Új hozzászólás Aktív témák
-
#4400
 sh4d0w
félisten
golfvariant
#4399
sh4d0w
félisten
golfvariant
#4399
válasz
 golfvariant
#4399
üzenetére
golfvariant
#4399
üzenetére
Megtenni? Hol? bet365.com-on?
-
#4399
 golfvariant
aktív tag
golfvariant
aktív tag
golfvariant
aktív tag
Egy weboldal teljes tartalmát, css-el, képekkel együtt hogyan tudom megtenni pythonnal?

A választ előre is köszönöm!
-

sztanozs
veterán
válasz
 lanszelot
#4397
üzenetére
lanszelot
#4397
üzenetére
Problema ott lehet, hogy:
- a jatek a jatekallast nem a jatek konyvtara menti
- a mentendo fajlokat a jatek exkluziv irasra nyitotta meg, igy nem olvashatok amig zarolva vannak
- mentes kozben backupolt fajlok inkonzisztens allapotban lehetnek az irasi folyamat soran, ha epp akkor fut a backup akkor mentes korrupt lehet
- a jatek tartalmaz olyan anti-cheat funkciot ami a hasonlo backup folyamatokat figyeli es hiaba mented a konyvtarat ugy is invalid lesz a mentes -

lanszelot
addikt
Sikerült találni egy programot ami az asztalon egy linkkel elindítva a script azt teszi amire programozom: [link] Auot Hotkey
Már meg is csináltam, mehet a játék
Ha a párom játszik vele, ő nem tudja elindítani. Egyszerű megoldás kellett mint a fa bot Nagyon szépen köszönöm a segítséget
Nagyon szépen köszönöm a segítséget 
-
válasz
lanszelot
#4395
üzenetére
Minden programnyelv es szinte minden scriptnyelv tud ilyet, igazabol a kerdes az, miert nem jo a hatterben futo powershell script? Megcsinalja a backupod anelkul, hogy Neked el kellene inditanod.
De egeszen biztosan vannak mar kesz megoldasok erre, szerintem felesleges idotoltes ujra megirni valamiben.
-
-
lanszelot
addikt
Hello,
Egy játék nullázza a mentést pc-n ha meghalok.
Emiatt 15 percenként szeretnék backupot a játék mentés konyvtáráról (localappdata-ban van)
Nem felül írni, hanem mindig újat.
Meg lehet ezt írni pytonban?
Szinte semmi python alapom nincs javascript/php -t tanultam.
Ha meg lehet csinálni milyen tutorialokat keressek? -
-
-

togvau
senior tag
Van egy linuxos kis szerverem, ahova SSH-n logolok be, és szeretnék egy kis python scriptet futtatni.
Van rajta egy python 3, és vannak a scriptnek függőségei, de a python függőség káosz, és a semmi se jó már megint jól felidegesített.
beadom a függőségeket, hogypip install ffmpeg-python imagehash opencv-python --include-deps
Amire kidobja, hogy error: externally-managed-environment
Erre azt a megoldást találtam, hogy rakjak fel pipx-et. Felrakom, feltelepülnek (egyébként rohadt lassan, egy sima apt package telepítése sokkal gyorsabb), majd elindítom a scriptet, mire kivágja, hogy nincs cv2... pedig elvileg az opencv része, aztán olvastam olyat, hogy azt inkább a pip-el rakjam fel, ami kivágja, hogy fent van de végül is nincs fent, de van!programoztam pár nyelven (java, c#, js, php, go), de ilyen kaotikus hulladék függőség káoszt még nem láttam, sem olyat, hogy minden tizedes verzió nem kompatibilis a másik tizedes verzióval. Ezt hogy lehet kezelni megőrülés nélkül?
-

kovisoft
őstag
for y in range (led_brightness, 0, -1):Itt gondolom a led_brightness listán szeretnél visszafelé végigmenni, de ezt nem így kell csinálni. Ha a range-et használod, akkor kell a len is, és akkor az y csak az adott elem indexe lesz, azzal még indexelni kell a listát (szerk: sőt asszem még 1-et ki is kell vonni):
for y in range(len(led_brightness), 0, -1):
print(led_brightness[y-1])De egyszerűbb a reversed-del megfordítani a listát:
for y in reversed(led_brightness):
print(y)
Szerk2: vagy még így:for y in led_brightness[::-1]:
print(y) -

