-

IT café
A legtöbb kérdésre (igen, talán arra is amit éppen feltenni készülsz) már jó eséllyel megtalálható a válasz valahol a topikban. Mielőtt írnál, lapozz vagy tekerj kicsit visszább, és/vagy használd bátran a keresőt a kérdésed kulcsszavaival!

Új hozzászólás Aktív témák
-
válasz
 Busterftw
#41949
üzenetére
Busterftw
#41949
üzenetére
Nekem gyanús, hogy kifejezetten az AI gyorsítókról beszélnek. Esélyesen ez a HBM3-as AI gyorsító lesz, a consumer kártyákat pedig talonba rakják.
Mivel sem az AMD, sem az Intel nem veszélyezteti őket, így gyártókapacitást simán teljesen az AI szegmensre áldozhatják.
Én csodálkoznék, ha a consumer Blackwell 2024-ben kijönne... Egy Ada szériás Super széria jön és szépen tovább szalámizza a gamer dVGA piacot...[ Szerkesztve ]
Légvédelmisek mottója: Lődd le mind! Majd a földön szétválogatjuk.
-

Raymond
félisten
"Nekem gyanús, hogy kifejezetten az AI gyorsítókról beszélnek."
Termeszetesen arrol. A problema meg honapokkal ezelott keletkezett (vagy tavaly ev vegen?) amikor a mainstream sajto is felkapta az AI-t es akkor valaki(k) ezekre elkezdtek a "GPU"-t mind jelzot hasznalni es ez azota is igy van. Aztan most eloszor meg kell nezni egy cikknel hogy kitol/honnan van es milyen temahoz van kozelebb (finance vagy tech) es abbol kiindulva van meg az hogy mirol is beszelnek. A szalagcimek ezeknel a hireknel es cikkeknel csak a zavart keltik.Privat velemeny - keretik nem megkovezni...
-
-
válasz
Busterftw
#41955
üzenetére
Teljesen más architektúra az egész, ebből a szempontból nem releváns, de szerintem nem erre gondoltál.
Ami talán érdekes lehet nekünk, ha a Chiplet bemutatkozik abból a szempontból ahogy Nvidia elképzeli, ami eltér az AMD féle megvalósítástól . Valamint nagyon örülnék, ha a pletykált hibrid memória menedzsmentet is láthatnánk, mert az elég sok dolgon tudna változtatni.[ Szerkesztve ]
"A számítógépek hasznavehetetlenek. Csak válaszokat tudnak adni." (Pablo Picasso) "Never underrate your Jensen." (kopite7kimi)
-
Hopp.
[NVIDIA introduces System Memory Fallback feature for Stable Diffusion]
Az új driverben benne is van. Gyors rendszermemória előnyben"A számítógépek hasznavehetetlenek. Csak válaszokat tudnak adni." (Pablo Picasso) "Never underrate your Jensen." (kopite7kimi)
-
#41962
Raymond
félisten
gainwardgs
#41961
Raymond
félisten
válasz
 gainwardgs
#41961
üzenetére
gainwardgs
#41961
üzenetére
Ez nem VRAM problema megoldasa
 Egy specifikus problemara egy megoldas, ott van a hirben is:
Egy specifikus problemara egy megoldas, ott van a hirben is:From a technical perspective, users have the flexibility to employ this feature for any application, including games. However, it may not be the best choice, as system memory is often notably slower than GPU memory, not to mention the necessary data transfer between the two.
The primary purpose of this feature is to avert potential crashes on graphics cards equipped with 6GB memory capacity. With the latest drivers, NVIDIA has thoughtfully incorporated an option to disable this fallback mechanism. Doing so can potentially enhance performance stability but does reintroduce the risk of depleting GPU memory.
How to enable or disable System Memory Fallback
1. Open NVIDIA Control Panel
2. Under 3D Settings, click Manage 3D Settings
3. Navigate to Program Settings tab
4. Select Stable Diffusion python executable from dropdown
5. Click on CUDA – Sysmem Fallback Policy and select Driver Default, Prefer No Sysmem Fallback or Prefer Sysmem Fallback.
6. Click Apply to confirm.
7. Restart Stable Diffusion if it’s already open.Tehat arra van amire a hir cime is utal.
Privat velemeny - keretik nem megkovezni...
-
#41963
 b.
félisten
gainwardgs
#41961
b.
félisten
gainwardgs
#41961
válasz
gainwardgs
#41961
üzenetére
Vram kérdést?

[ Szerkesztve ]
"A számítógépek hasznavehetetlenek. Csak válaszokat tudnak adni." (Pablo Picasso) "Never underrate your Jensen." (kopite7kimi)
-
#41964
 hokuszpk
nagyúr
gainwardgs
#41961
hokuszpk
nagyúr
gainwardgs
#41961
hokuszpk
nagyúr
válasz
gainwardgs
#41961
üzenetére
ez inkabb amolyan Vega fele HBCC for NV
![;]](//cdn.rios.hu/dl/s/v1.gif)
Első AMD-m - a 65-ös - a seregben volt...
-
#41966
Raymond
félisten
gainwardgs
#41965
Raymond
félisten
válasz
gainwardgs
#41965
üzenetére
Akkor lehet inkabb ezt a zold smiley-t kellett volna hasznalni ott is

Privat velemeny - keretik nem megkovezni...
-

Abu85
HÁZIGAZDA
Ja hát igen... látták a kristálygömbben, és így biztos igaz...

