz
paprobert
#27890
üzenetére
Az, hogy az AMD-nek 3-4 iteráció kellett ,de jobb szakemberekkel...
Abban nem vagyok biztos, hogy az nvidia nem foglalkozott-e már a kezdetektől, mondjuk pont ugyanakkortól a 7nm-rel, mint az AMD. Ugyanúgy tanulhatták az elmúlt 2-3 évben, függetlenül attól, hogy hogy az AMD-hez hasonlóan nem csináltak belőle tömeggyártott terméket. Nem?
Végülis valami alapján már évekkel ezelőtt el kellett dönteni, hogy hol gyártanak.máskülönben meg azt se tartom valószínűnek, hogy azt a tudást, hogy hogy kell egy adott node-on gyártani az AMD vagy bárki más meg tudná tartani kizárólag magának. a TSMC (vagy a samsung) is érdekelt ennek a tudásnak a megszerzésében a librarykba való beépítésében és más bértártyókkal való versengés során más megrendelőknek kínálni.
Magyarul lehet, hogy az AMD szerencsétlenkedett 2 évet a 7nm-rel, de az ott szerzett tapasztalatot a TSMC-nek is érdeke megszerezni és felkínálni például nvidiának, emiatt nem biztos, hogy az nvidia "ma" onnan indul, ahol az AMD 2 éve.
Találgatunk, aztán majd úgyis kiderül..
-
Abu85
HÁZIGAZDA
válasz
paprobert
#27890
üzenetére
Az A100 egy másik dizájn. Itt dizájnokat portolsz. Az architektúra nem ér semmit, mert az még önmagában nem fizikai dizájn.
Senki sem hoz ki hamarabb semmit ezekből a node-okból. Amiért nem látod a fejlődést máshol, az amiatt van, hogy sokan eleve egyszerűbb áramköröket terveznek, vagy a mobil SoC esetében egyszerűen Artisan IP-t licenecnek, tehát eleve úgy kérik a magot, hogy fizikailag kész a dizájn az adott node-ra, és nem ők tervezik le. Ezekben is van elméletben tartalék, csak senki sem érdekelt abban, hogy kihozzák azokat.
Ugyanez megfigyelhető az Intelnél is a 14 nm+++++++++++++++++++++++++-szal. Évről-évre találnak tartalékot, mert évről-évre egyre inkább megismerik.A TSMC-nél licit van a kapacitásra. Az nyer, aki a legtöbbet fizeti. Lehet tenni alacsony összegű ajánlatokat, de ki nem szarja le, ha a többiek meg rálicitálnak.
(#27892) Petykemano: A tömeggyártás a kulcsa annak, hogy megértsd egy node viselkedését, mert csak akkor szembesülsz a variancia problémájának nagyságával.
Az a tudás, hogy hogyan lehet egy node-on jól gyártani bele van kódolva a dizájnkönyvtárakba. Tehát elmehetnek a mérnökök ide-oda, de a dizájnkönyvtárat nem tudják magukkal vinni. Főleg amiatt, mert mindenki más szoftveres hátteret használ, tehát a tudásuk hasztalan, mert csak arra az egy dizájnkönyvtárra vonatkozik, amely csak az adott cég terveivel működik. Ezt sajnos mindenkinek magának kell kitapasztalnia, ha vásárolható lenne, akkor ezzel kereskednének a cégek, mert bizony igen komoly áron el lehetne adni ezt a tudást.
A TSMC fel tudja kínálni azt a tapasztalatot az NV-nek, de ahhoz, hogy kezdjenek is vele valamit az NV licencelni kell az AMD IP-it, és az AMD dizájnkönyvtárait. Ezek nélkül az AMD specifikus tapasztalata semmit sem ér, azok ugyanis nem az NV dizájn- és szoftverkörnyezetére, illetve IP-ire vannak szabva.[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
válasz
paprobert
#27902
üzenetére
Nem ilyen egyszerű. Az NV-nek is ugyanúgy, ahogy ma már elég sok cégnek kétféle dizájnkönyvtára van. Régen csak egy volt, de a Volta óta van egy teljesítményoptimalizált, illetve egy sűrűségoptimalizált. Korábban csak utóbbi volt, de előbbit a tensor magok miatt érdemes volt bevezetni, mert ott eleve eléggé egyszerű maga az áramkör, így többet nyersz egy teljesítményoptimalizált dizájnkönyvtárral. Már pusztán az áramkörök jellege miatt sűrűn lehet elhelyezni a tranyókat. Na most ezeket a döntéseket végigviszed az egész lapkára. Tehát amíg egy A100-at igenis van értelme teljesítményoptimalizáltra tervezni, addig egy tensor magokkal jóval kevésbé kitömött GPU-t már nem, oda a sűrűségoptimalizált dizájnkönyvtár az ideális.
Ugyanez létezik az AMD-nél is, bár ott annyi a különbség, hogy az AMD-nek vannak mixed optimalizálásai, vagyis egy lapkán belül is tudnak két eltérő könyvtárral tervezni, de nem úgy, hogy kis részleteket ezzel, míg a többit azzal csinálják, hanem itt nagy lapkaterületeket tudnak csak máshogy kidolgozni. Például a Renoir esetében az egész IGP teljesítményoptimalizált (kivéve a fixfunkciós blokkokat), míg a többi elem sűrűségoptimalizált. De amúgy teljes GPU-ra, vagy teljes CPU-ra, csak az egyiket szokták használni.Ezek a dolgok mind komolyan nehezítik ezt a gyorsan elhozom a x bérgyártótól, és leportolom seperc alatt y-ra ötletelést.
(#27903) hokuszpk: Lopni lophatnak a gyártók egymástól, csak szart sem érnek el vele. Eleve licenchez vannak kötve az egyes szellemi tulajdonok, másrészt sok ezek közül nem is hasznosítható egy eltérő lapkában.
Az Inteltől semmit hasznosat sem tudtak magukkal vinni a mérnökök a TSMC-hez. Egyszerűen csak a nyers tudásuk miatt hasznosak. Persze elmondhatták a TSMC-nek, hogy az Intel mit hogyan csinál 14 nm-en, de kb. annyi lehet erre a reakció, hogy "ezzel az infóval mit kezdjenek"? Hasznosítani nem lehet.Az Intel-TSMC viszonya egyébként azért tűnik extrémnek, mert a TSMC-nek az utóbbi években minden bejött, míg az Intelnek semmi sem. De a TSMC-nek főleg azért jön be minden, mert a fejlesztéseknél minimális kockázatot vállalnak. Látható, hogy a GAAFET-re is a Samsung megy elsőként, míg a TSMC a 3 nm-re inkább marad FinFET-en. Ez egyszerűen kockázatminimalizálás. Ilyen formában sokkal nehezebb lyukra futni, míg a Samsung simán taknyolhat egyet, mert kockázatos lépést csinálnak. De ha mondjuk betalálnak, akkor meg a Samsungot fogja dicsőíteni mindenki, hogy végre odapakoltak.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Jack@l
veterán
válasz
paprobert
#28298
üzenetére
A FET elrendezést védik sztem. Esetleg valami uj hw-es encoder csip a világos.
[ Szerkesztve ]
A hozzászólási jogosultságodat 2 hónap időtartamra korlátoztuk (1 hsz / 10 nap) a következő ok miatt: Az ÁSZF III 10/8. pontjának megsértése - trollkodás - miatt. Többször és többen is kértek már, hogy hozzászólás írásakor használd a linkelés funkciót, mert ennek elmaradása sokak számára zavaró.
-
válasz
paprobert
#28535
üzenetére
nem tartom kizártnak ezt a coprocesszort, tehát végső soron az is egyfajta nem hagyományos duál GPU lenne, lehet az is egy lehetséges magyarázat.
[ Szerkesztve ]
"A számítógépek hasznavehetetlenek. Csak válaszokat tudnak adni." (Pablo Picasso) "Never underrate your Jensen." (kopite7kimi)
-
Jack@l
veterán
válasz
paprobert
#28583
üzenetére
Horizon Zero Dawn nem éppen az optimalizáltság példaképe. Inkubb bug az hogy jobban fut kiszemelt amd-s párosításssal, mint feature.
@proci: de mi lesz ami erdemben jobban megjaratja a buszt? Mert ahol arra kell alpozni, hogy minden framenel masszivan adatot mozgasson rajta, ott mar nagy baj van. Az amd vesszosparipaja mostanaban hogy majd ezzel megvaltjak a vilagot, de a kesleltetes ugyanugy ratyi hozza, hiaba a dupla savszel. Figyeld meg hogz 1 evig a fopap ezzel fog haknizni, aytan amikor kiderul a zsakutca, abbamarad a tamtam. HBC is addig volt szuper elkepzeles ameddig ki nem jottek a tobb vramot hasznalo jatekok. Csak elotte amd is szepen csendben a tobb vram fele lepett, nehogz kideruljon hogy 4gb-al nem tul user frendly 8gb-ra keszitett jatekot futtatni.
[ Szerkesztve ]
A hozzászólási jogosultságodat 2 hónap időtartamra korlátoztuk (1 hsz / 10 nap) a következő ok miatt: Az ÁSZF III 10/8. pontjának megsértése - trollkodás - miatt. Többször és többen is kértek már, hogy hozzászólás írásakor használd a linkelés funkciót, mert ennek elmaradása sokak számára zavaró.
-