tvamos
nagyúr
Sziasztok!
Irtam 4 kis programreszletet, es az utolso nem mukodik, nem ertem, hogy pontosan miert.led_brightness = 0, 1, 2, 4, 8, 18, 41, 93, 211, 479, 1088, 2469, 5604, 12721, 28873, 65535for y in range(256):print (y*257)pca.channels[7].duty_cycle = y*257time.sleep (0.001)for y in range (65535, -1, -16):print (y)if y>=0:pca.channels[7].duty_cycle = yelse:pca.channels[7].duty_cycle = 0time.sleep (0.001)for y in led_brightness:print (y)pca.channels[7].duty_cycle = 65535-ytime.sleep (1)for y in range (led_brightness, 0, -1):print (y)pca.channels[7].duty_cycle = 65535-ytime.sleep (1)
El tudnatok magyarazni? Illetve hogy oldanatok meg a problemat? -
#4378
sztanozs
veterán
Atomantiii
#4377
sztanozs
veterán
válasz
 Atomantiii
#4377
üzenetére
Atomantiii
#4377
üzenetére
Ha nem muszaj a desc, akkor igy:
import xml.etree.ElementTree as ET
tree = ET.parse('full.xml')
root = tree.getroot()
for programme in root.findall('programme'):
desc = programme.find('desc')
if desc is not None:
directors = programme.findall('.//director')
actors = programme.findall('.//actor')
director_text = ('\nRendezte: ' + ', '.join(dir.text for dir in directors)) if len(directors) else ''
actor_text = ('\nSzereplők: ' + ', '.join(act.text for act in actors)) if len(actors) else ''
desc.text = f"{desc.text}\n{director_text}{actor_text}"
tree.write('modositott.xml', encoding='UTF-8', xml_declaration=True)
print("XML file has been modified and saved'") -
#4377
 Atomantiii
addikt
Atomantiii
#4376
Atomantiii
addikt
Atomantiii
#4376
Atomantiii
addikt
válasz
Atomantiii
#4376
üzenetére
Mondjuk valószínűleg ahol nincs desc ott nincs actor és director sem, így akkor a desc sem kell, de azt már szerintem ki tudom sakkozni a sub-title alapján majd.
-
#4375
sztanozs
veterán
Atomantiii
#4374
sztanozs
veterán
válasz
Atomantiii
#4374
üzenetére
Ezen a szekcion fekszik el (eloszor):
<programme start="20241016005500 +0200" channel="21.port.hu" stop="20241016015500 +0200" clumpidx="0/1">
<title>Az ismerős gonosz</title>
<sub-title lang="hu">(dokureality-sorozat, 1/3. rész)</sub-title>
<category lang="en">Show/Game show</category>
<category lang="hu">Show/Játék show</category>
<category lang="en">series</category>
<url system="port.hu">https://port.hu/adatlap/film/tv/az-ismeros-gonosz-the-devil-you-know/event-tv-1600952074-21/episode-2967986</url>
<episode-num system="xmltv_ns">0.2.0/1</episode-num>
<rating>
<value>16</value>
<icon src="https://port.hu/img/agelimit/raster/16_age_icon_black.png" />
</rating>
</programme>Ahogy irtam van egy csomo bejegyzes amiben nincs desc tag.
Ez siman lefut a nagy fajra is:import xml.etree.ElementTree as ET
tree = ET.parse('full.xml')
root = tree.getroot()
for programme in root.findall('programme'):
desc = programme.find('desc')
if desc is None:
desc = ET.SubElement(programme, "desc", {'lang': 'hu'})
directors = programme.findall('.//director')
actors = programme.findall('.//actor')
director_text = ('\nRendezte: ' + ', '.join(dir.text for dir in directors)) if len(directors) else ''
actor_text = ('\nSzereplők: ' + ', '.join(act.text for act in actors)) if len(actors) else ''
desc.text = f"{desc.text}\n{director_text}{actor_text}"
tree.write('modositott.xml', encoding='UTF-8', xml_declaration=True)
print("XML file has been modified and saved'") -
#4374
Atomantiii
addikt
Atomantiii
#4373
Atomantiii
addikt
válasz
Atomantiii
#4373
üzenetére
Vagy csak egyesével csatornánként lehet működtetni.
-
#4373
Atomantiii
addikt
sztanozs
#4371
Atomantiii
addikt
válasz
 sztanozs
#4371
üzenetére
sztanozs
#4371
üzenetére
Az m3.py működik, a forrás fájl neki az m3.xml. A másikban (porthu.py) ha csak egy tv csatorna van akkor megcsinálja - ez a 2.xml, ha benne van az összes akkor már hibára fut - full.xml. Lehet nem tud olyan nagy fájllal dolgozni? Bár az összefűzés és felesleges elementek törlését meg megcsinálja.
-
#4371
sztanozs
veterán
Atomantiii
#4370
sztanozs
veterán
válasz
Atomantiii
#4370
üzenetére
Teszt adatokat es kodot meg tod osztani?
-
#4370
Atomantiii
addikt
sztanozs
#4369
Atomantiii
addikt
válasz
sztanozs
#4369
üzenetére
Ha director és a actor benne van akkor mindettőre hibát ír, de ha csak külön van benne az egyik akkor is.
Most csak ennyi van benne a kódban:
desc = programme.find('desc')
directors = programme.findall('.//director')
actors = programme.findall('.//actor')
director_text = ('\nRendezte: ' + ', '.join(dir.text for dir in directors)) if len(directors) else ''
actor_text = ('\nSzereplők: ' + ', '.join(act.text for act in actors)) if len(actors) else ''
desc.text = f"{desc.text}\n{director_text}\n{actor_text}"Az is lehet nem tetszik neki valami a másik forrásfáljban, mert az máshogy készült, de az alap elementek ugyanazok.
Erre a sorra írja a hibát: desc.text = f"{desc.text}\n{director_text}\n{actor_text}"
-
#4369
sztanozs
veterán
Atomantiii
#4368
sztanozs
veterán
válasz
Atomantiii
#4368
üzenetére
stornomi az XML szekcio, amivel hibara fut?
-
#4368
Atomantiii
addikt
sztanozs
#4367
Atomantiii
addikt
válasz
sztanozs
#4367
üzenetére
Igen, de nem üres, benne van, hogy: <desc lang="hu"> ugyanúgy, mint a másikban.
Gyakorlatilag ugyanaz az element szerkezet, mint a működőnél (van title, sub-title, desc, credits, director, actor is.) Most csak a desc-et akarom módosítani a director és az actor beemelésével. Ezért nem értem mi lehet a baja.