Igen, de nem azért, mert anyagilag megéri, hanem azért, mert a Cellt nem vitték tovább, az NV-vel pedig nem voltak megelégedve, ami persze a saját hülyeségük is volt, mert nyilván az NV csak egy tartalék termékkel dobta be magát a PS3-ba.
Viszont a PS4/XO váltásnál mindkét vállalat maradt az AMD-nél. Az oka szimplán annyi, hogy sok tízmillió sornyi kód van rájuk építve, így ha lerakják a megrendelt terméket, akkor az elég jó ahhoz, hogy ne fizessék meg a kód átírását. Egyszerűen utóbbi sokkal-sokkal drágább a gyártó oldalán. Ettől lehet váltani, csak a Sony és a Microsoft számára az orbitális költség lesz, amit vissza kell majd termelni a konzol életciklusa alatt. Üzletileg sokkal előnyösebb az olcsó irányt választani. A konzol ettől ugyanúgy eladható, és hamarabb fog hasznot termelni.
Az AWS-ben az Amazon saját terméke van. De hányan veszik az ARM szervereket kívülről? Ott már közel sem túl kellemes a helyzet, már a Marvell is ráállt a semi-customre, mert egyszerűen nem tudnak annyi ARM processzort eladni ide, hogy megérje ilyeneket fejleszteni. Ez van... túl sok még a legacy kód. Majd 5-6 év múlva talán.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
#41968
 Quadgame94
senior tag
Quadgame94
senior tag
Quadgame94
senior tag
BLACKWELL - GB102
Én azt gondolom a Blackwell egy vízválasztó lehet abban a tekintetben, hogy merre megy tovább az NVIDIA. Az teljesen jól látszik, hogy ez a "növeljük magok számát a végtelenségig" séma nem fog tovább működni. Ehhez ugyanis hatalmas kitettséget kockáztatnak a gyártástechnológiai fejlődés felé. A GA102 (Ampere) egy 628 mm2-es lapkára épül, amely a Samu 8 nm-es nodján van gyártva, ami inkább 10 nm LPP. Namost az NV-nek 2 teljes node és még egy negyed node-nyi ugrás (10 nm LPP -> 7 nm -> 5 nm -> 4 nm) kellett ahhoz, hogy a magok számát összességében 60 százalékkal tudja növelni. Már ez a node is rettenetesen drága, ha 2 év múlva újabb 600+ mm2-es lapkát tervez és ad ki az NV 3 nm-en az nem 1600 dollártól, hanem 2000 dollártól fog indulni.A lényeg: Az NV mehet tovább ezen az úton, amelyen most is van. Méregdrága kártyákat tervez mert csak ahhoz ért, hogy növelje a magok számát és ne optimalizálja azokat. Hol az IPC növekedés? Jóval magasabb órajelek mellett pont annyival gyorsabb az AD102 mint amennyivel több magot számlál a GA102-hez képest. A másik út a racionális. Ott a TSMC N4X node-ja amely javulás a mostani N4-hez képest. Hasonló lapka méret mellett inkább a magok hatékonyságára kéne koncentrálni, azaz egységnyi mag mondjuk 15%-al gyorsabb mint a Lovelace esetében. Ehhez hozzájön minimális mag szám emelés és +15-20%-os órajel emelés. Nos, igen ez lehet, hogy "csak" kb. 35-40%-os erősödést jelentene, de nem is kellene 2000+ dollárért adniuk az RTX 5090-et.
A két eltérő stratégiát nem csak az ár különböztetheti meg, hanem az is, hogy a fogyasztás sem száll az egekbe. Remélem, hogy az NV a másik mellett dönt és végre egy racionális és átgondolt termékpalettával lép a piacra, még ha az RDNA4-el szemben kevesebb esélye lenne így, de árban felvehetik a versenyt. Ha mégis a méregdrága node és a magok esztelen növelése mellett döntenek, akkor ugyan teljesítményben még nyerhetnek is... na de milyen áron?
Már egyébként most látszik, hogy a 3 nm bőven nem sikerült olyan jól mint az 5 vagy a 7. A 4 nm-hez képest hatalmas előrelépésre nem kell számítani. N3X meg csak 2025-re lehet termelő képes, de nagyoon drága lesz. Bár az NV-t ez nem igazán fogja érdekelni.
Ha az NV az N3-ra épít majd, akkor már 2024 decemberében is jöhet, és azzal egy racionálisabb paletta jön majd. Ha az N3X-re akkor az a bizonyos gyógyszer elgurult végleg és számítson mindenki a 2000 dolláros RTX 5090-re.
Szerk.: Nem a node a gond, hanem az NV stratégiája. Az AMD például simán válthat N4X-re, mégcsak N3 sem kell nekik, hiszen a GCD lapka sokkal kisebb mint az NV nagy monolitikus lapkája.
[ Szerkesztve ]
-
#41969
b.
félisten
Quadgame94
#41968
válasz
 Quadgame94
#41968
üzenetére
Quadgame94
#41968
üzenetére
Szó szerint az ellenkezőjét írod le annak amit a valóság tükröz.
1, Nvidia nem drágán tervez, hanem drágán ad el. Ez két különböző dolog.A gyártási költség nem az eladási ár.... és mindegyik nagyon drága mindegyi cégnek amúgy. A 3 D csomagolási technológia, az összekapcsolás az energiafogyasztás még jelenleg nincs arányában azzal, amit a Monolitikus dizájn tud adni.
Az teljesen jól látszik, hogy ez a "növeljük magok számát a végtelenségig" séma nem fog tovább működni.
Miből látszik ez teljesen jól ?
Milyen megoldást látsz a teljesítmény növelésére?
Az Ada a leggyorsabb kártya generáció a piacon és még nem is láttuk a teljes értékű verzióit. Fogyasztása és a hatékonysága konkrétan burtálisan jó lett, közelébe sincs egyik cég sem.
A szotferfejlesztők önmaguktól szinte semmit nem tesznek meg, ( tisztelet a kivételnek) jönnek a trehány félkész portok sorra. és minél gyengébb a kártyád vagy minél kevesebbet tud ,annál nagyobb hátányt szenvedsz.Lásd RX5700 de lassan egy előző generációs középkategóriás kártyával sem tudsz játszani semmivel maximális grafikán és nem a Vram miatt.
Mindegyik cég erre lép. A Chiplet dizáj a magok számának a növelése ugyan úgy skálázható formában. Nvidia is jönni fog vele,de ez nem azt jelenti hogy olcsóbb lesz vagy kevesebb maggal lesz gyorsabb.(I)"Méregdrága kártyákat tervez mert (I)csak(/I) ahhoz ért, hogy növelje a magok számát és ne optimalizálja azokat."(/I)

