Hirdetés
- Feháborodott az Apple, a Meta az iPhone-felhasználók üzeneteit akarja olvasgatni
- A luxusmárkáknak kell a bitcoin, az USA jegybankjának nem
- Letiltja az USA a politikusokat a telefonhívásokról és szöveges üzenetekről
- Nagy áttörés jön a napelemek piacán, nem kell annyi hely a paneleknek
- Belenyúlt az USA az Epic Games igazgatótanácsába, nyomoz az NVIDIA
- Tényleg betilthatja a TP-Linket az USA
- Telekom otthoni szolgáltatások (TV, internet, telefon)
- Milyen routert?
- Jelszókezelők
- Mozilla Firefox
- KAÜ/Ügyfélkapu – már elérhető a kétfaktoros hitelesítés
- Mikrotik routerek
- Feháborodott az Apple, a Meta az iPhone-felhasználók üzeneteit akarja olvasgatni
- Vivaldi (böngésző)
- PHP programozás
-

IT café
A legtöbb kérdésre (igen, talán arra is amit éppen feltenni készülsz) már jó eséllyel megtalálható a válasz valahol a topikban. Mielőtt írnál, lapozz vagy tekerj kicsit visszább, és/vagy használd bátran a keresőt a kérdésed kulcsszavaival!

Új hozzászólás Aktív témák
-

Abu85
HÁZIGAZDA
válasz
 Jack@l
#24125
üzenetére
Jack@l
#24125
üzenetére
Nyugodtan. Az EPIC roadmapjéből származik.
 Aki UE4-gyel akar DXR-t, annak magának kell implementálnia. Az EPIC egyhamar nem teszi ezt meg.
Aki UE4-gyel akar DXR-t, annak magának kell implementálnia. Az EPIC egyhamar nem teszi ezt meg.(#24126) b. : De az EPIC az nem az NV. Az UE4 az egy igen szabadon licencelhető motor. Az NV csinálhat hozzá magának DXR forkot, stb. Azt persze nem fogja támogatni az EPIC, de nem ez lenne az első, levégre van egy rakás GameWorks forkja az UE4-nek. Viszont az EPIC teljesen másképp működik. Ők nem foglalkoznak azzal, hogy az NV milyen mellékszálakat készít. Nekik van egy főverziójuk, és azt fejlesztik, azt támogatják is, stb. Ettől nem tiltják, hogy valaki egy alternatív forkot használjon, csak ha probléma van vele, akkor le se szarják, hogy nem működik.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
Én nem akarom ezért őket elítélni. Abból főznek amijük van.
Én csak azt hiányolom az RT kapcsán, hogy nem mutatták meg legalább egy rendelt játékon, hogy ez az RT mire is jó úgy istenigazából. Mert nem csak ilyen fis-fos effektekre használható ám.
Mint írtam én se költenék erre az AMD helyében, de ők úgy gondolják, hogy megéri és kész. Felőlem pénzelhetik, én csak nyerek rajta, mert ha veszek jobb VGA-t, akkor megnyílik egy új textúraminőség.

A Metro sem lesz más. Te még nem láttad, de van egy brosúra a DXR-ről, és ki van jelölve, hogy melyik kép a szebb.
 Ez nem véletlen, mert meg lett kérdezve az MS által egy rakás user, és sokan a DXR offot mondták szebbnek. Igazából alig látszik a hatása. Inkább úgy fogalmaznák, hogy a DXR on/off más, de egyik sem szebb a másiknál. Ezért is döntött sokszor az ízlés.
Ez nem véletlen, mert meg lett kérdezve az MS által egy rakás user, és sokan a DXR offot mondták szebbnek. Igazából alig látszik a hatása. Inkább úgy fogalmaznák, hogy a DXR on/off más, de egyik sem szebb a másiknál. Ezért is döntött sokszor az ízlés.Az UE4 egyhamar semmit. 2021-et fogunk írni mire ez final formában bele lesz integrálva a motorba. A probléma az, hogy az Epic átrakta a fókuszt a Vulkan API-ra, így a DirectX 12 leképező fejlesztéseire kevés erőforrás megy. Na és ide tartozik a DXR is. Ők inkább arra fókuszálnak, hogy majd a Vulkan RT verziójához legyen meg a támogatás, de az még sokára jön. Addig alpha szinten egy alternatív branchben elérhető akinek kell, de nem egy életbiztosítás a kód minősége.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
Mindegy, hogy a játék micsoda. A lényeg, hogy megmutassa, hogy a raytracing ér is valamit. Ha most megnézed a linkelt videó alatti hsz-eket, akkor látszik, hogy nem nagyon győzte meg az embereket. Legalább kellene egy cím, ami nem csak olyan effektekre használja, amihez nagyon hasonlót már láttál raszterizációval, ráadásul sokkal gyorsabban.
Nekem aztán mindegy, hogy egy cég rendel-e ultra textúracsomagot a normál fölé. Alapvetően csak jól járok vele, mert ha lesz elég VRAM-mal rendelkező kártyám, akkor van hova továbblépni. Addig pedig használom az alap textúrákat. Mondjuk ettől én még nem rendelnék textúracsomagot a fejlesztőktől, de magasról teszek rá, hogy az AMD mire költi a pénzét.
Igazából nincs baj ezzel a DXR-rel, csak szét lett hype-olva. Sokkal jobban jártak volna akkor, ha egy nulladik generációs fejlesztésnél nem nyomják meg ennyire a marketinggépezetet, mert akkor a userek sem várnának hatalmas technológiai áttörést, és ennek hiányában nem csalódnának.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
Mondjuk eleve óriási hiba volt ezt csak effektek szintjén használni. Árnyékokat, visszaverődést, AO-t tudunk csinálni raszterizálással is. Ezek minősége ráadásul nem annyival rosszabb, hogy a usert meggyőzze a DXR aktiválásáról, amitől jól be is zuhan a sebesség. Tehát a probléma pont az, hogy a raytracing aktuális felhasználása nem teremt új képminőségbeli dimenziót, miközben a hardvert meg nagyon durván lezabálja. Mondjuk ha érkezne legalább egy olyan játék, mint amilyen a PS4-en a Dreams, ami full raytracing pipeline, és tényleg jól épít is ennek a lehetőségeire, akkor látni lehetne, hogy ez az egész nem csak pár alig látható effektről szól. Őszintén szólva, ha az NV ezt a videót megnézi, akkor őket sem nagyon győzné meg, hogy a DXR On megéri a sebességvesztést.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
Érdemes elolvasni az iparági véleményeket. Itt van például Boris Vorontsové (ENBSeries fejlesztője), aki ugye kb. ezzel foglalkozik, tehát nem csak irkál.
"...raytrace is just a marketing lie, which is too slow and will be slow for many years, because highly depends from memory bandwidth, all demos presented have various ways to degrade quality to have playable performance instead of slide show. There are no effects which can have any benefits from raytracing when doing modding and which cant be replaced by existing techinques, only unique games with their own features have a chances to have something better, but after all users will not notice the difference."Egyébként ki lehet számolni, hogy mekkora a szükséges terhelés, hiszen az NVIDIA nem titkolja, hogy egy 2080 Ti 10 Gigarays/s-re képes, amihez egy értékelhető BVH8 (ennyi kellene a mai geometriáknak) mellett 5,6 TB/s az optimális. A hétszintű BVH ~80 bájt (szintén nem titok, hiszen szabványról van szó), vagyis 10 (Gigarays/s) * ~80 (bájt) * 7 (szint - BVH8) = 5600 GB/s
Emiatt van az, hogy az új 3DMark geometriailag olyan bitang egyszerű, illetve emiatt vannak a BF5-ben külön RTRT-hez szabott geometriák a visszaverődésre (a raszterizációhoz használt normál geometriával nem működne). Ha nem viszik le a geometriát annyira, hogy beférjen BVH4-be, vagy alá, akkor rohadtul nincs meg a sávszél.Boris egy kicsit nyersen fogalmaz, ők konkrétan marketinghazugságnak tartja. Én azért eddig nem mennék, megvan a hasznossága, csak még nem tartanak ott a hardverek, hogy ez tényleg nagy dolog legyen. Visszaverődést, GI-t, AO-t, árnyékokat eddig is tudtunk csinálni. Abban igaza van Borisnak, hogy akkor lesz ez igazán érdekes, ha ezekre egyedi játékok fognak épülni. Viszont abban meg a gyártóknak van igaza, hogy amíg nincsenek ott a hardverek a felhasználóknál, addig egyedi játékok sem fognak jönni. Tehát valahogy el kell juttatni a hardvereket a felhasználókhoz, hogy változás legyen. Ez persze két-három éves procedúra, de lehet, hogy fél évtized lesz, viszont lassan ott leszünk, hogy ne csak hülyeségekre alkalmazzuk, hanem legyen haszna is a sugárkövetésnek. Az eltelő időben még a memória-sávszélesség is fel fog nőni a feladathoz, közben jöhet egy új DXR, ami már nem csak a háromszögeken működik, hanem mondjuk voxeleken is, stb. Most van egy nulladik generációnk, ami szükséges ahhoz, hogy ebből valaha legyen valami. Másképp sajnos nem megy, előbb mindig a hardver kell, aztán jön a szoftver. Nem a kamuszoftver, hanem a tényleg innovatív ötleteket hozó. Én azt is elfogadom, hogy valaki csalódott, nem az RTRT hibája ez, hanem a hype-é. Valójában a technika nagyon jó, csak egy kis időt kell neki adni.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
Jó, oké, de ugye alapvetően kb. ugyanez a primitive shader. Vagyis az AMD és az NV is csinált egy új pipeline-t, ami nagyon hasonlít egymásra. Tehát a háttérben azért lehet már valamiféle egyeztetés, hogy egy DirectX verzióban jöhet erre egy szabvány. A Microsoft esetleg képes is lenne ehhez eszközöket készíteni, hogy a legacy támogatás meglegyen, ugye felvásárolták a Sympligont.
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
#23539
Abu85
HÁZIGAZDA
huskydog17
#23531
Abu85
HÁZIGAZDA
válasz
 huskydog17
#23531
üzenetére
huskydog17
#23531
üzenetére
Eredetileg 16:00, de mindegy. Tegnap két órát reszeltek rajta, csak nem szóltak mindenkinek. Ezeket az utolsó pillanatos változásokat imádom még...
(#23538) b. : Nem. A Titan V marad. Ez csak úgy jön mellé olcsóbban.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
#23527
Abu85
HÁZIGAZDA
- = Zk = -
#23522
Abu85
HÁZIGAZDA
válasz
 - = Zk = -
#23522
üzenetére
- = Zk = -
#23522
üzenetére
Megint marhára be van tartva az NDA természetesen.

Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
Sejtem, hogy mi van itt. A 415-ös driversorozattal párhuzamosan jött az októberi frissítés. Sokan egyszerre telepítették. Sokaknak HT-s a procijuk, és nagyon úgy néz ki, hogy az októberi Win 10 frissítés olyan mikrokódot és javításokat tartalmaz, ami nagyon betesz a HT-nek. Innen jön a lassulás. Még a Linux frissítésével is kapott vagy -50%-ot az Intel, Torvalds mondta is, hogy ez már túl sok, itt már opcionálisnak kellene lennie a javításnak (amivel egyébként egyetértek... értem, hogy a biztonság az első, de a teljesítmény felét ott kellene hagyni ezért egy HT-s procinál? ...ez már megfontolandó). Na a játékokban valószínűleg azok beszélnek lassításról, akik egyszerre telepítettek minden frissítést, és a HT-s procijuk megkapta a Microsoft "büntetését". De persze erre ugye miért is gondolnának, nyilván logikusabb, hogy az NV drivere lassít.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
válasz
 Raymond
#22447
üzenetére
Raymond
#22447
üzenetére
Egészen pontosan 16% Full HD-ben egy RX 580-on. A többi beállítástól összesen nem esik ennyit az említett GPU. Persze azt nem tartom kizártnak, hogy más hardverrel mások az arányok. A lényeg, hogy nem összemérhető. Ezt én néztem el, sry érte.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
válasz
Raymond
#22445
üzenetére
Láttam. Ezek közül a 2xAA, ami eléggé számít, hiszen gyakorlatilag dupla annyi mintát veszel rá, de ez nem volt aktív a videóban, helyette pár beállítás volt jobb az FXAA mellett, ami a 2xAA-nál egy kevésbé terhelő AA. Végeredményben nem összehasonlítható. Én a 2xAA-nál nem néztem tovább, mert az már annyira nagy különbség a noAA-hoz képest, hogy önmagában nem teszi lehetségessé az összemérést.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
válasz
Raymond
#22443
üzenetére
Uh tényleg. Az AMD beállításainál volt 2xMSAA. A fenében. Akkor nem összehasonlítható.