-
#4367
sztanozs
veterán
Atomantiii
#4366
sztanozs
veterán
válasz
Atomantiii
#4366
üzenetére
ha a desc ures (None) akkor nem is tudod de kivenni belole a text mezot (es bele se tudod rakni...)
ilyenkor ezt letre kellene hoznod es ugy belerakni (ha ET == xml.etree.ElementTree):desc = programme.find('desc')
if desc is None:
desc = ET.SubElement(programme, "desc", {'lang': 'hu'}) -
#4366
Atomantiii
addikt
sztanozs
#4364
Atomantiii
addikt
válasz
sztanozs
#4364
üzenetére
Működik szépen az egyik forráson, a másiknak kicsit más a szerkezete, de ugye az alapszerkezet ugyanaz csak több infó és element van, ott viszont hibára fut valamiért ebben a sorban:
desc.text = f"{desc.text}\n{director_text}\n{actor_text}"Traceback (most recent call last):
File "d:\EPG\teszt.py", line 34, in <module>
desc.text = f"{desc.text}\n{director_text}\n{actor_text}"
^^^^^^^^^
AttributeError: 'NoneType' object has no attribute 'text' -
#4365
Atomantiii
addikt
sztanozs
#4364
Atomantiii
addikt
válasz
sztanozs
#4364
üzenetére
Azt most itthon próbáltam és más volt a forrás xml fájl és azon nem tetszik neki. Kicsit más, mint a másik de az alapszerkezet ugyanaz, de érdekes, hogy ami a másikon lefutott ezen nem fut le, hanem ezt a hibát írja.
Meg arra jöttem rá, hogy nem a title-be kellett volna rakni a category-kat és a date-t hanem a sub-tutile-ba, az viszont már nem igazán tetszik neki. Fogok kísérletezni velük amint időm engedi.
-
#4364
sztanozs
veterán
Atomantiii
#4362
sztanozs
veterán
válasz
Atomantiii
#4362
üzenetére
remelem csak az utolso harom sort cserelted ki, es megtartottad ami felette volt a sajatodban...
-
#4361
 paler
aktív tag
Atomantiii
#4358
paler
aktív tag
Atomantiii
#4358
paler
aktív tag
válasz
Atomantiii
#4358
üzenetére
Erre gondolsz?
-
sztanozs
veterán
válasz
sztanozs
#4357
üzenetére
Bocs, ez meg mindig nem volt jo...
#
director_text = f'\n Rendezte: {director.text}' if director is not None else ''
actor_text = ('\n Szereplők: ' + ', '.join(act.text for act in actors)) if len(actors) else ''
desc.text = f"{desc.text}\n{director_text}{actor_text}"Ja es ne a modositott xml-lel probald, abban mar benne van a Szereplok: sor...
-
#4357
sztanozs
veterán
Atomantiii
#4355
sztanozs
veterán
válasz
Atomantiii
#4355
üzenetére
esetleg
#
director = f'\n Rendezte: {director.text}' if director else ''
actor_texts = ('\n Szereplők: ' + ', '.join(act.text for act in actors)) if len(actors) else ''
desc.text = f"{desc.text}\n{director}{actor_texts}" -
#4356
Atomantiii
addikt
Atomantiii
#4355
Atomantiii
addikt
válasz
Atomantiii
#4355
üzenetére
Vagy csak egyszerűen átírom arra, hogy if actors else 'Nincs információ'.
-
#4355
Atomantiii
addikt
sztanozs
#4354
Atomantiii
addikt
válasz
sztanozs
#4354
üzenetére
Valahogy azt szeretném elérni, hogy ha nincs megadva az actorból egy sem az eredeti xml-ben, akkor már a Szereplők szót se rakja bele hanem maradjon üresen a desc-ben. Ha arra rájövök hogy kéne akkor a többire is meg tudnám csinálni (rendezte, stb).
Próbálgatom azzal amit írtál, így majdnem jó, csak ha nincs actor akkor is ott lesz a szereplők szó. Eddig én is eljutottam vele csak kicsit máshogy.
-
#4354
sztanozs
veterán
Atomantiii
#4353
sztanozs
veterán
válasz
Atomantiii
#4353
üzenetére
marmint, hogy a szereplok sor ne is legyen benne?
#
director = f'\n Rendezte: {director.text}' if director else ''
actor_texts = ('\n Szereplők: ' + ', '.join(act.text for act in actors)) if actors else ''
desc.text = f"{desc.text}\n{director}{actor_texts}" -
#4353
Atomantiii
addikt
sztanozs
#4320
Atomantiii
addikt
válasz
sztanozs
#4320
üzenetére
Közben más irányba indultam el, már majdnem jó csak azt nem tudom hogyan mondjam meg neki, ha bizonyos element nem létezik akkor ne írjon oda semmit sem hanem hagyja üresen.
for programme in root.findall('programme'):title = programme.find('title')categories = programme.findall('category')date = programme.find('date')category_texts = ', '.join([cat.text for cat in categories])date = date.text if date is not None else "Ismeretlen év"title.text = f"{title.text} ({category_texts}, {date})"desc = programme.find('desc')director = programme.find('.//director')actors = programme.findall('.//actor')director = director.text if director is not None else "N/A"actor_texts = ', '.join([act.text for act in actors])desc.text = f"{desc.text} \n \n Rendezte: {director} \n Szereplők: {actor_texts}"Ennél pl nincs actor vagyis szereplőkről adat így azt szeretném, ha a szereplőket ne írná bele a desc részbe, hanem maradjon üresen.
Ilyen az átalakított xml fájl:
<programme start="20241009220000 +0000" stop="20241009224000 +0000" channel="M3">
<title lang="hu">Helló, világ! (Ismeretterjesztő Sorozat, 1998)</title>
<sub-title lang="hu">Karácsony: Lisszabon, Franciaország, Moszkva, Hamburg, Svájc, Jeruzsálem</sub-title>
<desc lang="hu">Járjuk be együtt a világot! A mai adás bemutatja, milyen a karácsony Lisszabonban, Moszkvában és Jeruzsálemben, a betlehemezők Svájcban, a karácsonyi desszert Franciaországban és a téli hattyúmentés Hamburgban.Rendezte: Lengyel Zsolt
Szereplők: </desc>
<credits>
<director>Lengyel Zsolt</director>
</credits>
<date>1998</date>
<category lang="hu">Ismeretterjesztő Sorozat</category>
<icon src="https://musor.tv/images/m3.svg" />
<country lang="hu">Magyar</country>
<episode-num system="onscreen">E103</episode-num>
<rating>