Lehet ezt a mondtatot komolyan venni szerinted? Vagy viccnek szántad?
Az Ada a energuiahatákonysága és technológiai tudása kemelkedő.25 % kal kevesebbet eszik mint az RTX 3090Ti és 50 % kal gyorsabb, miközben tele van egy halom optimalizált ficsőrrel.(I)A többit most nem is boncolgatom, mint pl , hogy fogalmam sincs milyen versenyről beszélsz amit majd talán felvehetnek az RDNA4 gyel.
MI a fene van az emberekkel komolyan?(/I)
Emlékeztetsz egy régi AMd-s fórmutagra . pepe, meg nem tudom mi volt még a neve az illetőnek régen itt.[ Szerkesztve ]
"A számítógépek hasznavehetetlenek. Csak válaszokat tudnak adni." (Pablo Picasso) "Never underrate your Jensen." (kopite7kimi)
-
#41970
Raymond
félisten
Quadgame94
#41968
Raymond
félisten
válasz
Quadgame94
#41968
üzenetére
#41969 b.
"Szerintem te egy teljesen más világból pottyantál ide.
Szó szerint az ellenkezőjét írod le annak ami a valóság."

Privat velemeny - keretik nem megkovezni...
-
"A számítógépek hasznavehetetlenek. Csak válaszokat tudnak adni." (Pablo Picasso) "Never underrate your Jensen." (kopite7kimi)
-
#41973
 Petykemano
veterán
Abu85
#41967
Petykemano
veterán
Abu85
#41967
Petykemano
veterán
Az IBM most adott ki Valami kódolást végző / segítő AI-t. Ha jól emlékszem pl Kobolt fordít java-ra.
A Sony talán nincs a topon ezen a téren, de a MS és az NV koprodukciójából el tudnék képzelni egy ehhez hasonló megoldást, ami pikk-pakk megoldja az ilyen problémákat.
Mit gondolsz?
Találgatunk, aztán majd úgyis kiderül..
-
#41974
Abu85
HÁZIGAZDA
Petykemano
#41973
Abu85
HÁZIGAZDA
válasz
 Petykemano
#41973
üzenetére
Petykemano
#41973
üzenetére
Az AI két dolgot nem tud jelenleg. Hibátlan és gyors kódot írni. A hibátlanra azért ott a lehetőség, hogy talán kijavítja magának, de optimalizálni nem igazán fogja. A lassú kódnak pedig nem veszik hasznát ezek a cégek.
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
#41976
Quadgame94
senior tag
b.
#41969
Quadgame94
senior tag
Miből látszik ez teljesen jól ?
Abból, hogy a gyártástechnológiai kitettség magas és hatalmas lapkákat tervezni (600+ mm2) és gyártani lutri abból a szempontból, hogy mi van ha teszem azt a N3 nem annyira jó? Márpedig az N3 bőven nem annyira jó. Architekturális szinten az Ada Lovalace meséld már el miben jobb és hatékonyabb mint az Ampere? Az előnye a gyártástechnológiai fejlődésből jött nem pedig az architektúrális változásokból.
I]Milyen megoldást látsz a teljesítmény növelésére?
Mondjuk magával az architektút hatékonyabbá tenni? A CUDA magokat gyorsabbá tenni? IPC növekedés? A Maxwell -> Pascall esetében ez megvolt.
Lehet ezt a mondtatot komolyan venni szerinted? Vagy viccnek szántad?
Az Ada a energuiahatákonysága és technológiai tudása kemelkedő.25 % kal kevesebbet eszik mint az RTX 3090Ti és 50 % kal gyorsabb, miközben tele van egy halom optimalizált ficsőrrel.Ezek az előnyök akkor tehát nem abból jönnek hogy Samu 8 nm-ről TSMC 4 nm-re váltottak. Aha nem. Hanem a ficsőrökből jönnek érteeem. Te mit is vitatsz? Ezeket az eredményeket amiket írtál én is elfogadom, csakhogy ezek mind a gyártástechnológiai előrelépésből jönnek.
Milyen versenyről beszélsz amit majd talán felvehetnek az RDNA4 gyel.
Ha elolvastad volna akkor értenéd. Ha nem vált az NV N3-ra vagy N3X-re akkor miért ne lehetne verseny az RDNA4-el? Olvasd el mit írtam és akkor érteni fogod: Abban az esetben ha nem mennek rá a említett node-ra akkor nem lesz ismét 60% gyorsulás. Ebben az esetben lehet verseny.
Az hogy kire emlékeztetlek az nem igazán érdekel. Tartsd meg magadnak. Amiket írtál semmilyen szempontból nem cáfolják azt amiket leírtam.
[
-
#41978
Quadgame94
senior tag
b.
#41969
Quadgame94
senior tag
1, Nvidia nem drágán tervez, hanem drágán ad el. Ez két különböző dolog.A gyártási költség nem az eladási ár.... és mindegyik nagyon drága mindegyi cégnek amúgy. A 3 D csomagolási technológia, az összekapcsolás az energiafogyasztás még jelenleg nincs arányában azzal, amit a Monolitikus dizájn tud adni.
Az hogy drágán tervez az relatív. Drágábban mint a konkurencia. Egy 600+ mm2 lapkát olcsóbb 4 nm-en gyártani mint egy 300 mm2-es lapkák 5 nm-en? Nem. Az hogy az árrése nagyobb az igaz.
Az a bizonyos monolitikus dizájn kétségtelenül gyorsabb. Azonban mint fentebb írtam drágább (bár ez kompenzálható) viszont a kitettség is nagyobb. Az NV-nek ha így halad tovább mindig a lehető legjobb gyártástechnológia kell és mindig 600+ mm2 lapka kell. Ezt vontam kétségbe, hogy vajon meddig mehet? Azért az AMD-nek amely egy sokkal de sokkal kisebb cég csak sikerült 30%-on belül lennie hozzájuk chiplet dizájnnal. Ha az NV rámenne erre akkor én bízom bennük annyira, hogy alkotnának valami szépet és gyorsat.
-