Akkor mitől táltosodik meg és közelíti meg 1080p-ben is a Vega 64-et az 1080 Ti egy 16-magos Threadripperrel, ha nincs CPU-limit? Valami oka csak van.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
Tegnap erről szólt a hír: [link]
Azzal, hogy az NVIDIA emulálja az UAV-k és az CBV-k limit nélküli bekötését, a processzort használják fel, így nem tisztán hardveres a megoldás. Működik, de a CPU terhelése nagyobb lesz egy tényleg hardveres szinten bindless architektúrához képest, mint amilyen a Turing vagy a GCN. Ezért volt köcsög húzás az AMD-től, négymagos Core i7-tel tesztelni, mert tudták, hogy ezzel ők nem futnak procilimitbe ott, ahol a Pascal már vagy még limites.
Szerintem amúgy a Turing még gyorsabb is lehet. Azért nagyon számít, hogy az NVIDIA-nak most lett egy minden erőforrást bindless szinten kezelő hardvere. Erre valószínűleg korábban nem optimalizáltak, míg az AMD a kezdetektől mindent erre ír, és azért nem mindegy, hogy a meghajtót öt éve optimalizálják, vagy még csak most kezdtek neki.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
A CPU-limit 4K-ban kisebb. Igazából 1080p-ben is hozza a 4K-s eredményt a Pascal, ha rakasz alá egy Threadrippert. De négymagossal jóval hamarabb CPU-limitbe ütközik.
(#22439) b. : Na ez jó! A proci ugyanaz, amit az AMD használt. Mindjárt felütöm a review guide-jukat, és bemásolom az eredményeket.
Szerk.: Ultra, ahogy nézem a beállítás ugyanaz volt:
Vega 64 LC:
1080p: 130
1440p: 105
2160p: 69Vega 64:
1080p: 125
1440p: 100
2160p: 681080 Ti:
1080p: 104
1440p: 89
2160p: 662080:
1080p: 126
1440p: 101
2160p: 65Az látszik, hogy a Turingnak nincs meg a CPU-limitje 1080p-ben és 1440p-ben.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
-
Abu85
HÁZIGAZDA
Nem erről van szó. Persze jól fut, még egy jóval lassabb GPU-n is szakít. Itt viszont arról van a vita, hogy az NVIDIA igen könnyen meg tudja azt oldani, hogy a Turing jobb vétel legyen, mint ma, mert csak annyit kell tenni, hogy engedik a Microsoft DirectX 12-re vonatkozó ajánlásait érvényesülni, és máris nő az olló a Turing javára. A Forza Horizon 4-ben nem az AMD gyors, hanem a Pascal lassú, és ezt a lassúságot nem nehéz átvinni más játékba is. Minden az NVIDIA döntése. Ha úgy gondolják tehát, hogy a Turingnak nagyobb előny kell, akkor a Pascal nagyon egyszerűen visszafogható. És még a potenciális támadások is könnyen lepergethetők, mert az NV mutogathat a fejlesztőkre, hogy ők nem írják az alkalmazásokat az ajánlásaik szerint. A fejlesztő pedig mondja, hogy ők mindent úgy csinálnak, ahogy a Microsoft előírja. Ezen van a vita, hogy az NVIDIA ehhez az eszközhöz hozzányúl-e vagy sem.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
Adott ki hozzá driver. A 399.07-be került be a profil és azóta ugyanaz van mindegyik meghajtóban. A 411.63-asnál be is jelentették, hogy benne van a csomagban a profil, plusz pár shadert lecseréltek (apró grafikai hibák miatt). Szóval nem igaz, hogy nincs rá támogatás a meghajtóban.
A Microsoft manapság több héttel a megjelenés előtt leadja a gyártóknak a végleges kódot. Már az Intel meghajtójában is ott van a profil, holott ők jellemzően a legutolsók ebben. Ez azért van egyébként így, mert április óta az AAA Windows Store játékokhoz WHCK-val hitelesített meghajtókat vár el a startra a Microsoft, amibe belementek a gyártók, de ehhez azt kérték, hogy akkor a játékot kapják meg sokkal a start előtt, hogy tudjanak hozzá profilt csinálni.[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
válasz
Jack@l
#22428
üzenetére
És ezért tudja a Vulkan alatt a kísérleti raytracing kiterjesztést gyorsítani a Pascal...
Egy csomó eleme van a raytracing futószalagnak, amelyek alapvetően gyorsíthatók a mai hardvereken is. Ezért ajánlja azt a Microsoft, hogy legyen egy natív meghajtó, ami kiváltja a fallback layert, mert utóbbi minden lépcsőt a compute shadereken futtat. Az, hogy a Pascal ide került az NV-nél egy tisztán üzleti döntés volt. Technikailag kaphatna ugyanúgy natív támogatást, ahogy Vulkan alatt.
Alapvetően a gyártók szabad döntése az, hogy a fallback layerre hagyatkoznak-e vagy írnak natív támogatást. Az NV a Volta és a Turingra ír implementációt, míg a többi megy a fallbackre. Egyébként az AMD sem nagyon pörgeti azt, hogy minden GCN-re natív legyen az implementáció, noha nem tagadják, hogy lehetne, de anyagilag nem kifizetődő öt generációnyi architektúrát lefedni. Ezért lehet, hogy csak az utolsó három generáció lesz natívan kezelve az első kettő pedig megy a fallbackre. Ez is egy üzleti döntés lesz leginkább.
(#22429) b. : Meg a Vega 56 is gyorsabb eléggé, de ha nem akarod látni, akkor ne lásd. Ettől még ott van. Az is látszik, hogy ahogy emeled a felbontást, ahogy szűnik meg a CPU-limit, jön fel a GeForce. Ezt az NVIDIA bármikor meg tudja játszani, és rögtön sokkal jobb vétel lesz a Turing, mint amilyen ma.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
[link] - nem az oldallal van a baj jelen esetben. Ez az erősorrend, ha nem az NV ajánlásai szerint írják az optimalizálást. Ha ugye nem lenne ezzel probléma, akkor a Turing erőforrás-kezelése sem változott volna meg.
16-magos Threadripperrel már feljönnek, mert eltűnik a processzorlimit, de 4K-ban is jobbak az eredmények. Alapvetően a Full HD az, ahol a driver limitálja a GeForce-okat.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
Senki se mondta, hogy játszhatatlan lesz, de nézd meg a Forza Horizon 4-et, amit nem az NV ajánlásai alapján írtak. [link] - és ezekre már nagyrészt immunis a Turing, tehát nem annyira kritikus az NV-nek az, hogy sok szempontból ne kövessék a fejlesztők az ajánlásaikat. Az persze nagy kérdés, hogy ők mit akarnak, de rém egyszerű a Pascal teljesítményét visszafogni, és alapvetően bele sem lehet majd kötni, mert az NV majd védekezik azzal, hogy a fejlesztők csak azt csinálták, amit a Microsoft ajánl.
A raytracinget nem kell licencelni, az a DX12-nek egy kiegészítése. Az AMD is ír rá implementációt, de ők erről akkor beszélnek, amikor hozzák az év végi nagy frissítést, abban lesz többféle megoldás erre a Radeonokra és a Ryzenekre. Egyébként Pascal is tudná a futószalag egyes lépcsőit gyorsítani, tehát alapvetően az, hogy ezek a fallback layeren futnak már egy üzleti döntés az NV részéről, nem pedig egy technikai limit. Futhatnának natívan, mert például Vulkan alatt a Pascal gyorsítja a raytracinget a kísérleti kiterjesztéssel.
(#22421) b. : Azért ne tekintsük úgy, hogy a Microsoft erőforrás-kezelésre vonatkozó ajánlásai feleslegesek lennének. Az NV is tudta, hogy hiába ajánlják azt, hogy az UAV-ket és az SRV-ket is helyezzék az RS-be, ha olyan formátumot használ a program, ami direkten az RS nem is kezel. Ez ideig óráig jó volt, de nem lehet örökké komoly korlátok között élni, márpedig az elég nagy korlát, hogy bizonyos UAV és SRV formátumokat nem is lehet használni, mert ellenkezik az NV ajánlásaival. A Forza Horizon 4-et sem direkt írták lassúra a Pascalon, csupán eljutott a motor fejlesztése egy olyan szintre, ami már nem ideális a Pascalnak. Alapvető fejlődés van itt, ami az NV-nek sem baj már, mert van Turing, ami már jó ilyen környezetben is. Lehet persze, hogy a mai kódokban még nincs igazán rá optimalizálás, de a hardvernek működnie kell ott, ahol a Pascal már nem kevés teljesítményt veszít.
Én nem tartom azt valószínűnek, hogy az NV most direkt nokiás dobozokat visz a fejlesztőkhöz, hogy mégis a Microsoft ajánlásai a jók. Ellenben az bőven elképzelhető, hogy különösebben erre már nem fordítanak figyelmet, így mindenki eléggé szabadon eldöntheti, hogy milyen leképezőt ír. Ha olyat ami fáj a Pascalnak, akkor az egy vállvonás lesz, ha olyat ami jó a Pascalnak, akkor az is jó, a Turingnak baja ebből sincs.
A Pascalt, Maxwellt, Keplert egyébként ettől még támogatni fogják, és a GCN-t is támogatja az összes driver. Ez nem erről szól, hanem arról, hogy bizonyos optimalizálási megoldásokra mi mennyire érzékeny. A programfuttatást ez nem befolyásolja.[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
Elég azt mondaniuk, hogy próbálták a fejlesztőket lebeszélni róla, de ők a Microsoft ajánlásait követik. Az eredmény mínusz 10-30% a Pascalnak, pedig az NV minden megtett, hogy ez ne így legyen, de sajnos olyan formátumokhoz nyúltak, amire nem optimális a Pascal. Szánjuk-bánjuk, esetleg tudjuk ajánlani a 2000-es sorozatot...
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
A hirdetés nem egyenlő az üzleti kapcsolattal. Sokkal bonyolultabb ez, ahogy azt ti elgondoljátok. Egy áruház nem fog csak úgy kérésre teszthardvert adni a PH-nak sem, előbb szerződést kell kötni velük erre, hogy bizonyos szituációkban kié a felelősség, stb... ugyanis egy eladásra váró termék lesz felbontva. És azt sokszor nem tudod ám teljes árúként eladni.
Ráadásul RTX-ből alig jön a régióba, szóval ez is nehezíti a dolgokat. Kb. olyan szintű a helyzet, mint a Titan V-nél. 2070-nél lehet egyszerűbb a dolog, mert abból jóval nagyobb a tesztkészlet is.(#22201) lenox: A független azt jelenti, hogy a termék biztosítója, illetve gyártója semmilyen formában nem határozhatja meg a cikk tartalmát. A GeForce Garage tagság azért nem jó nekünk, mert annak vannak olyan kötöttségei, hogy milyen beállításokkal lehet csak tesztelni, milyen játékokat kell hanyagolni, milyen lehet a tesztgép, stb. Ez már meghatározza a tartalmat. Úgy tudom, hogy a GeForce Garage nem egy tesztoldalaknak szánt koncepció, hanem a YouTube-reknek, a moddingosoknak, és ezért vannak erre ilyen megkötések, de mivel az NV bizonyos régiókra nem tekint értékelhetőként, így néha csak ez az egyetlen módja a teszthardver beszerzésének. De mi azért lettünk az ország legerősebb médiája, mert nem hagyjuk, hogy beleszóljon a gyártó a tesztekbe. Igazából nem is akarnak, tényleg nem erre való a GeForce Garage, de van olyan média, ami bevállalja, mert más országban azért a hazainál jóval erősebb verseny van a médiák között. Ha mondjuk lenne egy erős konkurenciánk, akkor természetesen lehet, hogy nem ragaszkodnánk ennyire szigorúan a függetlenségre vonatkozó elveinkhez.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
Az nem piac úgy. Itt azért hozni kellene ennél több eladást is havonta, hogy ez egy értékelhető terület legyen, és visszahozzák a régió direkt supportját, egy PR cégen keresztüli kvázi tessék-lássék jelenlét helyett. De ezeket nehéz elvárni. Volt itt Intel Magyarország is, aztán ma már nincs. Ők is eléggé kivonultak, tehát ez nem az NV hibája. Ők megnézték a régiós számokat, és azt állapították meg, hogy nem éri meg. Ettől a kártyákat behozzák, de különösebb régiós jelenlétet nem kívánnak felmutatni annak a kevés vásárlóerőnek. Egyedül az AMD maradt meg direkt supportnál, de ők is csak azért, mert Szerbiában van egy központjuk. Ha az nem lenne, akkor kb. ők is szerveznék ki a jelenlétet egy PR ügynökségnek.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
válasz
 NewHope88
#22159
üzenetére
NewHope88
#22159
üzenetére
Senki se kapott a régióban. Nem célpiac, nem tudja ezeket az árakat megfizetni a régió. Maga a képviselet is eléggé ki lett vonva a régióból. Egy cseh PR cég van megbízva ezzel (nem nagyon törődnek vele
 ), holott korábban az NV ezzel a régióval direkten foglalkozott. Viccesen hangzik, de a Turing cikket úgy raktuk össze, hogy az NV egyik konkurensétől kaptuk meg a whitepapert, mert az ezzel megbízott cég nem törődött vele. Kb. itt áll jelenleg az NV régióhoz fűződő viszonya. Azok tudnak időre kártyákat szerezni, akik GeForce Garage partnerek, csak az ugye elég sok kötöttséggel jár, így nem tudnánk független teszteket készíteni.