<value>12</value>
<icon src="https://musor.tv/images/etc/pg_12.svg" />
</rating>
</programme><programme start="20241010003500 +0000" stop="20241010011000 +0000" channel="M3">
<title lang="hu">Életképek (Sorozatok, Dráma, Melodráma, 2005)</title>
<desc lang="hu">Elváláskor János puszit ad Évának, aki viszonozza. Viola továbbra is dolgozik Jánosnak, természetesen lebukik Katinka előtt. Zoltán turnéra megy a nyáron, hívja Katinkát, hogy menjen vele, de ő még hezitál. Viola és Éva véletlenül találkoznak, egy ital mellett Viola bevallja, minden pénzét elkártyázta. Ezenkívül azt is megosztja Évával, hogy egy éve ő küldte a figyelmeztető leveleket neki, amik a házasság felbomlásáról szóltak. A lányok nagyon szeretnének barátjaikkal Balatonra menni idén nyáron is, de ahhoz még a szülők engedélye kell...Rendezte: Horváth Ádám
Szereplők: Csűrös Karola, Galán Géza J., Garas Dezső, Gáti Oszkár, Hegyi Barbara, Herrer Sára, Kováts Adél, Kulka János, Nemcsók Nóra, Rátóti Zoltán, Schell Judit, Szacsvay László, Vári Éva</desc>
<credits>
<director>Horváth Ádám</director>
<actor>Csűrös Karola</actor>
<actor>Galán Géza J.</actor>
<actor>Garas Dezső</actor>
<actor>Gáti Oszkár</actor>
<actor>Hegyi Barbara</actor>
<actor>Herrer Sára</actor>
<actor>Kováts Adél</actor>
<actor>Kulka János</actor>
<actor>Nemcsók Nóra</actor>
<actor>Rátóti Zoltán</actor>
<actor>Schell Judit</actor>
<actor>Szacsvay László</actor>
<actor>Vári Éva</actor>
</credits>
<date>2005</date>
<category lang="hu">Sorozatok</category>
<category lang="hu">Dráma</category>
<category lang="hu">Melodráma</category>
<icon src="https://musor.tv/img/fb/46/4633/Eletkepek_28_.jpg" />
<country lang="hu">Magyar</country>
<episode-num system="onscreen">E28/114</episode-num>
<rating>
<value>12</value>
<icon src="https://musor.tv/images/etc/pg_12.svg" />
</rating>
</programme>Az elsőnél a félkövérrel kiemelt szereplőket szeretném eltüntetni, mert nincs adat, de az utolsónál meg van és az ott úgy jó lenne. De nem tudom hogyan kéne eltüntenti, hogy üresen maradjon és ne jelenjen meg semmi sem. Illetve ha nincs adat akkor az "N/A" se jelenjen meg a rendezőnél, hanem maradjon üresen és a rendező se jelenjen meg a desc-ben.
-
sztanozs
veterán
ahogy nezem csak a \t \r \n vannak megjelenitve, a tobbieket felismeri, de nem a vezerlokarakter formaban jelenitei meg. az ertekek ettol foggetlenul ugyanazok:
>>> bytearray(b'\a\b\f\n\r\t\v')
bytearray(b'\x07\x08\x0c\n\r\t\x0b')
>>> [int(n) for n in bytearray(b'\a\b\f\n\r\t\v')]
[7, 8, 12, 10, 13, 9, 11]
>>> [int(n) for n in bytearray(b'\x07\x08\x0c\x0a\x0d\x09\x0b')]
[7, 8, 12, 10, 13, 9, 11] -
sztanozs
veterán
amig az int erteke 0-255 kozott van, addig byte-kent van kezelve pythonban. Ha ettol kulonbozo akkor (big)int.
>>> a1=[0,1,2,3]
>>> bytearray(a1)
bytearray(b'\x00\x01\x02\x03')
>>> a2=[254,255,256,257]
>>> bytearray(a2)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ValueError: byte must be in range(0, 256)
>>> b1=bytearray([0,1,2])
>>> b1[0]
0
>>> b1[0]=5
>>> b1
bytearray(b'\x05\x01\x02')
>>> b1[0]=256
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ValueError: byte must be in range(0, 256) -
tvamos
nagyúr
válasz
sztanozs
#4343
üzenetére
Jo, en ezt igy nem ertem. Ez ilyen Micropython/Circuitpython.Oke, azt sejtem, hogy ertem mar... de ettol meg valahogy meg kell eroszakolnom a dolgot. Van erre valami modszer? Mert amugy valahogy elkavircol a dolog, amig konstansokat teszek bytearray-be, addig megy a dolog.
A szenzor az i2c porton 8 bitet var, (uint8_t,) azt nem erdekli, hogy gepi kodban programozom az MCU-t, vagy python. -
-
tvamos
nagyúr
Nem lett jo.
Az amugy miert van, hogy erre:type(read_VHV_CONFIG)azt mondja, hogyclass 'bytearray'; de erretype(read_VHV_CONFIG[0])meg azt, hogyclass 'int'? Nem ugy van, hogy a byte unsigned 8-bit, az int meg signed 16-bit?
Amugylen(read_VHV_CONFIG): 1. Szoval ez 1 byte. Hogy lesz ebbol int? Kiakaszt.
Amugy tobb mint valoszinu azert nem jo a lib ugy, ahogy van, mert a szenzor 1V8 modban indul, nekem azt at kene kapcsolnom 2V8 modba, de nem sikerul. Lehet, hogy Adanak sem sikerult? De hat o csak okosabb nalam, es nem ezen a bytearray vs. int dolgon csuszott el! -
tvamos
nagyúr
Azt hasznalnam, csak nem mukodik rendesen. Amikor belemaszok a konyvtarba, (hogy ne csak azr irogassa, hogy hiba, hanem azt is, hogy mi a baja,) akkor kiderul, hogy hulyesegeket valaszol, nem azt, amit kene.
De az a sejtesem, hogy hardveres lehet a problema... illetve user error. -
tvamos
nagyúr
Sziasztok!
Circuitpythonban (raspberry pi picon) probalok egy szenzort (VL53L0X) olvasni, es a doksi szerint egy bitet kene 1-be billenteni. A regisztert ki tudom olvasni igy:read_VHV_CONFIG = self._read_register(0x89,1)
Nomost ha kiiraton aread_VHV_CONFIGerteket, akkor ezt kapom:bytearray(b'\x08')
Ami mondjuk jo is, de amikor problom a 0. bitet bebillenetni 1-be igy:read_VHV_CONFIG[0] = read_VHV_CONFIG[0] | b'0x01'
Akkor azt mondja nekem, hogy:TypeError: unsupported types for __or__: 'int', 'bytes'
Ezt igy annyira nem ertem. Raadasul, ha atirom erre:read_VHV_CONFIG[0] = read_VHV_CONFIG[0] | 1
Akkor meg aread_VHV_CONFIGertekere ezt kapom:bytearray(b'\t')
Mondjuk ha ezt megprobalom vissza irni a regiszterbe igy:self._write_register(0x89, read_VHV_CONFIG)
akkor termeszetesen semmi sem tortenik. -
tvamos
nagyúr
Ja, nem. Fut ez, csak kifagy a verbe a Tk.