Devid_81
nagyúr
Elvileg az uj 4070Ti 16GB vramos lesz megis.
Most akkor AD103 lesz az, vagy nem veletlenul maradt le eddig is az a ket vram az AD104 PCB-krol?
...
-
#41980
 gbors
nagyúr
Quadgame94
#41978
gbors
nagyúr
Quadgame94
#41978
válasz
Quadgame94
#41978
üzenetére
Amit az AMD eddig chiplet fronton csinált, abban performance kockázat nemigen van - nyilván hasznos volt, hogy a fizikai aspektusait összerakták, kicsiszolták és működik, de ezt az NVIDIA is különösebb gond nélkül le tudja követni. A chipletesdi majd akkor lesz izgalmas, amikor a core-t is szétszedik, és látjuk, hogy a 2x96 vagy 4x48 CU teljesítménye hogy viszonyul az 1x192-höz.
Pedro... amigo mio... ma is konzervvért iszunk! Kár lenne ezért a tehetséges gyerekért...
-
#41981
Petykemano
veterán
Quadgame94
#41976
Petykemano
veterán
válasz
Quadgame94
#41976
üzenetére
Én nem becsülném le az Nvidiát.
Bármennyire is tűnik - esetleg technológiai szempontból - érdemtelennek, a működésük eredményes. Szoftveresen vezető pozícióban vannak, jó ütemben hoznak jónak bizonyuló döntéseket.gyártástechnológia
Az Ada Lovelace annyira jó, hogy a 600mm2-es lapkának (most fejből mondom) 15-20%-át nem is használja és úgy gyorsabb, mint az AMD legjobb terméke ebben a generációban. A 300+140mm2 versenyképes a 370mm2-rel. Az AMD itt valószínűleg valamilyen skálázódási problémával küzdhet. Míg az Nvidia látszólag rossz lóra tett a Samsunggal, mert belefutott ugyanabba a frekvencia-skálázódási és/vagy fogyasztási problémába, amivel az AMD is küszködött a Samsungtól licenszelt gyártástechnológiával GF-nél, addig mégis jó döntésnek bizonyult, mert valószínűleg sokkal kevésbé volt korlátos a rendelkezésére álló volumen, mintha a TSMC-től rendelt volna. Az AMD lépése a chiplet irányba viszont elhibázott ütemezésnek tűnik.De ez mindegy is. Az szerintem ismeretes, hogy az N3 esetén a TSMC küszködött kihozatali problémákkal. N2-től pedig csupán feleakkora (~400mm2) lapkamérettel lehet dolgozni. Erre nyilván az NVidia is készül.
Ami nekem szimpatikus az Nvidia designokban, hogy mintha tudatosan készülnének arra, hogy az adott node-on lehetnek kihozatali problémák - amik idővel javulnak és lehetővé teszik egy kevésbé vágott változat kiadását. (Az AMD szerintem robosztusabb designt tervez, ami már a nulladik pillanattól hibatűrőbb a redundanciák miatt, aminek persze ára van) Ebből fakadóan úgy vélem, hogy az Nvidia nem kis lapkákkal, hanem nagyobbb kezdeti vágással készül az N3 esetleges kihozatali problémáira, és azt 1 év leforgása alatt tervezhet finomítani.Mondjuk magával az architektút hatékonyabbá tenni? A CUDA magokat gyorsabbá tenni? IPC növekedés?
Szerintem nem igaz az, hogy az Ada Lovelace az Ampere-hez képest kizárólag gyártástechnológiában újított. A hatalmasra duzzasztott L2$ például egy jelentős lépés volt az IPC növelésében. Bár tartok tőle, hogy ilyen masszívan párhuzamos architektúrák esetén nehéz az IPC-t értelmezni (nem mondom, hogy nem lehet). A kérdés (ami köré szerintem az architektúrát építik) mindig az, hogy hogyan lehet megfelelő gyorsasággal (késleltetés, sávszélesség), és energiahatékonysággal etetni a feldolgozó egységeket. Az L2$ méretnövelése (amit persze valószínű, hogy a gyártástechnológia tett lehetővé) egy komoly lépés ebbe az irányba. A kevesebb adatmozgás kevesebb energiafelhasználással és hőtermeléssel jár és kevesebb üresjárattal is. Nagyjából ugyanezt célozta az AMD esetén is az Infinity cache is.Szerintem az irány a közeljövőben az lesz, hogy 3D irányba növelni a cache méreteket.