), holott korábban az NV ezzel a régióval direkten foglalkozott. Viccesen hangzik, de a Turing cikket úgy raktuk össze, hogy az NV egyik konkurensétől kaptuk meg a whitepapert, mert az ezzel megbízott cég nem törődött vele. Kb. itt áll jelenleg az NV régióhoz fűződő viszonya. Azok tudnak időre kártyákat szerezni, akik GeForce Garage partnerek, csak az ugye elég sok kötöttséggel jár, így nem tudnánk független teszteket készíteni.[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
#22158
Abu85
HÁZIGAZDA
Depression
#22157
Abu85
HÁZIGAZDA
válasz
 Depression
#22157
üzenetére
Depression
#22157
üzenetére
Magyarország nem célpiac, így nem kritikus tényező ide első körben kártyákat küldeni. Emiatt nincs még egyetlen magyar teszt sem. Leginkább majd a gyártók (például ASUS) fognak ide lerakni pár VGA-t.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
#21956
Abu85
HÁZIGAZDA
Menthirist
#21916
Abu85
HÁZIGAZDA
válasz
 Menthirist
#21916
üzenetére
Menthirist
#21916
üzenetére
Mert a Doomba nem portolták vissza a Variable Rate Shadinget. Ez gyakorlatilag lehetővé teszi, hogy az árnyalás ne a teljes felbontáson történjen meg, így a hardver jóval kevesebbet számol, de persze jóval kevesebb adatból is készül el a képkocka. Viszont a Wolf 2-be ez úgy lett belerakva, hogy kikapcsolhatatlan, tehát nem tudod elérni a natív számítási minőséget Turinggal. Ezzel a funkcióval már december óta kísérletezik az id Software. Valószínű, hogy egy hiba miatt lett aktív az 1.08-as patch-től, mert alapvetően nem kellene annak lennie, de most már mindegy. Majd jön hozzá egy patch, ami ki-be kapcsolhatóvá teszi. Esetleg driverből kilövik.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
Senki sem kap tuningra tesztelt GPU-t. Ez úgy működik, hogy megvan a lapka tokozott formában, és arra van egy gép, ami azt képes tesztelni, de az a gép a referenciaparaméterekre van állítva. Az NV-t például egyáltalán nem érdekli, hogy 100-200 MHz van még benne, mert ők nem arra vállalnak garanciát. Ha a lapka tudja a referenciát, akkor eladható egy adott termékbe. Onnantól kezdve az NV leveszi róla a kezét, a gyártópartner azt tesztel még amit akar, de olyan költséges ezt megoldani, hogy manapság nem így működik a gyártás. Ehelyett az NV-nek van egy adatbázisa arról, hogy az adott leszállított lapka a wafer melyik részéről származott. Ez alapján szoktak döntést hozni a gyártók, hogy mi hova kerül, de mélyreható tesztelés nem igazán van, mert nagyságrendekkel kisebb költség bevállalni azt, hogy a gyári tuningos VGA nem stabil, és azt cserélni garanciában, mint egyenként végigtesztelni mindenen a beállítható órajeleket. A nem stabil VGA visszamegy, és eladják referenciaként. Ezért van annyiféle sorozat a gyártóknál, hogy ha kiadnak egy nem stabil gyári tuningost, akkor azt el tudják adni újra, csak egy új BIOS kelljen rá, esetleg hűtőcsere.
Ez minden cégnél így működik, mert tesztelni mocskosul drága, garanciáztatni nagyságrendekkel olcsóbb, és azt kell itt mérlegelni, hogy bevállalod-e 10 kártya nagyon drága tesztelését, miközben a statisztika azt mutatja, hogy abból 7-8 jó lesz, 2-3 pedig majd visszajön gariba, és eladható egy kategóriával lejjebb. Logisztikai költsége ennek is lesz, de arányaiban sokkal-sokkal kellemesebb, mint mélyrehatóan, napokig tesztelgetni mindent.
Persze a gyártók nyomják a vakert, hogy nálunk tesztelés és válogatás van, és nagyon figyelnek erre, de amíg nem látod a kártya árcéduláján a 2000-2500 dollárt, addig ez kamu, mert iszonyatos humánerőforrást igényelne az, hogy napokig méregetik egy VGA stabilitását, miközben nagyjából a garanciára visszaküldött áruk fele lenne megspórolható vele. És persze az a fele nem kevés, de ez még mindig nagyságrendekkel kisebb költség, mint a szükséges erőforrást beleölni a mélyreható tesztelésbe.[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
Tekintve, hogy mennyire sokat javította az SR-IOV az üzemeltetési költségeken ez a rendszer működőképes lesz pár éven belül. Valószínűleg olyasmi lesz, amilyen ma a tévé. Lesznek a nagyobb cégek, akik adják a szolgáltatást, és a helyi internetszolgáltatók nekik fizetnek licencet a szoftverükért, illetve a hardverért, amit majd használhatnak.
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
A felhős játék ugyanott áll technikailag. A probléma még mindig a késleltetés. Egyelőre nincs igazán megoldás rá. A LiquidSky-nak van egy olyan terve, hogy 4-5 világszintű központ helyett minden nagyobb város mellett lesz egy-egy kisebb központ. Ez drasztikusan csökkenti a késleltetést, hiszen a legtöbb emberhez 50 km-en belül lesz a szolgáltatás a mostani átlag 1500 km helyett. Ehhez viszont várni kell 2020-ig, mert akkor dobják ki a régi rendszereket, és onnan áttérnek az új hardverekre. Azokkal igen kedvező üzemeltetési költség mellett lehet kitermelni egy kisebb központ fenntartását is.
Amíg viszont van régi, GPU-t userekhez dedikáló rendszer, addig ez nem vezethető be, mert a régi rendszerek fenntartási költsége sokkal magasabb, mint az új SR-IOV-s megoldásoké.[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
Cserében sokkal drágább egy jól működő netkód.
 Plusz az online rész folyamatos üzemeltetési költsége.
Plusz az online rész folyamatos üzemeltetési költsége.(#20881) Keldor papa: A PhysX eléggé torz módon fejlődött. Amíg az Ageia birtokában volt alapvetően egy olyan újításként gondolták el, ami változtat a játékmeneten is. Amint az NV tulajdonába került, teljesen más lett a koncepció, és mivel az új irányok kifejezetten ártanak a PhysX-nek, így egy ideje a pénzt is kivették a fejlesztése mögül. Szóval meg lehetne ezt ma is csinálni, de alapvetően az NVIDIA-t már nem érdekli, nem támogatják többet, így pedig értelmetlen pénzt rakni bele a fejlesztői oldalról.
A legnagyobb probléma az, hogy maga a middleware egy zárt kód. A működéséhez szükség van a meghajtóban a modulra, de az NV egyre gyorsabban műti ki a régebbi runtime-okat a driverből, ami után a program többet nem fog működni. Egy fejlesztőnek alapvetően az a legjobb megoldás, hogy ha kiadnak valamit, akkor az működjön 5-10 év múlva is, ne csak addig, amíg az NVIDIA szíveskedik a szükséges runtime-ot szállítani. Itt érdemes a Warframe problémáit figyelembe venni. [link] - ilyen formában ez nem működik, mert eljut oda az NV, hogy a régi runtime-okat már nem támogatja, így az ezekre írt kódok alól kihúzzák a talajt. És igazából a fejlesztő ezzel nem tud mit kezdeni, mert a forráskódot nem adják oda, hogy újra működésre bírják a rendszert, szóval ha az NV azt mondja, hogy viszlát effekt, akkor viszlát van, és nem lehet ellene tenni semmit. Emiatt döglődik igazán a PhysX, mert gyakorlatilag 5-6 éves működést építesz ki, aztán a runtime eltűnik a meghajtóból, és futtathatatlan lesz a kód.[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
válasz
 keIdor
#20753
üzenetére
keIdor
#20753
üzenetére
A Navi egy a Vega utód lesz. A Polaris más kódolási sémát használt.
Az Intelnek az az egyszerű, hogy nem kell letenni versenyképes terméket. Egyszerűen fogják a GPU-jukat és rárakják a négymagos CPU-k tokozására. Jól megkérik az árát érte, és akkor majd a notebookgyártó gondolkodik, hogy ha már ezt kifizették, akkor tényleg vegyenek a helyére még egy GPU-t? Mert nyilván az Intel nem fogja visszaadni a pénzt, ha a hardvert nem használják. Régóta ez a stratégia, árazópisztolyt tartanak az OEM-ek fejéhez. Itt elég ha tök utolsó vagy, az árazópisztoly elintézi a többit.
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
válasz
Jack@l
#20734
üzenetére
Nem. Az számít, hogy mennyire mély a hierarchia. Ha hét szintnél mélyebb, akkor még több sávszél kell. Az a lényeg, hogy az igény gyakorlatilag a hardver sugárfeldolgozási teljesítménye szorozva a BVH node adatmennyiségével (compressed BVH8 esetében ~80 bájt) szorozva a hierarchia mélységével. Még ha nem is mély a hierarchia, akkor is minimum 800 GB/s kell 10 Gigarays/s-hoz, de ilyenkor nagyon kell ám spórolni a háromszögekkel, és ugye a többi számítás sávszéligénye ebben még nincs is benne.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
válasz
Jack@l
#20731
üzenetére
Mert egy BVH node 80 bájt: [link]
Na most megfelelő poligonszám mellett, ami úgy 1-1,5 millió legalább hét szinttel kell számolni, vagyis egy sugár 560 bájtnyi adat feldolgozását jelenti. Ha egy GPU 10 milliárd sugarat tud feldolgozni másodpercenként, akkor ahhoz úgy 5,6 TB/s-nyi sávszél kell, hogy optimálisan kiszolgál. De tényleg nem kell hozzá sávszél.
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
válasz
Jack@l
#20725
üzenetére
A DXR-nek az a lényege, hogy nem a fejlesztőnek kell megírni compute shaderben azt a futószalagot, ami működteti az egészet, hanem előre meg van szabva. Innentől már csak az említett shader lépcsőkre kell shadereket írni.
Majd 20 TB/s-os sávszélnél erre visszatérünk, de addig kell raszterizálás.
(#20726) Segal: A lényegen nem változtat persze, de fontos tudni, hogy az OS hiányzik.
(#20727) Depression: Tesztelni ettől még lehet, csak DXR nem lesz. Ezzel tényleg nagyon nehéz mit kezdeni OS hiányában.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
BF1-ben egy GPU mellett semmi. Több GPU mellett valamivel jobb a DX12 skálázódása, persze jönnek a problémák is ugye. De amúgy sakal83 BF V-öt írt.
(#20689) Jack@l: Valahova bele kell írnod a pixelpozícióból a sugarak generálását, illetve a hit pointok árnyalását, esetlegesen onnan rekurzív sugarak generálását. Ezt egy megfelelő specifikációjú DXIL kód nélkül nem csinálja meg a DirectX Raytracing, nem tudja mi alapján dolgozzon. Alapvetően három lépcsőre épül a szabvány. A sugár generálása, a geometriával való "ütközés" definiálása, illetve egy viszonylag nagy lépcső, amely magába foglalja azt, hogy mit tegyen a rendszer, ha a sugár sose ütközik geometriába, illetve csak egy geometriáig számítson a sugár, vagy több geometriát is vegyen figyelembe. Utóbbi ugye az átlátszóságnál hasznos. Ezeket nem fogja a GPU magától kitalálni, és futtatni az FP32-es ALU-kon. Meg kell írni a kódot, hogy működjön.