Amugy ez van a readSerialPort()-ban:def readSerialPort():global serString, serCounter, label1while 1:serString[serCounter] = ser.readline()if str(serString[serCounter]).find('-----------------------') >= 0:print("reset counter")serCounter = 0else:print ( str(serCounter) + " - " + str(serString[serCounter]) )if serCounter==0:label1.config(text=str(serString[serCounter]))serCounter += 1time.sleep(0.01) -
-
tvamos
nagyúr
Sziasztok!
A kovetkezo problemam van:
A szamitogepen probalnam olvasni a soros portot, de folyamatosan azt a hibauznetet kapom, hogy "Exception: Opening serial port: Port is already open."
A gepemen Windows 10 van, Python 3.12.2, es pyserial 3.5.
A soros porton az eszkoz amugy mukodik, putty-ban jonnek az adatok.
A nem tul bonyolult kod, amit futtatni probalok:import serial, timeSERIALPORT = "COM15"BAUDRATE = 115200ser = serial.Serial(SERIALPORT, BAUDRATE)print ("Starting Up Serial Monitor")try:ser.open()print ("Serial port is succesfully opened: " + str(SERIALPORT))except Exception as e:print ("Exception: Opening serial port: " + str(e))ser.close() -

Pxs
aktív tag
válasz
 Hege1234
#4326
üzenetére
Hege1234
#4326
üzenetére
Köszi, működött!
Igen, olyasmi, egy jóval nagyobb script részeként.Most meg van egy ilyen mókám, szintén JSON (illetve Python-dict), ahol egy meglévő "hazai_csapat_lejatszott_meccsek" változóba kellene átadnom a 98. sorban lévő ""name": "Overall Matched Played"" kulcs feletti "value": "1" kulcs értékét (1-et).
De mindezt úgy, hogy még előtte ellenőriznie kellene, hogy a 21. sorban lévő ""name": "FC Bayern München" kulcs értéke megegyezik-e a "hazai_csapat" változó értékével, csak akkor keressen tovább az említett "Overall Matched Played" string-ig, és mielőtt azt megtalálja, mentse egy ideiglenes változóba minden iteráció során az összes "value" kulcsot, amibe útközben akad. (úgy, hogy aztán felhasználható maradjon későbbre is a legutolsó mentett érték)Bocs, még nagyon kapkodom a fejem e téren, pedig van némi programozási tapasztalatom
{
"data": [
{
"id": 241976,
"participant_id": 503,
"sport_id": 1,
"league_id": 2,
"season_id": 23619,
"stage_id": 77471317,
"group_id": null,
"round_id": 357241,
"standing_rule_id": 117850,
"position": 1,
"result": "equal",
"points": 3,
"participant": {
"id": 503,
"sport_id": 1,
"country_id": 11,
"venue_id": 53,
"name": "FC Bayern München"
},
"details": [
{
"id": 3523848805,
"standing_type": "standing",
"standing_id": 241976,
"type_id": 130,
"value": 1,
"type": {
"id": 130,
"name": "Overall Won"
}
},
{
"id": 3523848806,
"standing_type": "standing",
"standing_id": 241976,
"type_id": 131,
"value": 0,
"type": {
"id": 131,
"name": "Overall Draw"
}
},
{
"id": 3523848802,
"standing_type": "standing",
"standing_id": 241976,
"type_id": 133,
"value": 9,
"type": {
"id": 133,
"name": "Overal Goals Scored"
}
},
{
"id": 3523848819,
"standing_type": "standing",
"standing_id": 241976,
"type_id": 144,
"value": 0,
"type": {
"id": 144,
"name": "Away Lost"
}
},
{
"id": 3523848803,
"standing_type": "standing",
"standing_id": 241976,
"type_id": 134,
"value": 2,
"type": {
"id": 134,
"name": "Overall Goals Conceded"
}
},
{
"id": 3523848815,
"standing_type": "standing",
"standing_id": 241976,
"type_id": 187,
"value": 3,
"type": {
"id": 187,
"name": "Overall Points"
}
},
{
"id": 3523848804,
"standing_type": "standing",
"standing_id": 241976,
"type_id": 129,
"value": 1,
"type": {
"id": 129,
"name": "Overall Matched Played"
} -