Találgatunk, aztán majd úgyis kiderül..
-
#41982
 Alogonomus
őstag
Quadgame94
#41978
Alogonomus
őstag
Quadgame94
#41978
Alogonomus
őstag
válasz
Quadgame94
#41978
üzenetére
Az is valószínűleg a monolitikus kialakítás magasabb költségterheit igazolja, hogy bár a darabszámot tekintve egyértelműen tartósan második pozícióba szorultak a desktop kártyák területén, amit tükröz is a globális részesedésük bő egy éve tartó stabil csökkenése, de ennek visszafordításához nem tudnak úgy "játszani" a kártyáik áraival, ahogy az AMD tud a saját kártyái áraival, ezért inkább az év elején visszafogták a 40-es kártyáik gyártási volumenét a piaci kereslethez igazodva.
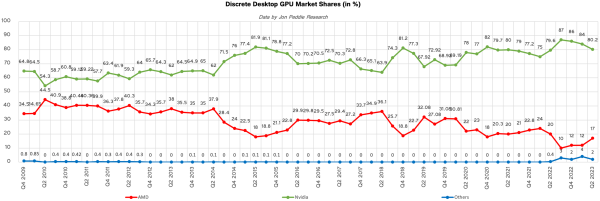
A szerverekbe szánt gyorsítók esetén sokkal kevésbé árérzékeny a piac, de a desktop kínálatban az ár/érték nagyon fontos. Még egy generációnyi drágán gyártható monolitikus kártyával nagyon a nyakukra engednék a piros oldalt annak chiplet kialakítás miatt olcsón gyártható desktop kártyáival.
-
#41983
Quadgame94
senior tag
Petykemano
#41981
Quadgame94
senior tag
válasz
Petykemano
#41981
üzenetére
Én nem írom le őket, sőt! Ha az N3X-t valasztjak újjabb 60% gyorsulás jöhet.
Anit írsz az IPC-ről nem igaz. L2 cache növelése nunt mint innovacií...hm oké.
3090 Ti v 4090
Pipelines / CUDA cores
10752 v 16384 1.52x
Core clock speed
1560 MHz v 2235 MHz 1.43x
Boost clock speed
1860 MHz v 2520 MHz 1.38xTeljesítmény:
100% v 140%Nos itt milyen IPC növekedést.olvasol ki? 1.52x több mag, 1.4x magasabb átlagos órajel és összességében 1.4x gyorsulás. A 4080 egyénként mérvadóbb. 9752 mag v 10752 azaz 90%-a a 3090 Ti-nek, de 1.4x magasabb órajel. Es ez csak 1.1x gyorsulásban eredményezik a 4080 javára. Ez mellett memória sávszélessége alacsonyabb de majd 11x tőbb L2 cache van rajta. Szóval én nem látok semmilyen IPC növekedést.
-
#41984
Quadgame94
senior tag
Alogonomus
#41982
Quadgame94
senior tag
válasz
 Alogonomus
#41982
üzenetére
Alogonomus
#41982
üzenetére
Úgy biztosan nem.tudnak játszami az árakkal ahogy az AMD, de nem is akarnak. Az NV nem.igazán érdekli most ez. Az AI és a Data Centerek érdeklik őket. Úgy vannak vele a teljesitmény jó, az árat.meg fizesse meg aki DLSS-t akar.
-
#41985
Alogonomus
őstag
Quadgame94
#41984
Alogonomus
őstag
válasz
Quadgame94
#41984
üzenetére
Ahogy az előző generációban a kripto-láz, úgy most az AI-láz is jól jött az NV-nek, de nem azokra készülve tervezték meg egyik generáció kártyáját sem, csak az Ampere kártyák nagyobb memóriabuszának a segítségével meglovagolhatták a kripto-lázat, majd az AI folyamatok futtatásához ideális Tensor-magok segítségével az eredetileg desktop vonalra szánt gyártási kapacitások nagy részét átcsatornázták az AI és Data Center vonal termékeire, mert ott megjelent egy nagy igény a gyorsítókártyák iránt.
A következő generációs Blackwell termékeket viszont nagyon rizikós lenne egy újabb "szerencsés fordulatban", "szerencsés világpolitikai helyzetben" bízva monolitikusra megtervezniük. Valójában valamennyire már jelenleg is kezd kifulladni az NV AI kapcsán keletkezett "szerencséje", mert míg az NV komolyabb hasznot hozó (AD102, GA100 és GH100 chipekre épülő) termékei főleg a Tensor-magok kiemelkedő teljesítménye miatt sok piacra hivatalosan már nem juthatnak el, addig az MI300 - esetleges későbbi kitiltásáig - ott tud lenni ezeken a piacokon jelenleg már konkurencia nélküli egyedüli szereplőként mind a Tensor-magok hiánya, mind a modularitásából következően garantálható maximális teljesítményének köszönhetően.
-
#41986