Az anyagoknak a programkódhoz sok közük nincs. A végeredményt persze befolyásolják, de azért nem túl nagy meglepetés, hogy a raszterizáláshoz szabott PBR pipeline-ok nem mindig adnak jó eredményt sugárkövetéssel. Ez nem egy programkódban megbúvó probléma, szimplán nem úgy alakították ki a mai motorok futószalagját, hogy sugárkövetést fognak csinálni. Majd 5-6 év múlva már erre felkészített rendszerek lesznek.
És a DXR-en kívül melyik alternatív megoldásnak van teljes interoperability-je a DirectX API-val? Na ezért kell a DXR.
Teljes interoperability nélkül nem működne a raszterizálás a sugárkövetés mellett. Vagy az egyik menne vagy a másik, de együtt nem.(#20723) Segal: Éppenséggel tudnának kódot szállítani a megjelenésre mondjuk az új Tomb Raidernél, de amíg meg nem jön a Windows 10 októberi frissítése, addig nincs meg a futtatási környezet az operációs rendszerben, amivel ez a kód egyáltalán le tud futni. A Microsoft pedig a DXR 0.9-es specifikációt nem hitelesíti, arra hiába fordítanak kódot, egyrészt nem lesz kompatibilis a DXR 1.0-s környezettel, amit az októberi Windows 10 kap meg, másrészt a Windows 10 áprilisi frissítésében is csak developer módban futnak le ezek a kódok, tehát addig nem, amíg a user át nem kapcsolja a rendszert a normál, felhasználói módból.
Itt alapvetően az OS-nek hiányzik az a komponense, ami ezeket lehetővé teszi. Amint októberben elérhető lesz, a játékosok frissíthetnek a legújabb Windows 10 csomagra, és működni fog a DXR.[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
válasz
sakal83
#20684
üzenetére
Hogyan futtatod a DXR shadereket DXIL futtatási környezet nélkül? Na kb. ezért kellene erre erőforrást költeni, mert DX11-ben bizony csak a D3BC IR van támogatva, abba pedig nem lehet DXR shadert fordítani. Tehát a BF5 sokat reklámozott réjtrészing húzófícsőre egy olyan leképezőhöz van kötve, ami csúnyán akadozik. Persze elleszünk a DX11-en réjtrészing nélkül, mert menni fog, emellett a motor is GPU-driven pipeline, szóval alig dolgozik rajzolási paranccsal, így a DX11 és szépen skálázható. De ettől, ha valamit fejlesztenek, azt érdemes használható formába is önteni. Ha nem az, akkor vegyék ki és kész.
(#20683) Keldor papa: Akkor lesz Battlefield 6.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
válasz
Jack@l
#20681
üzenetére
DX12-ben a GeForce-okon 0 MB-nyi a VRAM-on az a terület, ahova host visible flaggel menthetők pufferek. A Radeonon ez 256 MB-nyi, de amúgy ez sem elég, 100-150 MB-ot mindenképpen a RAM-ba kell menteni, mert nem férsz bele 256 MB-nyi host visible típusba a VRAM-on belül.
Az a baj, hogy csak a hardvert nézitek, amin van 6-8-10-akárhány GB, de igazából kitörölheti a Frostbite ezzel a seggét, ha ebből csak 256, vagy rosszabb esetben 0 MB, az ahova a CPU direkte írhat puffert. Márpedig a Mantle miatt a Frostbite eleve úgy lett felépítve, hogy ezt a fajta CPU ír a VRAM-ba, a GPU pedig olvas modellt követi. Csak annyi változott, hogy amíg Mantle esetében a teljes VRAM host visible volt, addig a DX12 és a Vulkan ezt nem igazán szereti. És persze visszavették ezeket a puffereket 300-400 MB-nyira, de ettől még ott vannak, és az olvasásukhoz a rendszermemóriáig kell vágtatni.
Amikor a DX12-t nézitek, akkor érdemes inkább ezt nézni, mert nem a nyers mennyiség határozza meg igazán a működést, hanem a memória strukturális felbontása:
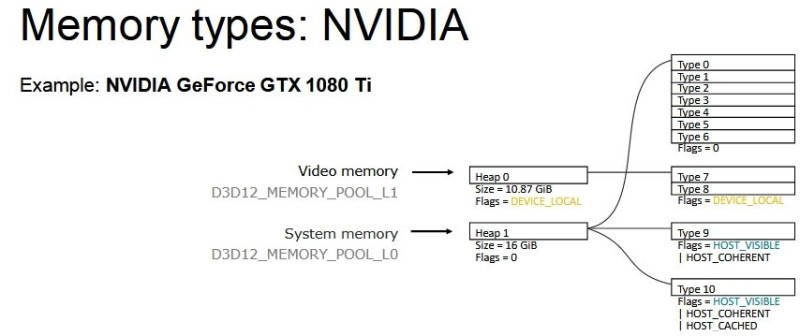
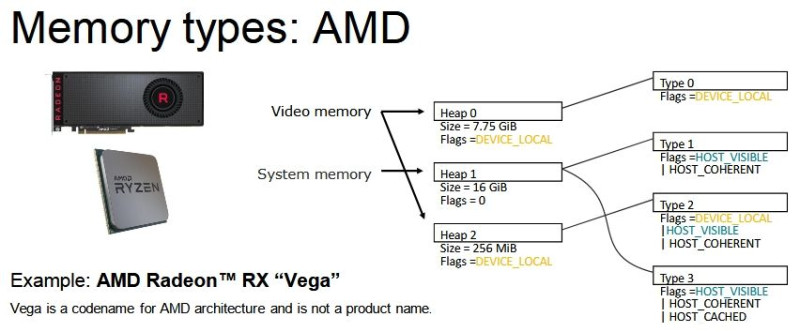

[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
#20677
Abu85
HÁZIGAZDA
FollowTheORI
#20675
Abu85
HÁZIGAZDA
válasz
 FollowTheORI
#20675
üzenetére
FollowTheORI
#20675
üzenetére
Az NV-nek nincs köze ehhez.
Azért azt látni kell, hogy itt tényleg a Frostbite a gond. Mindenki, aki használt Mantle-t, újraírta a memóriamenedzsmentet DX12-re. Egyedül a Frostbite ragaszkodik egy eléggé bonyolult modellhez, ami már Mantle alatt is köhögött, ha kevés volt a VRAM. Ezt a kódot csak tologatják maguk előtt, mert ha újraírnák, akkor egy rakás más kódot is át kellene dolgozni, és az marhára nem fér bele úgy, hogy jövő ilyenkorra az EA új Battlefront/field játékot vár.
Az lehet itt a stratégia, hogy a next-gen konzolokig kibekkelik ezzel.Nem akarom őket bántani, de tök jó példa a Rebellion. Írtak a Mantle-re egy memóriamenedzsmentet, azt pedig nulláról újraírták a DX12-höz. Igaz azóta nem azt használják, hanem egy még újabbat, de marhára nincs ilyen problémája a Sniper Elite 4-nek és a Strange Brigade-nek, pedig az Asura ugyanúgy Mantle-ön kezdett. Tehát nem az API-kkal van a baj. Rendbe lehet ezt rakni, csak nem úgy, hogy évi több játék jön közben a Frostbite-ra.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
#20674
Abu85
HÁZIGAZDA
huskydog17
#20672
Abu85
HÁZIGAZDA
válasz
huskydog17
#20672
üzenetére
A DX12-vel semmi baj, másnak problémamentesen megy. A Frostbite itt a bűnös, illetve leginkább az EA vezetősége, akik szerint nem fér bele egy év Battlefront vagy Battlefield nélkül, hogy rendbe kapják a motort. Itt majd valamikor 2021-ben lesz változás, amikor a next-gen konzolokra úgyis át kell azt írni. Addig marad a problémás memóriamenedzsment.
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
#20617
Abu85
HÁZIGAZDA
FollowTheORI
#20612
Abu85
HÁZIGAZDA
válasz
FollowTheORI
#20612
üzenetére
Az NVIDIA sem szemétkedik DX12 alatt. Náluk annyi van, hogy eléggé másképp működik a DX12 implementációjuk, emiatt bizonyos Microsoft által ajánlott dolgokat nem javasolnak. És amit ajánlanak helyette az se rossz igazán, mert az Intel és az AMD DX12 implementációja nem különösen kényes ezekre, de mondjuk az NV implementációja nagyon kényes például arra, hogy ha bizonyos buffer viewek nincsenek közvetlenül a root signature-ben. A Microsoft ugye azért ajánlja azt, hogy ne legyen buffer view a root signature-ben, mert a legtöbb SRV és UAV eleve nem helyezhető ide el, vagyis már az elején érdemes úgy tervezni, hogy ide csak leírótáblák és konstansok kerülnek. De maga a specifikáció nem zárja ki, hogy közvetlenül buffer view legyen benne, ha ez technikailag lehetséges, de bonyolultabb lesz a fejlesztők élete vele.
Az NV azért nem javasolja a Microsoft megoldását, mert bár értik, hogy a fejlesztők ezzel többet fognak szopcsizni, de ha nincsenek közvetlenül a buffer viewek root signature-ben, akkor romlik az implementációjuk pixel shader teljesítménye. Eközben, ha a fejlesztő az extra munkát be tudja vállalni, akkor ezt vissza tudja szerezni, miközben igazából semmit sem ront az AMD és az Intel implementációjának teljesítményén.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
De nem a Vulkan API segít ezen, hanem az AMD írt egy majdnem húszezer soros kódot, amit be lehet építeni, így nem kell megírni. Ugyanezt megtehetnék a DX12-höz is, vagy akár a Microsoft is leportolhatná.
Semmi reformra nincs szükség. Egyszerűen csak egy VMA kellene ide is. Csak ezt az AMD valószínűleg nem fogja megírni.
Nem a Frostbite Team tudása a probléma, hanem az EA vezetősége, akik minden évben várnak x címet. Nem lehet úgy dolgozni, hogy jövő karácsonyra mindig kell új Battlefield vagy Battlefront. Az id Software-féle "when it's done" modellhez képest ez jóval kötöttebb.Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
DX11-ben nem létezik az a kód, amit DX12-re kötelező megírni. Ez nem az API hibája, mert elég nehézkes lenne szabványosan úgy kezelni a VGA-kat, hogy közben nincs eszközlokális memória. A Vulkan is ilyen. A Mantle az egy speciális API volt, marhára rászabva arra, amit az AMD meg tudott engedni magának. Nekik teljesen realitás az egész VRAM-ot host visible flaggel kezelni, meg kb. az Intelnek is az. De ez egy nagy piac, ahol nem csak AMD és Intel van. Emiatt ilyen a DX12 és a Vulkan. De ebből nagy gond azért nincs, nem egy fejlesztő megcsinálja jóra a DX12 módot. A Frostbite-nak az sajnos nem volt túl szerencsés, hogy nagyon építettek a Mantle-re, így az egyes kritikus képességek kihullásával jöttek a problémák. És nem olyan egyszerű ám nulláról újraírni egy memóriamenedzsmentet, ez a legkritikusabb része az explicit API-knak. Viszont más alapvetően megoldja, tehát ez innentől az EA sara.
A Vulkan azért a memóriamenedzsment szempontjából jóval egyszerűbb. Ha nem akar működni a dolog, akkor alávágod az AMD VMA-t. Már majd húszezer sornyi kódról van szó, amit tényleg elég jól konfigurálni lehet az igényekre. Nem lesz szupergyors, mert általános megoldás, de arányaiban minden szituációban jó sebességgel működik. A DX12 esetében a Microsoft egy sokkal butább verzióját kínálja ennek, ami igazából tényleg csak egy kiindulási pontnak jó, nem lehet csak úgy beépíteni és várni tőle az automatikus működést. Szóval jelenleg egészen mások a lehetőségek a két API-n.
Azért a Doom pont egy rosszabb példa, mert annak elég sok problémája volt GeForce-on a Vulkan miatt, több memóriát is kért, mint Radeonon. A Wolfenstein 2 ezeket korrigálta. A Doom inkább egy nulladik generációs projekt volt számukra. Nem különösebben számított, hogy hibátlanul működik-e, arra kellett, hogy a Wolfenstein 2-re tapasztalatot gyűjtsenek. Szépen el is mondja Axel, hogy milyen volt a portolás. [link]
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
válasz
 -FreaK-
#20596
üzenetére
-FreaK-
#20596
üzenetére
DX12-vel van jól behatárolható gondja. DX11 alatt sok függ attól, hogy mit változtatnak a leképezőben, és arra mit lép a korábbi leképezőhöz szabott meghajtóimplementáció, amit aztán 1-2 hónap, mire átírnak a gyártók.