Pakliman
tag
válasz
sztanozs
#4323
üzenetére
Szia!
Még van egy dolog: a drive-os listát több részletben kapom meg , a nextPageToken... adja a következő adagot stb. Szeretném először lekérni a teljes listát, viszont ezt csak úgy tudom megoldani, hogy append-el a már meglévő items-hez adom
(items.append(results.get('files', [])). Csakhogy az items egy set-ekből álló list, így viszont az eredmény kezelhetetlen lesz (számomra):[[{},{},{}],[{},{},{}]]vagyis set-eket tartalmazó listákat tartalmazó lista...
Megoldható "egyszerűen", vagy a kapott lista elemeit egyesével kell hozzáadni az items-hez? -
-

Hege1234
addikt
random adatokat adtam hozzá a json-hoz
(ez így még csak kiírja, a két kiválasztott csapat adatait)
a 2 kiválasztott csapatot akarod végül összehasonlítani?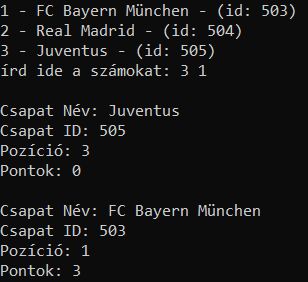
for idx, stuffs in enumerate(data_resp['data'], start=1):
print(f"{idx} - {stuffs['participant']['name']} - (id: {stuffs['participant']['id']})")
selected_indices = input("írd ide a számokat: ").split()
selected_indices = [int(i) for i in selected_indices]
print()
for idx in selected_indices:
if 1 <= idx <= len(data_resp['data']):
s_participant_datas = data_resp['data'][idx - 1]
s_participant_name = s_participant_datas['participant']['name']
s_participant_id = s_participant_datas['participant']['id']
s_position = s_participant_datas['position']
s_points = s_participant_datas['points']
print(f'Csapat Név: {s_participant_name}')
print(f'Csapat ID: {s_participant_id}')
print(f'Pozíció: {s_position}')
print(f'Pontok: {s_points}')
print()
else:
print(f"nincs ilyen...: {idx}") -
Pxs
aktív tag
A keresés pedig az alábbi kóddal fut:
league_id = result['league_id']
standings_url = f"https://api.sportmonks.com/v3/football/standings/live/leagues/{league_id}?include=participant"
standings_response = requests.get(standings_url, headers=headers)
if standings_response.status_code == 200:
try:
standings_data = standings_response.json()
# Alakítsa át a kapott eredményt python-szótárrá
standings = standings_data.get("data", [])
# A team1 és team2 mentése és kiírása
if " vs " in search_value:
team1, team2 = search_value.split(" vs ", 1)
team1 = team1.strip()
team2 = team2.strip()
print(f"TEAM1: {team1}")
print(f"TEAM2: {team2}")
# Keresés a team1 értékére az állás adatokban
print(f"team1 keresett értéke: {team1}")
team1_found = False
for group in standings:
if isinstance(group, dict):
participants = group.get("standings", [])
for team in participants:
participant = team.get("participant", {})
if participant.get("name") == team1:
print("TEAM1 jelen")
print(f"Csapat ID: {participant.get('id')}")
print(f"Pozíció: {team.get('position')}")
print(f"Pontok: {team.get('points')}")
team1_found = True
break
if team1_found:
break
if not team1_found:
print("TEAM1 nincs az állások között.")
else:
print("A meccsnév nem megfelelő formátumú.") -
Pxs
aktív tag
Sziasztok, elég új nekem még a Python, és van egy ilyen adatszerkezetem, amit JSON-ban kapok egy API-endpoint meghívása után.
Foci tabella állások egy adott ligában, és ebből lenne szükségem az adott csapat nevére ("name" kulcs), ID-jára ("id" kulcs, de ebből van egy az eggyel feljebb lévő szinten is, nem az kell, mert az az állás ID-ja), helyezésére ("position" kulcs), és pontszámára ("points" kulcs).
Viszont első körben a csapat nevét kellene megtalálnia, aztán az ahhoz tartozó ID-t, és a szerintem nagyobb probléma, hogy a "position" és a "points" kulcsok már egy szinttel feljebb találhatók.
Miként lehetne ezt megoldani? Már a PyCharm AI-asszisztense is csődött mondott, vagy én használom rosszul. Illetve fontos Python dictionary-be konvertálni a keresés előtt a JSON-objectet? Előre is köszi!
"data": [
{
"id": 18404871,
"sport_id": 1,
"league_id": 2,
"season_id": 23619,
"stage_id": 77471317,
"group_id": null,
"round_id": 357241,
"participant_id": 503,
"standing_rule_id": 117850,
"position": 1,
"points": 3,
"result": "equal",
"participant": {
"id": 503,
"sport_id": 1,
"country_id": 11,
"venue_id": 53,
"gender": "male",
"name": "FC Bayern München",
"short_code": "FCB",
"image_path": "https://cdn.sportmonks.com/images/soccer/teams/23/503.png",
"founded": 1900,
"type": "domestic",
"placeholder": false,
"last_played_at": "2024-09-21 13:30:00"
} -
sztanozs
veterán
válasz
 Pakliman
#4322
üzenetére
Pakliman
#4322
üzenetére
google drive-nal egy nev tobbszor is szerepelhet?
ha igen melyiket akarod letolteni?egyebkent (kb, ex-has, az elso egyezo id-t toltene le):
dest_dir = Path(sDestDir)
items_dict={}
for i in items:
gid, name = i['id'], i['name'].upper()
if name in items_dict:
items_dict[name] += [gid]
else:
items_dict[name] = [gid]
for mr in mr_files_array:
name = mr.upper()
if name in items_dict:
db += 1
with open(dest_dir / name, 'wb') as fh:
downloader = MediaIoBaseDownload(fh, service.files().get_media(fileId=items_dict[name][0]))
... -
Pakliman
tag
Sziasztok!
Légyszi, segítsen egy hozzáértő...
Google drive lekérdezés eredményeként ezt kapom:items = [{'id': '1pASxkibxbqKnzpxaangfkzF_XblCADVm', 'name': 'C79575 04.txt'}, {'id': '10-GRoKxhwsjXTfT8Weje0RZ8SUEWT7Cf', 'name': 'C79575 01.txt'}, {'id': '1pwvGktJU5oKwkT0UoRxqltcTz-def3ip', 'name': 'C79576 05.txt'}]
Van egy listám, amiben ez szerepel (Excel cellák tartalma lesz egy sztringbe rakva nagybetűsre konvertálva):mr_files_array= "v223345 grd.kkk\nC79575 04.txt\nx22222 rer.sf\nC87517 01.txt\nC85644 01.txt\n"Az eredményen belül csak azokkal akarok foglalkozni, amik szerepelnek a listában.Pl.: "C79575 04.txt", "C87517 01.txt" és "C85644 01.txt"
Persze nekem az 'id' kell ahhoz, hogy le tudjam tölteni.
Dupla for ciklussal baromi sokáig "dolgozik" akkor is, ha találat esetén kilépek a belső ciklusból és törlöm azmr_files_arraylistából a már megtalált elemet.for item in items:
for mr in mr_files_array:
if mr == item['name'].upper():
db += 1
with open(sDestDir + chr(92) + item['name'], 'wb') as fh:
downloader = MediaIoBaseDownload(fh, service.files().get_media(fileId=item['id']))
done = False
while not done: done = downloader.next_chunk()
mr_files_array.remove(item['name'].upper())
mr_db = len(mr_files_array)
with open(sCBFile, "a") as f:
f.write(item['name'] + ' : Ok' + '\n')
f.flush()
break
if db == mr_db: break
Sajnos a keresések nem hoztak eredményt számomra
A Python "tudásom" egyenlő a nullával, VBA-ban dolgozom már 2 évtizede.
A segítséget előre is köszönöm... -
#4320
sztanozs
veterán
Atomantiii
#4317
sztanozs
veterán
válasz
Atomantiii
#4317
üzenetére
xml.minidom modullal betoltod, kikeresed a megfelelo node-okat es es megszerkeszted az altalad kivalasztottat.
a hivatalos oldalon elvo pelda egeszen szemleletes:
https://docs.python.org/3/library/xml.dom.minidom.html -
#4319
 olli
tag
Atomantiii
#4317
olli
tag
Atomantiii
#4317
olli
tag
válasz
Atomantiii
#4317
üzenetére
Lemaradt a print...
Bocs, magamnak válaszoltam. -
olli
tag
Sziasztok!
Abszolut kezdőként kérdezem: IDLE Shell 3.12.6 megnyitom.import itertools
# Define the range of numbers (1 to 90)
numbers = range(1, 91)
# Define the target sum
target_sum = 225
# Generate all combinations of 5 numbers from the range 1 to 90
combinations = itertools.combinations(numbers, 5)
# Filter combinations whose sum equals the target_sum
valid_combinations = [comb for comb in combinations if sum(comb) == target_sum]
# Count the number of valid combinations
num_valid_combinations = len(valid_combinations)
valid_combinations, num_valid_combinationsKódot soronként bemásolom, sorok végén enter.
Kód lefut, rákérdez a futtatásra.
Ugyan itt: New File megnyit, kód bemásol, mentés ujmind.py
Run> Run Module : = RESTART: C:/Users/win11/AppData/Local/Programs/Python/Python312/ujmind.py és semmi..
Mit csinálok rosszul? -
#4317
Atomantiii
addikt
Atomantiii
addikt
Szeretnék ismét segítséget kérni xml fájl szerkeszéssel kapcsolatban. Van egy ilyen xml fájlom, hogy:
<?xml version="1.0" encoding="UTF-8"?>
<channel id="M3">
<display-name lang="hu">M3</display-name>
</channel>
<programme start="20240910220000 +0000" stop="20240910224000 +0000" channel="M3">
<title lang="hu">Helló, világ!</title>
<sub-title lang="hu">Indonézia, Kelet-Szibéria, Alpe d'Huez, Kamakura, Essaouira</sub-title>
<desc lang="hu">Járjuk be együtt a világot! Hajózzunk Indonéziába, a Szulavézi-szigetre, és ismerjük meg a toradzsák szokásait! Kísérjük el a kelet-szibériai tigrisvadászokat egy befogásra! Síeljünk Alpe d'Huez lejtőin! Ismerjük meg a kamakurai kardkészítőket! Látogassunk el a marokkói Essaouirába, ahol a gnaoua nép zenével gyógyít!</desc>
<date>1998</date>
<category lang="hu">Ismeretterjesztő Sorozat</category>
</programme>
</tv>Olyat lehet-e valahogy, hogy a <category lang="hu"> -ban és a <date>-ben lévő tartalom bekerüljön zárójelbe a <sub-title lang="hu"> element végére így:
<sub-title lang="hu">Indonézia, Kelet-Szibéria, Alpe d'Huez, Kamakura, Essaouira (Ismeretterjesztő Sorozat, 1998)</sub-title>Gondolom nem olyan egyszerű, de hátha valaki csinált már ilyet vagy tud segítséget adni hogy induljak el.
-