Petykemano
veterán
Quadgame94
#41983
Petykemano
veterán
válasz
Quadgame94
#41983
üzenetére
L2 cache növelése nunt mint innovacií...hm oké.
Szerintem az. Nem kis mértékben növelték.
Ugyanígy innovációnak tekinthető az AMD részéről a 3D V-cache alkalmazása, ami mintegy 15%-ot rádob a processzorok teljesítményére olyan felhasználási területek esetén, ahol a szálak közti adatmegosztás, összefüggés, együttműködés magas. Teszi mindezt úgy, hogy a processzor fogyasztását is alacsonyan tartja.Anit írsz az IPC-ről nem igaz.
Rendben. Ahogy mondtam, szerintem ebben a környezetben nehéz értelmezni az IPC fogalmát.
(Hozzáteszem fogyasztóként leginkább a PP$ ésa PPW kéne hogy érdekeljen)
Most nincs előttem sem az Ada és az Ampere architektúra, sem pedig a hozzájuk tartozó profilozó, hogy tudjam, hogy melyikben hol, mikor és milyen szűk kereszmetszetek alakulnak ki, ami miatt a frissebb architektúrából nem jön ki az a teljesítménytöbblet, aminek papírforma szerint ki kéne jönnie a névleges adatok alapján.Én csak azt mondtam, hogy ha kizárólag annyi történt volna, hogy SS8N-ről TSMC 4N-re portolják az Ampere architektúrát, akkor
- nem biztos, hogy kijött volna belőle az a frekvencia, amit most látunk.
- nem biztos, hogy a leadott teljesítmény a frekvenciával arányosan skálázódott volna.
A feldolgozókat ugyanis etetni kell adattal. az L2$ méretének jelentős megnövelése hozzájárulhatott ahhoz, hogy a frekvencia növelése a leadott teljesítményben is jelentkezni tudjon (adatra való várakozás helyett), valamint a memóriarendszeren keresztüli adatkommunikáción megspórolt energiát lehetett a frekvencia további növelésére költeni. (Ezzel nem azt állítom, hogy a frekvencia különbség kizárólag az L2$-nek köszönhető, csak azt, hogy az elért frekvenciához az is hozzájárulhatott)a 4080 vs 3090Ti összehasonlításhoz még annyit, hogy tényleg nem tudom, hogy hol lehetnek a szűk keresztmetszetek, de a 4080 (miközben nem is vágatlan lapka) kb 2/3 akkora fogyasztásból, 14%-kal magasabb teljesítményt hoz ki (3/5 akkora lapkamérettel)
Találgatunk, aztán majd úgyis kiderül..
-
#41987
 Jacek
veterán
Quadgame94
#41983
Jacek
veterán
Quadgame94
#41983
Jacek
veterán
válasz
Quadgame94
#41983
üzenetére
Nem 40%-a különbség a két kártya között.
-
#41989
Quadgame94
senior tag
Petykemano
#41986
Quadgame94
senior tag
válasz
Petykemano
#41986
üzenetére
Szerintem az. Nem kis mértékben növelték.
Hol számít egyébként ez a cache növelés? A 4090-nál érzem egyedül, mert a sávszél ugyanakkor a 3090 Ti-hez képest. Ott biztosan számít. 4080-an esetében vannak kétségeim. 64 MB v 6 MB azért tetemes növekedés, de inkább az órajel ami ott megdobja a teljesítményt.
Rendben. Ahogy mondtam, szerintem ebben a környezetben nehéz értelmezni az IPC fogalmát.
(Hozzáteszem fogyasztóként leginkább a PP$ ésa PPW kéne hogy érdekeljen)Persze ez igaz, az IPC-t azért hoztam fel mert az egy megoldás lehetne arra, hogy ne a magok számát, hanem a magos hatékonyságát növeljék.
a 4080 vs 3090Ti összehasonlításhoz még annyit, hogy tényleg nem tudom, hogy hol lehetnek a szűk keresztmetszetek, de a 4080 (miközben nem is vágatlan lapka) kb 2/3 akkora fogyasztásból, 14%-kal magasabb teljesítményt hoz ki (3/5 akkora lapkamérettel)
Igen. A 4080 szerintem is sokkal inkább egy tetszetősebb lapka minta batár 4090. Csak az a fárnya ára...
-
#41990
Jacek
veterán
Quadgame94
#41988
Jacek
veterán
válasz
Quadgame94
#41988
üzenetére
Alapja amit írsz, nekem volt mindkettő olyan program nincs ahol 40% csak a különbség de ha mindegy mindegy