A Battlefront 2 óta ezért csinálja azt a Frostbite, hogy a gyártóknak megadja a lehetőséget, hogy a patch-ekbe már gyárilag optimalizált, külön shader kódot szállítsanak, amelyeknek akár nem is kell szabványosnak lenni. Csak ezzel nem mindenki él, mert ha esetleg kihúzza a supportot az EA a játék mögül, akkor úgyis kell majd hozzá a meghajtóba a speciális implementáció. Tehát amit ezzel gyárilag nem szabványos kóddal nyernek az gyakorlatilag az idő, amivel az esetlegesen problémás patch-ek után hibamentes lesz újra a játék.[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
válasz
Jack@l
#20593
üzenetére
[link] - időről-időre felüti a fejét. Nagyon random, azóta se tudják, hogy pontosan mi okozza (nyilván sejteni nem elég a javításhoz), de folyamatosan örökli mindegyik Frostbite játék a BF4 óta.
DX11 alatt nem is az alkalmazás felel a memóriamenedzsmentért. Nem a kapacitás vagy a hardver a probléma, hanem az, hogy egy sok-sok éve írt Mantle kód van DX12-re portolva. És ha átváltasz DX12-re, akkor bizony ettől tapasztalhatsz akadásokat, lagokat, elvégre a Mantle eleve nem támogatott sima eszközlokális memóriát, mindegyik látható volt a host számára. Ez baj, mert ilyet a DX12 alatt a VGA-k nem igazán támogatnak. Átírni meg ezt azért nagyon melós úgy, hogy évente kér több Frostbite játékot az EA. A szoftveres memóriamenedzsmentje a játéknak sajnos nem igazán jó, és ezt vagy megkerülöd a DX11-gyel, vagy a HBCC-vel. A 14 GB HBCC azért kellhet, mert ott érzi magát optimálisan a BF1. Nem nyers kapacitás kell neki, hanem az, hogy a teljes host visible flages memória biztosan HBCC szegmensen belül legyen a rendszermemóriában. A minimum ~11,5 GB mellett ~1 GB kicsúszhat ebből és nem HBCC által menedzselt területre kerül, ami azt jelenti, hogy ennek az allokációit folyamatosan be kell másolni a HBCC szegmensen belülre.
A Frostbite alatt alapvetően nem a hardverek jelentik az igazi korlátot. A motornak vannak nehezen javítható köhögőrohamai. Ezt megkerülni tudja némelyik hardver, de megoldani nem. A Frostbite Team tudná megcsinálni, ha az EA mondjuk adna nekik másfél évet, hogy akkor írják át, és jövőre nincs új Battlefield vagy Battlefront, de gondolom a részvényesek sikítva ordítják ilyenkor, hogy [link]. Szóval végeredményben csak cipelik a rendszer problémáit.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
Mindenen baj van vele. Itt leírtam mi a baj: [link] , [link]
A Frostbite Team se nagyon tud vele mit csinálni DX12 alatt. IGP-n jó, vagy aktivált HBCC mellett Kaby Lake-G-vel, illetve Vega 10-zel megkerülhető a hiba. De nagyon fontos, hogy engedélyezni kell a HBCC-t a driverben legalább úgy 14 GB-ra, különben ugyanúgy fog viselkedni a rendszer, ahogy a többi hardveren. Meg ugye itt is csak a rossz memóriamenedzsmentet kerülöd meg, mást már nem. Alternatíva a DX11, aminek meg az erőforrásledobálós problémája van.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
A Frostbite-hoz DX11-ben szerintem speciális implementációt használ az AMD és az NV is. Az eléggé titok, hogy itt mit varázsolnak, emiatt nehéz is megmagyarázni, hogy mi miért alakul úgy a konfigon, ahogy. Leginkább magic.
DX12-ben a CPU oldali eltéréseket szinte kizárólag az okozza, hogy az AMD-nél máshogy működik a bekötés, mint az NV-nél. A GeForce implementációja viszonylag erősen terheli a processzort, de ez annyira nem számít, hiszen lassan a nyolc mag is megfizethető, az API explicit, tehát a skálázás nem nagy kunszt.
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
válasz
 #21795072
#20479
üzenetére
#21795072
#20479
üzenetére
A virtuális memória az más. Ott igazából az OS gondoskodik arról, hogy a virtuális memóriában lévő, de szükséges tartalom odakerüljön a memóriába. Tehát onnan sose olvas direkten egy program.
Amit Yany, az SSG, az csak úgy működik, ha a program használja az SSG API-t. Ilyenkor a GPU melletti VRAM kb. olyanná válik, mint a CPU-k L3 gyorsítótára, és az adattároló lesz az igazi VRAM. De ahogy mondtam, ehhez egyrészt kell a hardverben egy bájtszintű elérést támogató vezérlő, illetve az API, amivel egyáltalán hozzáférhető az adattároló. Aztán persze a VGA-n lévő SSD-t láthatja a Windows is, oda lehet másolni akármit, de amíg program oldali támogatás nincs rá, addig ez csak szimpla adattároló, ami fizikailag a VGA-n van.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
válasz
#21795072
#20474
üzenetére
Ha a memóriavezérlők a bájtszintű elérést is támogatnák, és erre lenne egy egységes API, hogy a fejlesztők direkten megcímezhessék a NAND-ot, akkor igen. De egyelőre se egységes API nincs, se bájtszintű elérés a legtöbb hardveren. Ezzel szemben a virtuális textúrázáshoz megvan minden.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
#20473
Abu85
HÁZIGAZDA
szmörlock007
#20471
Abu85
HÁZIGAZDA
válasz
 szmörlock007
#20471
üzenetére
szmörlock007
#20471
üzenetére
A Carmack-féle megatextúra azért több volt ennél, de lényegében az.
(#20472) Depression: Nem igazán oldható meg ez erőből. A virtuális textúrázás azért előnyös, mert ott tényleg csak azokat az adatokat tárolod, amik hasznosak, és hatásfokban messze ez a legjobb megoldás. Új hardvert sem kell venned, csak a motorokat kell erre felkészíteni.
A memória sem azért akadályozó, mert kevés, hanem azért, mert rosszul használjuk. Emiatt kell hozni az okos módszereket, mert a memória ára drága, tehát az annyira nem nőhet, de mindenki tisztában van vele, hogy a memória nagy részében haszontalan adat van betöltve, amihez a programfuttatás jelentős szakaszában hozzá sem nyúl az alkalmazás. Azt kell elérni, hogy hatékonyabban használjuk az erőforrást. Ez nagyrészt szoftveres kérdés. De jelenleg ott tartunk, hogy több explicit API-t használó program rosszabbul használja a VRAM-ot, mint a régi DX11 vagy OpenGL, dacára annak, hogy megvan a lehetőség az alkalmazásra szabott menedzsmentre. És ezen a Microsoft sem igazán segít, mert kb. írtak egy nagyon alapszintű RSL-t a DX12-höz, de például ennek a Vulkan API-ra írt alternatívája sokkal bővebben kezeli a problémát. Ezeket kellene kezelni, mert annyi memória és teljesítmény veszik itt oda, hogy az már káros.[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
Hát kb.
Meg ugye az is probléma, hogy elértünk egy olyan korlátot, ami miatt már nem nő automatikusan a textúra- és geometriai részletesség, csak azért mert a GPU erősebb. Előbbihez a memória kevés, utóbbit pedig a quadraszter modell akadályozza. Tehát mostantól ezek javításához is el kell kezdeni okoskodni. Azt pedig elég nehezen tudom elképzelni, hogy hirtelen valaki előáll valami áttörő ötlettel, ami helyből megoldja mindkét problémát. Maximum elkezdik kezelgetni, és majd egyszer találunk valami megoldást.
A textúrákra jelenleg a virtulis textúrázás tűnik a legjobb módszernek, azzal radikális mértékben csökkenthető a memóriaigény, így nem jelentene problémát a részletesség növelése. De ez tisztán szoftveres szempont. A geometriánál a quadraszter egy hatalmas limit. Tényleg nem tudom, hogy mit lehetne ahhoz kitalálni, hogy továbbmenjünk. A mostani futószalaggal valószínűleg semmit sem lehet tenni. Szóval itt az ingyen ebédnek még szoftveres oldalon is vége.[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
#20468
Abu85
HÁZIGAZDA
Petykemano
#20467
Abu85
HÁZIGAZDA
válasz
 Petykemano
#20467
üzenetére
Petykemano
#20467
üzenetére
Mi köze van a gyártóknak ahhoz, hogy a textúrarészletesség és a geometriai részletesség növekedjen? Ezek automatikus folyamatok, még akkor is, ha manapság leállt ezen a téren a fejlődés. A következő lépcső a kijelzőknél a 8K, és ahhoz muszáj növelni a textúrák méretét. A legtöbb játék már a 4K-s felbontáshoz sem kínál megfelelő méretű textúrákat, tehát manapság is eléggé szükség lenne ezek növelésére. Ezt maximum azok nem látják, akik nem 4K-ban játszanak, mert WQHD-ben, vagy Full HD-ben ez nem annyira feltűnő. De 4K-ban borzalmas. Azt pedig eddig is láthattad, hogy bármit is állítottál be a textúrarészletességnél, illetve a geometriai részletességnél egyetlen gyártó sem írta ki, hogy nem csinálja meg. Maximum figyelmeztetett a játék, hogy lehet kevés a memória, de egy OK-kal nyugtáztad és beállította.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
válasz
Raymond
#20462
üzenetére
Dehogy dolgoznak ott amatőrök, csak a HBCC és az NVLINK két külön problémára kifejlesztett technológia. A HBCC-re is megvan a Voltában és a Turingban a megfelelő alternatíva, de kizárólag akkor működnek, ha a host CPU IBM Power9. Az NVLINK akkor is működik, ha nem, de alapvetően az igazi erejét a lapalapú menedzsment adná. Az AMD alternatívája az NVLINK-re a GMI. És itt is ugyanaz a helyzet áll elő, hogy a GMI és a HBCC például IBM Power9 proci mellett nem száz százalékos technika, mert az AMD megoldása akkor működik teljes értékűen, ha a host CPU x86/AMD64-es.
A HBCC igazából annyival több az NVIDIA saját vezérlőjénél, hogy nem csak blokk-, hanem bájtszintű elérést is támogat, ergo be tud olvasni adatot közvetlenül a NAND-ról is, vagy akár a hálózati adattárolóról, de ennek nincs sok köze ahhoz, hogy a multiprocesszor címfordítói milyen host CPU-hoz igazodnak. Az egészhez van egy SSG API, amivel az alkalmazásban megoldható az adattároló közvetlen elérése. Ilyet az NVIDIA is tud csinálni, csak a bájtszintű adatelérést kell megoldani a hardver oldalán, és kell az API hozzá. Nem egy nagy tudomány, ami emögött van, főleg úgy, hogy már Volta és a Turing is támogat hardveres, lapalapú menedzsmentet. Innen a bájtszintű elérés csak egy lépcsőfokra van.
Nem mellesleg a játékosoknak a bájtszintű elérés ne hasznos most, mert ahhoz külön API kell, így a HBCC csak a rendszermemóriáig működik. Függetlenül a memória kijelölésének módjától.Ezeknek az NVLINK-eknek és GMI-knek akkor lesz igazán sok haszna, ha a CPU-hoz ezeken keresztül lesz bekötve a GPU. Addig igazából a játékosoknak nem sokat érnek, mert csak annyit tudnak elérni velük, hogy két GPU egymás memóriáját gyorsabban tudja elérni. De ettől még a programok oldalán ugyanúgy biztosítani kell a több GPU-val való kompatibilitást, tehát újra kellene írni egy rakás kódot azért, hogy ugyanúgy ne skálázódjon normálisan az SLI, ahogy ma, mert alig van program, ami támogatja a driverből kényszerített AFR-t. Ha lenne ennek szoftveroldali háttére, akkor megcsinálnák, de nincs igazán mire. Explicit API mellett pedig nincs semmilyen proprietary link definiálva. Ha van a hardveren valamilyen csati, ha nincs, akkor is a PCI Express sávokon közlekednek majd az adatok a DMA motorokon át. Emiatt van az, hogy DX12-vel működik két GeForce úgy, hogy nem is kell hozzá SLI-t támogató alaplap. És mivel a Microsoft ezt előnyként jegyzi, így nem igazán érdeklődnek aziránt, hogy a gyártók behozzák az API-ba a proprietary megoldásaikat. Szóval emiatt igazából hiába lesz az új GPU-kban NVLINK vagy GMI, a játékosok ezeknek a hasznát egy VGA-n nem fogják érezni. Professzionális szinten, illetve a szerverekben már van értelme.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
válasz
atok666
#20427
üzenetére
Mihez van köze?