repvez
addikt
válasz
sztanozs
#4315
üzenetére
már a CGPT-ben is van specializált phyton codolásra modul azon keresztül használom és amit ad kodot az hiba nélkül lefordul a legtöbb esetben csak nem mindig érti meg , hogy pontosan mit is szeretnék és emiatt lesz rossz a program.
DE mivel nem vagyok programozo igy nem tudom ugy megfogalmazni , hogy ne tudja másként értelmezni , de ha tudnám gondolom akkor már nem is kéne használnom mert meg tudnám oldani . -
repvez
addikt
Probálkozok a CGPT-vel, most már vannak szakositott modulok is benne, és már végre nincs a 2000 karakteres korlátja, csak napi bizonyos számu kérdést lehet feltenni az ingyenes verzionál, de legalább már értékelhető dolgokat kap az ember amikre lehet épitkezni is.
ÉS igy csináltattam is vele egy kis programot, de lenne egy kis kérdésem kérésem azokhoz akik képben vannak a python programozással. ha esetleg kedvet érezne valaki magában , hogy szeretne segiteni az keressen meg privátban. nekik gondolom csak egy egyszerü pár perces dolog lenne amivel én nem boldogulok és az AI-tól is hiába kérem a kijavitását mindig ugyan ugy nem müködik ahogy szeretném. nekem semmi tudásom nincs , hogy hogy tudnám megjavitani, csak futtatni tudom az IDE-ben .
A programban amugy minden megvan és mukodik amit gondoltam, csak vanank részek amik nem ugy ahogy kellene erre kéne valami megoldás. van amelyik csak pozicioban tér el van amelyik müködés ugyileg. -