Nem vita de berakom mint érdekességet Saját gép... nem test tudom nem TI de bitang tuning van rajta 

-
#41992
Petykemano
veterán
Quadgame94
#41989
Petykemano
veterán
válasz
Quadgame94
#41989
üzenetére
Hol számít egyébként ez a cache növelés? A 4090-nál érzem egyedül, mert a sávszél ugyanakkor a 3090 Ti-hez képest. Ott biztosan számít. 4080-an esetében vannak kétségeim. 64 MB v 6 MB azért tetemes növekedés, de inkább az órajel ami ott megdobja a teljesítményt.
Elképzelhető, hogy számít önmagában egy adat eléréséhez szükséges alacsonyabb késleltetés is. Azt nem tudom megítélni, hogy llyen masszívan párhuzamos architektúráknál ez ténylegesen mennyit dob a teljesítményen, mivel épp a CPU az, ami késleltetésre érzékeny, ennek meg pont nem annyira kéne.
Ami viszont számít, ahogy azt említettem volt, az az adatlokalitással nyert fogyasztáskeret, amit ahelyett, hogy arra költene el, hogy beolvasson valamit a VRAM-ból, magasabb frekvenciára költhet.Persze ez igaz, az IPC-t azért hoztam fel mert az egy megoldás lehetne arra, hogy ne a magok számát, hanem a magos hatékonyságát növeljék.
Szerintem ez nem ennyire egyszerű, vagy inkább úgy fogalmaznék, hogy szétválasztható. Szerintem a "magok" hatékonyságát alapvetően meghatározza az, hogy miképp tudod etetni. A legjobb persze az lenne, ha az összes feldolgozó rendkívül alacsony késleltetéssel a teljes közös memóriapoolból tudna olvasni. De tudjuk, hogy az nem biztosít kellő sávszélességet és késleltetést. Az egész kisebb-nagyobb hierachikus blokkokba szervezés azt a célt szolgálja, hogy a blokkokhoz hozzájuk tudj rendelni egy-egy olyan gyorsítótárat, ami - valamilyen arányban - biztosítja a blokkok gyors és kellően sok adathoz jutását, valamint esetleges együttműködésük során felmerülő gyors adatmegosztást.De egyébként nincs ez másként a CPU-k esetén is. Az IPC-nek elválaszthatatlan része az, hogy a feldolgozókhoz milyen cache-hierarchiát tudsz rendelni, amivel etetni tudod
Csak az a fárnya ára...
Igen, azért mondtam, hogy PP$Találgatunk, aztán majd úgyis kiderül..
-
#41993
Raymond
félisten
Quadgame94
#41989
Raymond
félisten
válasz
Quadgame94
#41989
üzenetére
"Hol számít egyébként ez a cache növelés?"
Cores GPix/s GTex/s TFlops GB/s
3090Ti 10752 208.3 625.0 40.00 1008
4070Ti 7680 208.8 626.4 40.09 504A dupla savszel ellenere a 3090Ti le van maradva 3%-al 1080p-ben es elonye is csak 2% 1440p-ben es 10% 2160p-ben. Azok a csekely elonyok pedig tunnek el az ujabb es ujabb cimekben es atfordulnak hatranyba.
Privat velemeny - keretik nem megkovezni...
-
#41994
b.
félisten
Quadgame94
#41976
válasz
Quadgame94
#41976
üzenetére
"Architekturális szinten az Ada Lovalace meséld már el miben jobb és hatékonyabb mint az Ampere? "
Ember Mindenben jobb, kivéve a sávszél,de ott nem tudom mennyit ellensúlyoz az L2 mérete. Komolyan nem is értem hogy hihetsz annak amiket leírsz
Nézd mega 4070 Ti-t és a 3090Ti-t. Gondolkozz már egy kicsit, nézz már teszteket hasonlísd már össze a két architektúrát.nem kellene nekem itt mesélnem neked hanem csak utána kellene nézned annak van e valóságalapja annak amit mondókázol .
Ráadásul az Ada RT terén még jobban elhúzott, ahogy jönnek azok a játékok amik valóban leterhelik majd ilyen téren megmutatja a foga fehérjét, lásd Alan Wake2.
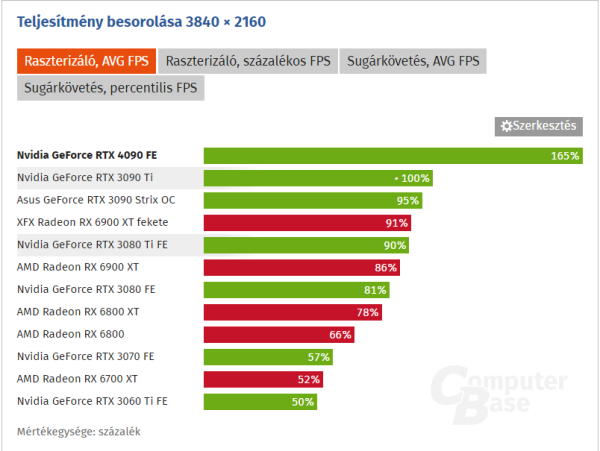
4070 Ti vs 3090 Ti :
3090Ti 10752 CC
4070Ti 7680 CC
EZ 40% kal kevesebb CC mag, 50% kal kisebb sávszél és 40% kal kisebb fogyasztás vagy ha úgy tetszik a 3090 TI 60% kal többet eszik árban meg 50% kal olcsóbb a 4070 Ti.
Sebességben a két kártya azonos , sőt.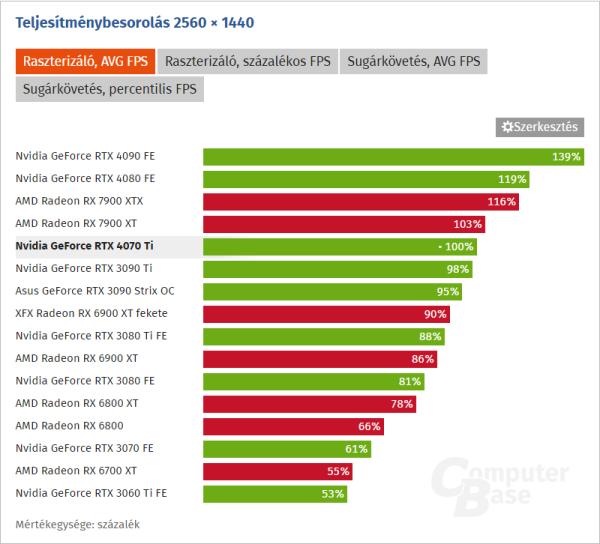
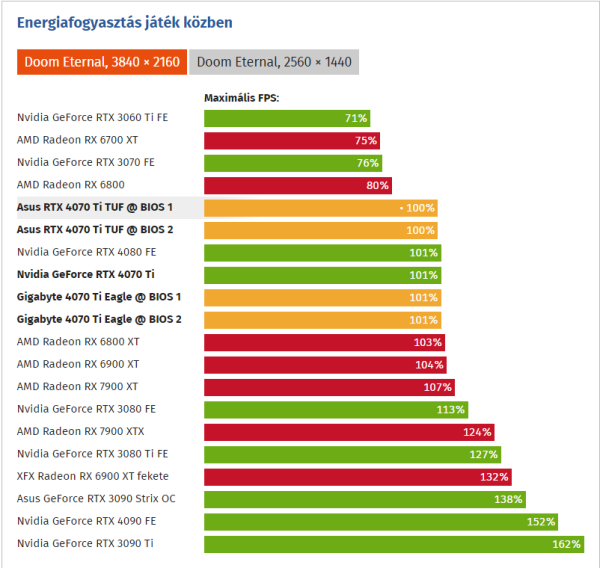
A 4090 meg nem 40 %