Chalez
őstag
válasz
paprobert
#28699
üzenetére
Köszi. Szerencsére ws 1080p/144-re kell, szóval akár max a 3070 is elég lehet... kompromisszumokkal. Az biztos, h. 250k a max amit vga-ra kiadok, de még az is kicsit ingerküszöb feletti
CP2077 60FPS+ a cél, abba a játékba a várakozások szerint párszáz órát majd beleölök. -
paprobert
senior tag
válasz
paprobert
#28826
üzenetére
Kifutottam az időből.
Valamint az AMD megoldása 30%-kal kisebb footprintű úgy, hogy tartalmaz multimédiás egységeket is, természetesen ~50W előnnyel az A100-hoz képest.
Szkeptikus vagyok, gyakorlatilag nincs olyan paraméter, ami nem olyannak tűnik mintha az AdoredTV rakta volna össze ezt az egyenletet.
640 KB mindenre elég. - Steve Jobs
-
Abu85
HÁZIGAZDA
válasz
paprobert
#28826
üzenetére
De az A100 tele van egy rakás, játék szempontjából teljesen hasztalan részegységgel. A Navi 21 általánosabban van tervezve.
(#28828) Yutani: Tolómérővel mérve ~510 mm2. Máshol is azt mondták, hogy 500 mm2 fölött van picivel.
(#28829) arn: Azért távolról sem a ~350 wattos TGP-t szoktuk meg.
(#28831) sutyi^: Olyan túl sokat most nem lehet méregetni. Van TFLOPS és TGP adat, ami sokra nem elég. De abból főznek a pletykagyárak, ami van.
(#28832) arn: Az Ampere esetében azért sosem volt panasz a teljesítményre. Tehát lehet hallani, hogy nagyon zabál, és kibaszottul süt (főleg a memóriák, azok 120°C-on mennek), de a tempója az rendben van. Szóval előrelépés úgy néz ki, hogy lesz bőven, csak magas lesz az ára wattok és a celsius-fokok tekintetében. Meg gondolom azért az árcédulára is rendesen odafirkantanak majd.
![;]](//cdn.rios.hu/dl/s/v1.gif)
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Chalez
őstag
válasz
paprobert
#28930
üzenetére
Nahh, bennem is ez motoszkált, h elvileg konzolgeneráció váltás lesz, most az új vga-knak arányaiban nagyobbat kellene villantani teljesítményben, és aránylag visszafogott árazást kell produkálniuk, mert különben a pc-sek fennmaradó részéből rengetegen térhetnek át, és húznak be egy ps5-öt, v egy xbox sx-et inkább, mint 400-600-x $-t kiadjanak csak egy komponensre...
[ Szerkesztve ]
-
#29774
 egyedülülő
őstag
paprobert
#29760
egyedülülő
őstag
paprobert
#29760
egyedülülő
őstag
válasz
paprobert
#29760
üzenetére
A 2070 Superek most kerülnek ennyibe, a gen végén. A custom hűtésüek meg alapból drágábbak.
Én azt mondom a hosszabb távra beállt ár olyan 220e körül lesz a 3070 esetében."Ha lenéznénk az űrből a földre, nem látnánk az országhatárokat. Csak egyetlen kis bolygót látnánk."
-