(#20418) LionW: Valószínűbb inkább a tesszellálás a vizen, plusz a becsapódásoknál egy textúraeffekt. Ez elég olcsó is, és igen jól szokott működni.
Ha nincs több szikla, ami rigid body modellel lecsúszhat, akkor ez van. Ettől még PC-n nem látni ilyet. De a rigid body motor alapvetően jól működhet, mert amikor átmegy a piacos részen, akkor sok bódét felborít és széttör.
Valamiféle vertex shader dolog lesz a növény. Majdnem az egész játék vertex shader trükközés: [link][ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
Felvettek vagy száz animációt csak erre, és random játsszák be, minthogy inkább a 0,1 ms-nyi számítási kapacitást sem igénylő rigid body fizikára építenének. Okosak ezek a Sony-nál.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
Hátha kettőt lefake-eznénk.
(#20407) Crytek: Mert az a pénz sem igazán téma nekik, amit a jogokért kapnának. Értsd ezt úgy, hogy amennyiért megvennék tőlük, annyiért nem adnák el, de amennyiért eladnák, annyiért meg nem venné meg senki. Szóval végeredményben ülnek rajta.

[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
#20401
Abu85
HÁZIGAZDA
huskydog17
#20396
Abu85
HÁZIGAZDA
válasz
huskydog17
#20396
üzenetére
A fizika azért tűnt el, mert a hagyományos API-k limitálnak. De ahogy ezeket eldobják visszatér, hiszen hozzáférhetővé válik egy rakás processzoridő.
Akik nem kötöttek szerződést, így szabadon véleményt mondhatnak. Az ENBSeries fejlesztője ilyen. Az én szerény véleményem szerint mindkettőnknél sokkal okosabb, bár ettől persze még tarthatod hülyének.
Vannak egyébként az RT-re nagyon jó ötletek: [link]
A reddit fórumokon. A legtöbben a textúrarészletességgel és a geometriai részletességgel elégedetlenek. Előbbivel kapcsolatban én is az vagyok.
Az ENBSeries fejlesztője nem egy szimpla modder. Ő injektál programokat a játékokba. Kb. annyira tisztában kell lennie a dolgok működésével, mint egy motorprogramozó, másképp nem lenne képes fejleszteni az ENB-t. Mellesleg tényleg nem nehéz kiszámolni, hogy nyersen mennyi sávszél kell, hiszen BHV-ról tudni, hogy 80 bájt az igénye, plusz a háromszögek csúcspontjai. Volt már aki jobban belement Twitteren. [link]
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
Az én véleményem az RT-ről az, hogy jó, erre érdemes menni, csak amíg nincs 2 TB/s-os sávszél a VGA-kon, addig igen vérszegény lehet csak a geometria. Le is írtam a cikkben, hogy miért. Egy mai PC-s játékhoz minimum BVH8 kell. Alatta ez nem realitás, mert akkor mobil szintűre csökken vissza a részletesség. A BVH8 az olyan 80 bájtos terhelés per sugár per mélység. És akkor még háromszöget is vannak, azok csúcspontjai 16 bájtot igényelnek, tehát ha akarjuk is a 10 Gigarays/s-ot, nem csak papírra vetni, hanem a gyakorlatban is használni, akkor marha jó lenne megcélozni úgy 1,5 TB/s-os sávszélt, és ez a minimum. Az optimális érték olyan 3 TB/s körüli. Nyilván az ENBseries fejlesztője programozó, tudja miképpen működik ez, és természetesen ő is utánaszámolt, hogy ~600 GB/s az igazából nem sok ám ide. Durván meg kell fogni a geometriai részletességet, hogy ne jelentsen erős limitet.
Azzal nem értek egyet, hogy ebből még évekig nem lesz semmi. Látva, hogy mennyire fejlődik a HBM, szerintem 2020-ban már lehet 2 TB/s-os VGA-nk, persze problémát jelenthet, ha időközben bekopogtat a mikropoligon érája. Akkor még több sávszél kell majd, és úgy 10 TB/s-nál vehetjük elő újra a kérdést. Ebben az esetben igaza lehet neki, hogy még évekig nem lesz belőle semmi, de én nem vagyok annyira optimista, hogy hirtelen valamelyik gyártó előáll egy akkora hardveres innovációval, amely megoldja a geometriai részletesség növelése előtti legnagyobb limiteket. Az maga lenne a csoda.Gondolom a smájlikat ignoráltad.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
válasz
 lezso6
#20384
üzenetére
lezso6
#20384
üzenetére
Nekem is nagy a hasam.

(#20385) b. : Ez attól függ, hogy a gémerek mit várnak. Amiket én olvastam az két dolog. Növelni a textúrarészletességet, mert nem tartják elégnek, és növelni a geometriai részletességet. Na most az előbbihez memória kell, jó sok, aminek nem kedveznek a memóriaárak, tehát valami trükköt erre ki kell majd találni. Az utóbbihoz mikropoligonok, aminek nem kedvez a quadraszter, tehát valami trükköt erre ki kell majd találni. De ha valaki aratni akar, akkor ez a két tényező az, amit mindenki nagyon szeretne, és aki előbb hoz valami áttörést itt, az fog sokat nyerni. Az izgalmas ebben az, hogy marha nehéz mindkét probléma.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
A legtöbb FPS-ben, ha lenézünk, akkor nincs lábunk, de most legalább tükörképünk lesz.
Egyébként nem, mert maga a modell hiányzik, ezért sincs lábunk, két fél kezünk van és egy fegyverünk, azt fogod látni tükörképnek is.![;]](//cdn.rios.hu/dl/s/v1.gif) Hacsak nem tervezik végre bele a modellt a megjelenítésbe, és akkor végre lesz lábunk is, juhhu.
Hacsak nem tervezik végre bele a modellt a megjelenítésbe, és akkor végre lesz lábunk is, juhhu. A hype az oka az ellenszenvnek. A felhasználóknak be lett adagolva, hogy orbitális előrelépés lesz teljesítményben. WCCFtech, TweakTown, stb. Most pedig csalódás lett, mert semmit nem kaptak. Ha mondjuk a média ezt nem fújja fel, akkor tetszett volna ez is, csak túl nagyra fújták a lufit a pletykacikkek. Ezért is szeretné az NV, ha vége lenne ennek, és lenne egy általános NDA, hogy csak olyan anyag jelenhet meg, amit jóváhagynak.
Az RT-nek pedig igazából az sem segít, hogy programozók eléggé leszólják. Lásd az ENBSeries fejlesztője, akire azért elég sok gamer hallgat. [link][ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
De ha egy SSR megvalósítást hasonlítanák ehhez, akkor igazából alig látnál különbséget, és az SSR-hez képest az RT megoldás számításigénye legalább 20x nagyobb. Ezért nem aktiválják az SSR-t az összehasonlításhoz.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
válasz
 Puma K
#20300
üzenetére
Puma K
#20300
üzenetére
Nem a DX12-nek köszönhető. Az API-nak semmi baja, mert másnál nem akad ettől az API-tól egy játék. A Frostbite-tal van baj: [link] , [link]
Ezért persze szarjanak sünt, de nem olyan könnyű ezt rendbe rakni.[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
#20257
Abu85
HÁZIGAZDA
SECTORnooB
#20256
Abu85
HÁZIGAZDA
válasz
 SECTORnooB
#20256
üzenetére
SECTORnooB
#20256
üzenetére
Majd 2 TB/s sávszélnél jó lesz. Elérjük ezt is, nem is olyan sokára. Ha kitömik L1 gyorsítótárral a next-gen GPU-kat, akkor igazából két generáción belül játszható lesz az egész 4K-ban is. Csak arra számolj, hogy a HBM3 4096 biten 2,5 TB/s körüli sávszélt kínál majd. És ez nincs messze, 2020 közepe.
Semmi gond nem volt a hangvételedből.

[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
Hát igen. Én is úgy terveztem, hogy majd az ellenfél szeméből visszatükrözött jelenet alapját hozok döntéseket, de így hogy ez 2060-on nem realitás, maradok a sima lövöldözésnél.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
#20248
Abu85
HÁZIGAZDA
SECTORnooB
#20241
Abu85
HÁZIGAZDA
válasz
SECTORnooB
#20241
üzenetére
GTX 2060 és november.
(#20245) SECTORnooB: Mindegyik kártya tudni fogja, mert az egész egy szabvány. De ha Full HD-ben még 60 fps-t is akarsz, akkor 2080 Ti alá ne add.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
válasz
 cyberkind
#20147
üzenetére
cyberkind
#20147
üzenetére
Az Uncharted 4-hez hozzátenném, hogy semmi olyat nem használ grafikailag, ami PC-n nem megvalósítható. Ami ebben a játékban erős az az "élőnek" tűnő környezet, és ezt úgy érik el, hogy pivotelemekre épülő általános vertex feladatokat futtatnak. Ez azért tűnik ilyen brutálisan jónak, mert a PC-n, amikor még a vertex-pixel árnyalás bejött, akkor a pixel felé ment el a számítási kapacitás, és a kutatásuk is erre vették az irányt, így végül hiába lett unified árnyalásunk a hardverekben jó régen, a kutatások miatt még ma is a pixel shading a döntő tényező, vagyis a unified hardverekben az ALU-k zöme pixel shadert futtat. Ezzel szemben az Uncharted 4 teljesen más arányokat használ. Több compute és vertex shader fut a hardveren, mint pixel shader, ami PC-s környezetben például nem, hogy nem igaz, hanem jellemzően legalább kétszer több a pixel shader, mint a compute és vertex shader. Ez a különbség okozza azt az immerziós hatást, ami miatt az Uncharted 4 olyan marhára jónak tűnik. Ez a videó elég jól bemutatja, hogy mi mindent megoldottak vertex shaderrel, míg PC-n ugyanezekre esetlegesen sokkal komplexebb, sokkal lassabb megoldásokat választanak a fejlesztők. [link]
A vertex shader egyébként azért mostohagyerek, mert a pixel shadernél jellemzően nagyobb a regiszterterhelése, de alapvetően a legtöbb mai PC-s GPU nem tekinthető annyira regiszterszegénynek, hogy ebből olyan hatalmas probléma legyen. Tíz éve az lett volna, de ma nem, és ez látható a PS4-en is, aminek a GPU-ja igazából pont ugyanannyi regisztert tartalmaz multiprocesszoronként, mint az összes GCN-es Radeon. Tehát nincs igazán akadálya ezeknek PC-n.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
DX11-ben nincs shader modell 6.0, így a DXR-t se tudja megjeleníteni. Talán a bemutató erejéig ráműtötték binárisan, de ez szállítás szintjén nem realitás, mert itt azért nem csak egy fix gépen kell működnie, hanem mindenen, vagyis a binárisan szállított kódot nem is fog engedni a Microsoft. Mindenképpen minimum DXIL-t kell szállítani.