Itt pedig azonos fogyasztáson a két architektúra. 300W- ra lekorlátozva például :

Blender:
Ez mellett az RT végrehajtók, , a tensor stb mind újabb szintre lépett . Fogalmam sincs mikor kaptál ilyen architektúrát utoljára konkrétan vagy megetted az AMD chiplet marketingjét, miközben IPC terén pár % előrelépés történt náluk. Pl a 7600 2% kal gyorsabb azonos órajelen mint a 6650 ami elfogadható lenne ha közben a felét enné de messze nem ez a helyzet.
Az Alan Wake 2 tesztje:
Ezekben a címekben vagy Blenderben ahol ki van hazsnálva az Architekt 90 és 100% körüli előrelépést hoz a nem teljes értékű Ada..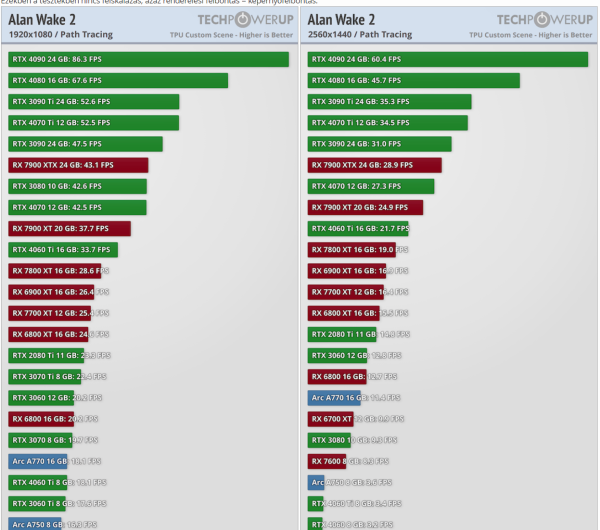
[ Szerkesztve ]
"A számítógépek hasznavehetetlenek. Csak válaszokat tudnak adni." (Pablo Picasso) "Never underrate your Jensen." (kopite7kimi)
-
#41995
Quadgame94
senior tag
b.
#41994
Quadgame94
senior tag
Fuh szerintem ezt még leírom és utána hanyagolom a veled való társalgást. Nem bírod értelmezni amit írok.
4070 Ti vs 3090 Ti :
3090Ti 10752 CC
4070Ti 7680 CC
EZ 40% kal kevesebb CC mag, 50% kal kisebb sávszél és 40% kal kisebb fogyasztás vagy ha úgy tetszik a 3090 TI 60% kal többet eszik árban meg 50% kal olcsóbb a 4070 Ti.
Sebességben a két kártya azonos , sőt.Ezekkel senki az életben nem vitatkozott. Amiket leírtál és felhoztál előnyöket, amelyek validak, nem architekturális változásokból erednek, hanem gyártástechnológiai előrelépésből. Kiemeltem neked, hogy egyértelmű legyen. Érdekes erre nem reagáltál a hozzászólásodban. A 4070 Ti akkor ezekszerint a 40%-os órajel emelkedésből nem kapacitál. Áh nem. És az minek köszönhető, hogy ennnyivel hatékonyabb mégis? Nem az Ada-nak az tuti. Hanem a TSMC 4 nm-nek.
A magon számának növelése és az órajel növelése abból jöhetett eleve létre, hogy Samu 8 nm-ről TSMC 4 nm-re tértek át. Te ezt valamiért egyáltalán nem emeled ki. Szerinted ez elhanyagolható információ vagy mi? Ezek az előnyök ebből fakadnak.
Már fentebb beszéltük, hogy az L2 is sokat segit illetve az RT magok is biztosan hatékonyabbak. Az L2 cache növelése mint architekturális újítás? Az hogy ezt meglépjék eleve kellett a 4 nm. Hiszen fizikailag sem fért volna rá 5 v 6 nm-re ennyi cache.
Az előrelépések hatalmas hányadát a 4 nm hozza és eleve ez tehette lehetővé.
-
#41996
Jacek
veterán
Quadgame94
#41995
Jacek
veterán
válasz
Quadgame94
#41995
üzenetére
Mindkét részről van igazság, de
Azt ne feledd hogy az ADA el van csúsztatva tehát a 4070 az 4060 valójában és így tovább.
Arról meg tényleg nem tehet az NV hogy lényegében nincs konkurencia, AMD 3 éve várja hogy beüssön PC-re a max konzol RT, de a CP patch tracingjét rá eresztenék a PS5-re és 1 fps lenne kb...
Pistike megnézi a teszteket és bekapcsolt RT mert a lecsóba az AMD, plusz eljött a szép új volát(várható volt) hogy FSR/DLSS nélkül 30 fps egy game... kösz NV..
És itt is jobb az NV ezzel el is dölt a dolog, azt ad ki az NV amit akar amíg ez marad... -
#41997
Abu85
HÁZIGAZDA
Quadgame94
#41995
Abu85
HÁZIGAZDA
válasz
Quadgame94
#41995
üzenetére
Nem 4, hanem 5 nm-es node-on készül az Ada... bár akkora jelentősége azért nincs, de a jegyzőkönyv miatt talán fontos lehet...

Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
#41998
 Busterftw
veterán
Quadgame94
#41995
Busterftw
veterán
Quadgame94
#41995
Busterftw
veterán
válasz
Quadgame94
#41995
üzenetére
Ez csak akkor tortenhet meg, ha az Nvidia kiadta volna az Amperet N4-en.
Ekkor kapnank meg azt, hogy valojaban mennyit szamit csak a gyartastechnologia.Viszont igy szamok nelkul teljesen marhasag amit allitasz, a teljesitmenybeli novekedes nem csak a gyartastechnologianak koszonheto, hanem X szazalekban az architechturanak is.
Ott van peldanak ha jol emlekszem a GTX 700 es GTX 900 szeria, mindketto ugyanazon a TSMC 28HP node-n keszult. Ha igaz lenne amit mondanal, nem lenne kulonbseg, ekozben a 900 szeria sokkal gyorsabb volt per watt.







 Mindketto speci AI gyorsito.
Mindketto speci AI gyorsito.






 Egy specifikus problemara egy megoldas, ott van a hirben is:
Egy specifikus problemara egy megoldas, ott van a hirben is:
![;]](http://cdn.rios.hu/dl/s/v1.gif)

































 szóval amúgy tényleg köszi nV, de szerintem mást értünk ezalatt
szóval amúgy tényleg köszi nV, de szerintem mást értünk ezalatt 
Új hozzászólás Aktív témák
A topikban az OFF és minden egyéb, nem a témához kapcsolódó hozzászólás gyártása TILOS!
MIELŐTT LINKELNÉL VAGY KÉRDEZNÉL, MINDIG OLVASS KICSIT VISSZA!!
A topik témája:
Az NVIDIA éppen érkező, vagy jövőbeni új grafikus processzorainak kivesézése, lehetőleg minél inkább szakmai keretek között maradva. Architektúra, esélylatolgatás, érdekességek, spekulációk, stb.


Állásajánlatok

Cég: Promenade Publishing House Kft.
Város: Budapest

Cég: Ozeki Kft.
Város: Debrecen