Motyi
senior tag
válasz
paprobert
#29769
üzenetére
Lehet már nem így van, de IT cuccoknál nem úgy van az árazás, hogy ami USA-ban 1 USD az Európában 1 EUR (pl. konzoloknál így van)? Azaz a 699 USD-s 3080 az inkább 699 EUR? Mert úgy látom Te az USD árakkal + 27% áfa számoltál.
Szerintem inkább így néznek majd ki az AIB árak (gondolom nVidia továbbra sem szállít hazánkba):
RTX3090: 660-670eFt
RTX3080: 310-320eFt
RTX3070: 220-230eFtHa nem így kell számolni ne kövezzetek meg.
-

Z10N
veterán
válasz
paprobert
#29895
üzenetére
Igy van
 Vegre valami fejlodes a sok evnyi stagnalas es banyasz spekulacio utan.
Vegre valami fejlodes a sok evnyi stagnalas es banyasz spekulacio utan.
Ezzel az AMD-nek is villantania kell valamit, kulonben konzolt vagy Nv-t vesznek a nepek.
Bar a konzollal nem jarnak rosszul. De ego, hogy a zakatolo cpu reszleg mellett kullog a gpu.# sshnuke 10.2.2.2 -rootpw="Z10N0101"




























![;]](http://cdn.rios.hu/dl/s/v1.gif)







Új hozzászólás Aktív témák
A topikban az OFF és minden egyéb, nem a témához kapcsolódó hozzászólás gyártása TILOS!
MIELŐTT LINKELNÉL VAGY KÉRDEZNÉL, MINDIG OLVASS KICSIT VISSZA!!
A topik témája:
Az NVIDIA éppen érkező, vagy jövőbeni új grafikus processzorainak kivesézése, lehetőleg minél inkább szakmai keretek között maradva. Architektúra, esélylatolgatás, érdekességek, spekulációk, stb.

- WoW avagy World of Warcraft -=MMORPG=-
- Linux kezdőknek
- NVIDIA GeForce RTX 3080 / 3090 / Ti (GA102)
- Mini-ITX
- 3DMark (2013) eredmények
- VR topik (Oculus Rift, stb.)
- Háztartási gépek
- Spórolós topik
- Ismerős külsővel érkezik a Polestar telefon
- AI-gyártású celebpornóval küzd a Facebook
- További aktív témák...