moseras
tag
válasz
 Siriusb
#4310
üzenetére
Siriusb
#4310
üzenetére
Claude 3.5 Sonnet:
import datetime
import locale
from typing import Dictdef convert_date(iso_date: str, lang: str) -> str:
# Nyelvkódok és a hozzájuk tartozó locale-ok
language_locales: Dict[str, str] = {
'hu': 'hu_HU.UTF-8',
'en': 'en_US.UTF-8',
'de': 'de_DE.UTF-8',
'fr': 'fr_FR.UTF-8',
'es': 'es_ES.UTF-8'
}# Ellenőrizzük, hogy a megadott nyelv támogatott-e
if lang not in language_locales:
raise ValueError(f"Nem támogatott nyelv: {lang}")# Beállítjuk a megfelelő locale-t
locale.setlocale(locale.LC_TIME, language_locales[lang])# Konvertáljuk a dátumot
date = datetime.datetime.strptime(iso_date, "%Y-%m-%d")# Formázott dátum előállítása
formatted_date = date.strftime("%B %d")# Visszaállítjuk az eredeti locale-t
locale.setlocale(locale.LC_TIME, '')return formatted_date
# Példa használat
languages = ['hu', 'en', 'de', 'fr', 'es']
iso_date = '2024-07-09'for lang in languages:
try:
result = convert_date(iso_date, lang)
print(f"{lang}: {result}")
except ValueError as e:
print(f"Hiba: {e}") -
#4309
 animatrix11
őstag
sztanozs
#4308
animatrix11
őstag
sztanozs
#4308
-
#4308
sztanozs
veterán
animatrix11
#4307
sztanozs
veterán
válasz
 animatrix11
#4307
üzenetére
animatrix11
#4307
üzenetére
22. sor:
chats_file = open(f"chats_of_{self.phone_number}.txt", "w")
helyettchats_file = open(f"chats_of_{self.phone_number}.txt", "w", encoding="utf-8")ha a jelszoban is lehet ekezetes karakter, akkor a 73. es 85. sorban is javitando (a fentihez hasonloan)
-
#4305
animatrix11
őstag
galaxy55
#4304
animatrix11
őstag
válasz
galaxy55
#4304
üzenetére
ez egy telegram üzenet továbbító program ezt a hibát dobja:
Chat ID: -1001697412340, Title: Ben, Gold Trader
Chat ID: -1001765226347, Title: Ben, Gold Trader
Chat ID: -1001542422851, Title: GOLD Trader Mo🫅
Traceback (most recent call last):
File "C:\Users\user\Desktop\Telegram-Autoforwarder-master\TelegramForwarder.py", line 124, in <module>
asyncio.run(main())
File "C:\Program Files\Python312\Lib\asyncio\runners.py", line 194, in run
return runner.run(main)
^^^^^^^^^^^^^^^^
File "C:\Program Files\Python312\Lib\asyncio\runners.py", line 118, in run
return self._loop.run_until_complete(task)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "C:\Program Files\Python312\Lib\asyncio\base_events.py", line 687, in run_until_complete return future.result()
^^^^^^^^^^^^^^^
File "C:\Users\user\Desktop\Telegram-Autoforwarder-master\TelegramForwarder.py", line 111, in main
await forwarder.list_chats()
File "C:\Users\user\Desktop\Telegram-Autoforwarder-master\TelegramForwarder.py", line 26, in
list_chats
chats_file.write(f"Chat ID: {dialog.id}, Title: {dialog.title} \n")
File "C:\Program Files\Python312\Lib\encodings\cp1250.py", line 19, in encode
return codecs.charmap_encode(input,self.errors,encoding_table)[0]
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
UnicodeEncodeError: 'charmap' codec can't encode character '\U0001fac5' in position 46: character maps to <undefined>ezt hova kéne beillíszteni? # -*- coding: utf-8 -*-
-
#4303
animatrix11
őstag
animatrix11
őstag
Sziasztok
Segítséget kérnék, egy python scripthez utf-8 kódolás kéne, mert nem érti a különleges karaktereket, a google nem tudott segíteni benne, a kódba kéne valahogy beleírni, hogy utf-8-at használjon vagy be lehet valahogy állítani a python vagy vs code-on belül?
ezt szeretném használni: [link]
Előre is köszi! -








 Nagyon szépen köszönöm a segítséget
Nagyon szépen köszönöm a segítséget 
































Új hozzászólás Aktív témák
- Honor Magic6 Pro - kör közepén számok
- Kerékpárosok, bringások ide!
- Kettő együtt: Radeon RX 9070 és 9070 XT tesztje
- Túra és kirándulás topic
- Építő/felújító topik
- Samsung Galaxy S24 Ultra - ha működik, ne változtass!
- Filmvilág
- OLED TV topic
- NVIDIA GeForce RTX 5080 / 5090 (GB203 / 202)
- Samsung Galaxy Watch7 - kötelező kör
- További aktív témák...

- ÁRGARANCIA!Épített KomPhone Ryzen 7 5800X 32/64GB RAM RX 7800 XT 16GB GAMER PC termékbeszámítással
- BESZÁMÍTÁS! Apple Macbook Pro 15" 2019 i9 9980HK 32GB 500GB Radeon Pro 560X hibátlan működéssel
- BESZÁMÍTÁS! MSI B550 R7 3700X 16GB DDR4 512GB SSD RTX 3060Ti 8GB Rampage SHIVA Seasonic 650W
- Samsung Galaxy A22 5G 128GB, Kártyafüggetlen, 1 Év Garanciával
- AKCIÓ! Intel Core i7 4790K 4 mag 8 szál processzor garanciával hibátlan működéssel
Állásajánlatok

Cég: PCMENTOR SZERVIZ KFT.
Város: Budapest

Cég: Laptopszaki Kft.
Város: Budapest