Nem írtam, hogy a Radeont nem érinti ez a probléma. Az a 256 MB leválasztott típus csak segít, de ha nem férsz bele, akkor a maradék erőforrást mindenképpen a rendszermemórián kell tárolni, amivel ugyanúgy jön a drága transzferművelet, ahogy a GeForce-on. Az AMD-nek erre tök egyértelmű az ajánlása. Ha host visible erőforrásokat használ a motor a GPU számára olvasható erőforrásokhoz, akkor tutira férjen bele 256 MB-ba. Ha nem fér bele, akkor jön a transzfer. Na most a Frostbite-nál az a baj, hogy amíg a Mantle-t használták, addig ugye a teljes eszközmemória host visible volt, tehát amikor a menedzsmentet írták, akkor nem kellett azon gondolkodni, hogy mely erőforrásokra érdemes a működést olyanra tervezni, amely nem látható a hostnak, mert igazából mindegy volt, a teljes RAM-ot és a teljes VRAM-ot is látta a CPU a Mantle alatt. Aztán ezt utólag átírni... jó eséllyel a 256 MB-ba sem férsz amúgy bele, ha helyből erre épít a menedzsment, ami egyébként DX12 és Vulkan API-ban kifejezetten nem ajánlott. Nem baj, ha van pár erőforrás, ami host visible, valószínű lesz olyan, amit a CPU ír és a GPU olvas, és egy 100 MB-ot azért elég jól meg tud oldani még a transzferes megoldás is, viszont mondjuk 300-400 MB-ot már nem, és itt már az aszinkron DMA sem biztos, hogy sokat segít. Persze erre is van megoldás, hiszen a gondot az allokációk másolása okozza, így a HBCC-vel tudsz lépni lapalapú modellre, ami természetesen automatikusan kezeli az összes ilyen transzferproblémát, amit a relatíve nagy allokációk okoznak. De ezt igazából a hardverek 99%-a nem tudja, tehát cseszheti a Frostbite. Jó biztos örülnek, hogy a Vega 10 megoldotta hardveresen a motor elbaltázott menedzsmentjét. Na és a többi? Szóval kb. itt áll a történet, és nagyon nehezen tudnak vele mit kezdeni. Lehet ezt javítgatni évről-évre, de megoldani csak akkor, ha újraírják az egészet. De az gondolom szóba se jöhet, mert az EA vízfejű vezetősége rögtön tenyerel a piros gombra, ha felmerül, hogy emiatt a következő évben jó eséllyel nem lesz Battlefield vagy Battlefront.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
válasz
 Callisto
#20089
üzenetére
Callisto
#20089
üzenetére
Nem a DX12 a minimum a DXR-nek, hanem a Redstone 5. A DX12-höz annyi köze van a DXR-nek, hogy a DirectCompute API kap egy interoperability réteget, amivel képes lesz támogatni a DXR futtatási környezetet. Ez már benne van a Redstone 4-ben is, vagyis az áprilisi frissítésben, de ott csak akkor működik, ha aktív a devmode. Ha ez nem aktív, akkor az OS-nek fingja sem lesz a DXR shaderek függvényeiről. Meg amúgy sem, mert a Redstone 4-be épített futtatási környezet eleve nem kompatibilis a véglegessel, amire majd szállítják a programokat. Szóval alapvetően a végleges DXR címek futtatásához a DXR 1.0-s futtatási környezet kell, amit a Redstone 5 kap meg. A DX12 csak azért minimum, mert a DXR shadereket csak DXIL formátumban lehet szállítani, és DXIL-t csak a DX12 API támogat.
Persze ha a Microsoft mondjuk valamilyen csoda folytán úgy döntene, hogy visszaportolja a shader modell 6.x-et a DX11-be, és a DXR 1.0-t kiadja Windows 7-re, akkor természetesen azon is futhatna, csak erre mint tudjuk, hogy mekkora esély van. Ha tényleg érdekelné a Windows 7 az MS-t, akkor már futtatható lenne rajta a shader modell 6.x.A Vulkan esetében a Khronos azt ígérte, hogy nagyjából egy év múlva lesz draft. Addig jöhetnek kiterjesztések, de az szokás szerint alig fog érdekelni valakit, mert maga a SPIR-V nincs felkészítve ezekre a függvényekre. Az Anvilon keresztüli megoldás pedig eleve nem a SPIR-V-t használja, hanem az egy framework a Vulkan elé, amihez egyedi shadereket lehet írni C++-ban. Ez egyáltalán nem egy szabványos megoldás, mert a Vulkan kiköti, hogy csak SPIR-V-ben lehet shadert szállítani, de ettől persze még a Khronos is elismeri, hogy működik. Viszont szabványosítani ezt nem tudják, mert a legfőbb specifikáció, hogy a shader nyelv a SPIR-V, és semmi más. Persze aki szállítani akar Anvil frameworkön raytracinges játékot az megteheti, a Khronosnak nincs ezzel semmi baja, csak ők olyan megoldást fognak csinálni, ami nem egy API előtti frameworkben oldja meg ezt a problémát, hanem magában az API-ban. Viszont egy ilyen szabványt megalkotni időbe telik. Legalább másfél évbe. De a Khronos tempóját figyelembe véve lesz az két év is.
Alternatív megoldás egyébként a Vulkan-DX12 interoperability. Ezzel a módszerrel maga az alkalmazás futhat a Vulkan API-n, miközben a DXR shadereket a DirectCompute API-n futtatja, az eredményeket pedig interoperabilitás mellett biztosítják a Vulkanhoz. Ez is működik, sőt, még szabványos is.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
Nem oldották meg. Kezelhető, nem túl jól persze, de nem megoldható, csak akkor, ha a nulláról újraírják az egészet, ami viszont elég sok idő, és úgy nehezen tehető meg, hogy évente egy csomó játékot kér az asztalra az EA. Az Intel úgy magyarázta nekem, amikor rákérdeztem, hogy miért nem érintettek, hogy ez egy Mantle örökség. Amikor a Frostbite-ot írták az explicit API-ra, akkor mindent a Mantle-höz szabtak, így keletkezett egy egészen vaskos kód a memóriamenedzsmentre. Ezt elég jól átmentették a DX12-höz, hiszen annyiban azért ez az API nem különbözik, de egy dologban azért mégis. Amíg például a Mantle esetében az AMD nem specifikált olyan memóriatípust, ami nem volt legalább látható a hostnak, addig a DirectX 12-ben van ilyen, és ez a fő memóriatípusa a VGA-knak. Na most a Frostbite a Mantle öröksége miatt nagyon épít a host felé látható erőforrásokra, amelyek olyanok, hogy a CPU dinamikusan frissíti őket minden jelenet során, és a GPU majd ezeket fogja olvasni (írni nem). Na most ez egy IGP-nél tök oké, hiszen ott eleve a rendszermemória része a VRAM, és gyakorlatilag bármilyen struktúra mellett az egész host által látható. Tehát a CPU úgy képes a GPU által olvasható erőforrásokat írni, hogy nem szükséges hozzá explicit memóriamásolás. Csak ezért van egyébként az AMD DX12-es implementációjában egy 256 MB-os terület a VRAM-ban elkülönítve, hogy azt a CPU a rendszermemóriát megkerülve, kvázi közvetlenül tudja írni, mert host visible flag van rajta, és a GPU olvashatja az odakerült eredményeket a VRAM sebességével. Na most a Frostbite szemével vizsgálva az a legfőbb gond a DirectX 12-ben, hogy VRAM-ra nem kötelező a host visible flag, és az NVIDIA nem is alkalmazza, így nekik a teljes VRAM olyan, amit a host CPU nem tud se látni, se cache-elni (utóbbi annyira nem lényeges). Erre egy L0-s memory pool van generálva az NV meghajtójába, amiből van egy host visible típus, de ez nem a VRAM-ban van, hanem a rendszermemóriában. Tehát amíg a Frostbite a host visible flaggel rendelkező memóriatípusba helyezett erőforrásokat az Intel és az AMD hardverein úgy frissíti, hogy azokat a GPU közvetlenül tudja olvasni, addig a GeForce-on ez nem lehetséges, mert a VRAM nem elérhető a hostnak, így ezeket az erőforrásokat a GPU nem a VRAM-ból olvassa be, hanem a rendszermemóriából a PCI Express interfészen keresztül. Az újabb Frostbite motorok (a BF1 óta) annyiban kedvezőbbek, hogy van erre egy explicit másolás, vagyis amint a CPU frissítette az érintett erőforrásokat, azokat rögtön bemásolják a GPU memóriájába (erre jó az aszinkron DMA), de ez itt akkor is egy extra másolási művelet, ami ha nem lesz kész időben, akkor sajnos akadásokat idézhet elő.
Az egészet úgy lehetne végérvényesen megoldani, ha az EA mondjuk adna időt a Frostbite Teamnek a memóriamenedzsment újraírására, így az le tudná vetni magáról a Mantle örökségeit. Ennek az a baja, hogy kockázatos, mivel az EA portfóliója megköveteli, hogy a motor folyamatosan fejlődjön, így nagyon mélyen nem nyúlkálnak bele, hogy az ne veszélyeztesse a tervezett játékok kiadását. Valószínűleg úgy vannak ezzel, hogy a next-gen konzolokig kihúzzák, azokhoz pedig úgyis új alapokat írnak, és azzal a fenti probléma is megszűnik.
Sajnos nagyon nem egyszerű ez, és nem igazán a DX12 a hibás érte, mert annak vannak specifikációi, egy csomó játék követi azokat, lásd Rise of the Tomb Raider vagy Sniper Elite 4, és működik igazából a DX12 mód. Persze a VRAM kell, de ettől még fut, zömében akadások nélkül (néha pedig egy-egy akadás eleve előfordul, a PC nem egy fix hardverplatform nem tudod abszolút rátervezni a programot). A Frostbite az a másik véglet valóban nem, sok pénzt beleöltek a Mantle-be, és természetesen úgy akarták ezt áthozni DX12-re, hogy a Mantle-höz írt kódok jelentős részét megőrzik. Gazdaságilag így logikus. De például a Rebellion úgy portolta a DX12-re az eredetileg Mantle-re írt Asurát, hogy a memória-menedzsmentet újraírták. És láss csodát minden hardveren akadásoktól mentesen működik DX12-vel valamelyik grafikai beállítással, amit nyilván a hardver ereje szab meg.
Szóval azért elég sok fejlesztőnek működik a DX12, míg pár fejlesztőnek nem. Nem igazán az API a szar, még csak nem is a gyártói implementációk, mert látod, sokan megoldják. [ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
Na most az egy szivárgós dokumentum, de annyi a lényeg, hogy kiválasztották a leg-leg occupancy limitesebb compute shadert, és arra mérték le, hogy mennyit javult a multiprocesszor. Ez ugye nyilván azért nem annyira izgi, mert a maradék 9x% shader pedig nem lesz annyira occupancy limites, hogy ne tudja a warp mennyisége elfedni a memória késleltetését.
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
válasz
BoWDaN
#19867
üzenetére
Ezért tervezték eredetileg 16-24 GB-ra, de a memóriaárak...

Az 1080 Ti jóval gyorsabb marad a 2070-nál, ha nincs mondjuk RTX. És nem a memória miatt. A használt ár újhoz hasonlítása pedig nem különösebben hasznos.
Az általánosan jellemző, hogy az előző generáció használtan jobban megéri, mint az új generáció, mert a használt ár jóval alacsonyabb.[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
Mert a HBAO+CHS is kész van az RT időigényének a tizedéből.
Nem biztos, hogy fallback layert kap a Vega. Egyelőre a Microsoft csak a Kepler, Maxwell, Pascal és Intel Gen8-9 sorozatot kezeli (Fermi és Gen7.5 kiesik a shader modell 6.0 hiányában). A GCN-t, a Voltát és a Turingot nem.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
válasz
Puma K
#19256
üzenetére
A PhysX megdöglött. Kivették belőle a pénzt már régebb óta. DXR mellett pedig eleve használhatatlan, mert a DXR is azokat a szabad ALU-kat foglalja le, amiket a PhysX. Így ez az egész fizika visszaköltözik a CPU-kra vagy az APU-kra, mert a GPU-n már nincs szabad ALU rá a sugárkövetés mellett.
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
-
Abu85
HÁZIGAZDA
válasz
 Dyingsoul
#18834
üzenetére
Dyingsoul
#18834
üzenetére
A TSMC a 7 nm-t két lépcsőben vezeti be. Van most az EUV nélküli, és jön az EUV-s. Az EUV nélküli tömeggyártás szintjén elérhető már az év végén, míg az EUV-s valamikor jövő nyáron, bár a vírusos buli miatt ez lehet, hogy csúszik egy picit, viszont ősszel akkor is működni fog. A legtöbben ezt az EUV-s 7 nm-t célozzák, mert az EUV nélküli esetében eléggé early adopter az árazás is, és ez pár cégnek megéri, mint az Apple-nek vagy az AMD-nek, de másnak nem igazán. Viszont az EUV-s 7 nm már több cégnek fogja megérni, és arra már érdemes ráugrani az NV-nek is.
(#18840) b. : Most sem igazán a kihozatal a probléma, hanem az, hogy EUV nélkül annyira költséges lehet ilyen csíkszélességen a gyártás, hogy nagyon magas a waferek ára. A kihozatal a tervezettnél is jobb, tehát abból a szempontból jelenleg nincs gond, de a waferárakat nagyon sokan nem tudják felvállalni. Az Apple tudja ezt kigazdálkodni, illetve az AMD, de utóbbi kizárólag az EPYC miatt, mert ott azért egy négylapkás cucc lesz vagy 4000-7000 dollár. Még ha a kisebbeken veszteség is lesz, akkor is a nagyobbak pozitívba lövik a mérleget. De más nem nagyon tud ilyen árakon megfelelő mennyiségben gondolkodni, illetve nincs olyan piaci háttér, hogy egy megharapott gyümölcslogót rakva a termékre, sorba álljon érte a nép.
Szóval az NV-nek a mostani 7 nm-es node-dal sem lenne baja, csak nem igazán lehet értelmesen kigazdálkodniuk az árát. Ha olcsóbb lenne már repülnének is rá. Az EUV-sre repülnek is szerintem.(#18844) X2N: Úgy kell elképzelni, hogy van egy csúszka a driverben, és ha van kellő memóriád, akkor beállíthatod 64 GB-ra. Annyit kell tudni, hogy a rendszermemória fele foglalható le erre a célra. Tehát 32 GB esetében 16 GB jön a RAM-ból és egy 8 GB-os Vegánál 8 GB a HBC-ből, így lesz összesen 24 GB a HBCC szegmens. Ez a program oldalán VRAM-nak látszódik, mintha fizikailag ennyi lenne a VGA-n. Ugyanez igaz 64 GB-ra, ha 8 GB-os a VGA, akkor RAM-ból 56 GB kell, tehát rendszermemóriában minimum 92 GB.
Ha csak HBCC szegmenset használsz, akkor addig nehetsz, amíg a HBCC szegmens kijelölt kapacitásába beleférsz. A ProRender egy kicsit bonyolultabb, mert annak az új verziója már támogatja az inkluzív módot, vagyis addig nem fagysz ki, amíg a rendszermemóriádban van szabad hely, illetve technikailag utána se, de akkor már az adattárolót fogja használni a rendszer a virtuális memória részeként. Az SSG-n annyiban más az egész, hogy a GPU melletti memória mindig cache, ez nem tud működni VRAM-ként, helyette a 2 TB memória a hagyományos értelemben vett VRAM. Ez se fagy ki, ha túlmész a 2 TB-on, de akkor ennek is az adattárolót kell használnia. A nyers határ 256 TB végfelhasználói termékeken, és 512 TB a professzionálisokon. Ha ezeket túlléped, akkor fagysz ki, de amíg van hozzá adattárolód a VGA-n, a gépben, vagy akár a hálózaton, addig oké vagy.[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
válasz
 zed juron
#18821
üzenetére
zed juron
#18821
üzenetére
A Titan V CEO Editionön van 32 GB, de azt nem árulják csak adják a kiválasztottaknak. A többi elérhető Titanon sincs 12 GB-nál több. Szóval consumer szinten az NVIDIA nem kínál semmit, amin ennél több van.
16 GB-hoz Quadro-ra kell menni, de lehetőleg az RTX 5000-re, vagy ha arra nincs pénz, akkor a Vega esetében kellő rendszermemóriával 64 GB-nyi VRAM is beállítható a driverből. Más alternatíva most nincs, nem is lesz.[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
válasz
NewHope88
#18815
üzenetére
A Microsoft szerint bizonyos effektek eléggé könnyen beépíthetők a D3D12 DXR kiegészítésével. Tehát árnyékokra, visszaverődésekre, élsimításra lehet használni viszonylag könnyen, az egyedüli hátrány, hogy ha a program nem szállít úgymond legacy shader IR-t, akkor a DXR a futtatás minimum Windows 10 Redstone 5-re kényszeríti, akkor is, ha nincs egy effekt sem bekapcsolva. A Metro Exodus is így használja. Integrálni már nehézkesebb, mivel erősen módosítani kell a motort, nem elég csak a shadereket hozzászabni a shader modell 6.2-höz, ami persze sokszor nem kis meló eleve, főleg akinek van már 300-400 ezer sornyi megírt shadere, azt ugye le kell konvertálni, hogy fordíthatók legyenek DXIL-be. Mindezek miatt pár évre azért szükség van, hogy a fenti effekteken túl is használják valamire. Emellett vannak problémák is, például a DXR, minőség szempontjából optimális vertex formátuma rendkívül memóriapazarló, illetve maga a rendszer nem támogat alapból LOD-ot, vagyis azt külön kell megoldani, viszont már készül rá egy gyári megoldás, de leghamarabb a DXR első nagyobb frissítésével lesz elérhető, ami egy-másfél évre van, ekkor azért elég sok, játékfejlesztők által jelzett hiányosság bekerül a rendszerbe, többek között a 32 bites snorm is a vertex adatokra.
Ezek alapján azt mondom, hogy az első másfél évben ebből árnyékokra, visszaverődésekre és élsimításra vonatkozó effektek lesznek. Utána azért elég idő telt el, hogy a motorokba tervezett módosítások is beérjenek, plusz lesznek új hardverek, tehát lehet majd használni is a rendszert.[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
válasz
#72042496
#18811
üzenetére
Hamarabb lesz itt HDMI 2.1. Szerintem az NV is beadja a derekát, annyira szabvány ez, hogy felesleges küzdeni ellene. A VRR meg opcionális. Azt letiltják és kész, a HDMI Forum eleve úgy írta meg a specifikációt, hogy letiltható legyen, akinek sérti az érdekeit.
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
válasz
#72042496
#18808
üzenetére
Itt inkább elvek csapnak össze. A HDMI 2.1-et most is be lehetett volna építeni, de a VRR-rel nincsenek kibékülve. Nekik az az elképzelésük, hogy a BFGD-k fogják elvinni a tévépiacra a G-Sync-et. A tévégyártókat is ebbe akarják belekényszeríteni, emiatt tehát a HDMI VRR egy ellenség, és maga a HDMI is, hiszen a BFG DisplayPortos technológia. Ez most valószínűleg egy farokméretegő időszak lesz, mert az NV a terveivel közvetlenül szembekerül a HDMI Forummal. Nagyon fontos a BFGD specifikáció, ami megköveteli az adott gyártótól a HDMI 2.0b-t, vagyis hiába lehetne HDMI 2.1-et építeni a nagy kijelzőre, a gyártóknak ezt az NV megtiltja. Ez meg a HDMI Forumnak nem tetszik.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
válasz
Dyingsoul
#18801
üzenetére
VRR. A HDMI Forum szabványos variálható frissítési frekvenciája. Ez kimaradt, ugyanaz marad a display engine a Turingban és Voltában, mint a Pascalban, így a képességei is megegyeznek, vagyis marad a DP1.4 és a HDMI 2.0b. A VirtualLink igazából nem igényel új display engine-t, az egy végtelenül egyszerű fejlesztés, noha persze eléggé hasznos. Aki HDMI VRR-t várt, tényleg csalódott lehet, azt megértem, más csak felült a hype-re, szvsz.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
válasz
Dyingsoul
#18799
üzenetére
Szerintem alapvetően az a baj, hogy iszonyatosan nagyok az elvárások. Borzalmasan fel lett hype-olva az egész, így ha jó is lesz, többen nagy csalódásként fogják megélni. Én amit láttam a 2080-ból és a 2080 Ti-ből, (ezek jönnek ugye hamar, aztán nem sokkal később a többi) az nem rossz. Ha nem lenne a nagy hype, akkor tetszene szerintem mindenkinek, csak azok lesznek szomorúak, akik HDMI VRR-t várnak, ők joggal lehetne csalódottak, a többiek csak a hype áldozatai.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
Mázlid van.
Nem valós az 1700. Az 2080 Ti 13xx(közepe) MHz-es alap és a 15xx(közepe) MHz-es boostot kap (gyártófüggően, ezek a tipikus OC paraméterek). A 2080 esetében ez 1500 alap és 1700 boost környéke. A referencia ezeknél alacsonyabb, de nem sokkal, viszont tudjuk úgyis, hogy minden gyártó OC-mániás, ha kell 10 MHz-et is rádobnak, és akkor OC Edition. (#18768) Pitralon: Elméletben lehetne, de egyrészt a sávszél sokkal kisebb lenne, másrészt a GDDR6 esetben az ár csak ideiglenesen nagy. Ha két hónapot benyelnek, akkor az év végére a GDDR6 memóriák hasonló áron fognak menni, mint a GDDR5-ök, tehát emiatt nem sok értelme van GDDR5-öt használni.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
De a sávszél eleve a memóriából jön. Értsd ezt úgy, hogy attól a Samsung és a Hynix sem fogja olcsóbban adni a GDDR6-okat, mert az NV azokat nem 14, hanem 10 vagy 12 Gbps-on akarja használni. A Micron meg ugye a kínai szopatás miatt nagyrészt kiesett, vele megegyezhetnek a gyártók a nyugati régióra, de az NV nem tudja Kínába szállítani a Micron memóriákkal szerelt VGA-kat. Tehát van egy "húzófícsőr", ami persze a Metro Exodusig csak duma lesz, de kell neki a sávszél, így a Metro Exodus alatt jól jön majd neki, és eleve nem lesz olcsóbb semmivel egyetlen hardver sem, ha a sávszél csak kevesebbet nő.
Ugyanez lesz a Vega 20-nál, mielőtt az is értelmetlenné válna ilyen formában. Annak sem kellene 1,2 TB/s, sőt, még 1 TB/s se, de a Samsung nem kínál lassabb memóriát. Tehát akkor is ki kell fizetni ugyanazt az árat, ha az elméleti tempónak csak a ~70%-át fogod be. Így meg már ugye miért is ne használnád, amiért fizettél?(#18699) atok666: Miért menne másnál rosszul? Ezek a gyártói szerződések csak pár eljárásra/effektre vonatkoznak. Ha Radeonosként nem tetszik az NV effektje kapcsold ki, ha GeForce-osként nem tetszik az AMD-é, hát megint kapcsold ki. Az alapkód, amit gyakorlatilag nem szerződéses formában raktak össze, jellemzően úgy van megírva, hogy igen jól menjen mindenen. Ha nem, akkor pedig jellemzően mindenen rosszul megy, tehát mindegy.
Az pedig egy üzleti kérdés, hogy ki melyik gyártóval pacsizik. Nyilván a gyártók és a stúdiók/kiadók is keresik az igényeiknek megfelelő partnert. Nagyrészt azért változtak meg a korábbi viszonyok, mert a Bethesda a PC-s R&D-t kiszervezte az AMD-hez, ami annyira sok rendszerprogramozót elvitt más stúdióktól, hogy az EA/DICE és a Square Enix nyugati stúdiócsoportja más partnert keresett. Az Ubisoft pedig nem volt elégedett az NV-vel, így azt csinálták, hogy mindhárom IHV-val megegyeztek egy-egy címre (NVIDIA-Ghost Recon: Wildlands, Intel-Assassin's Creed: Origins, AMD-Far Cry 5). A tapasztaltok alapján pedig úgy döntöttek, hogy az AMD-vel akarják a jövőben folytatni. Ezek tényleg nagyon egyéni döntések, minden stúdió/kiadó igénye más, ráadásul változik is, de sosem az a cél, hogy kiszúrjanak a piac nagy részével, a gyártói szinten favorizált elgondolások mindig kikapcsolhatók.(#18701) hoolla: Hardveres értelemben az SLI megszűnik. Formálisan megmarad, mert egyszerűen túl sok kód tartozik hozzá, amit visszamenőleg átírni eléggé macerás, nem is túl célszerű. De az NVLink igazából nem kötődik nagyon az SLI-hez, ez egy memóriakoherens interfész, így úgy is lehet írni egy alkalmazást, hogy a két GPU látni fogja egymás memóriáját. A legacy kódbázis persze megmarad, de aki új programot ír, annak nem tudom mennyi értelme van erre építeni, maximum a régi hardverek miatt.
Explicit API mellett pedig eleve nem létezik maga az SLI sem, illetve az NVLinket sem képesek értelmezni a jelenlegi API-k.(#18722) Mirman: Akkor vertikálisan fogunk építkezni. Wafer-on-wafer koncepciók, akár egyszerű tükrözött, vagy bonyolultabb, chiplet formában. Utána pedig költözik minden a proci tokozásába.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
Mindenki így gondolkodik. Ha a húzófícsőr megköveteli, akkor a lehetőségekhez mérten a maximumot hozzák ki a memória-sávszélességből.
(#18661) Jack@l: Húzni lehet mindent, de a legelső adat az volt az új generációról, hogy 14 Gbps-os GDDR6-ot kapnak. Ezt az NV memóriagyártó partnerei többször is elismerték. Ez egyébként teljesen normális. Alig van olyan fejlesztés, amikor helyből a határra ugranak, mert túl kockázatos lenne. Ráérnek erre majd a második körben. Az első körös fejlesztések egy új memória bevezetésénél mindig az optimális "szemábrát" célozzák, innen lehet jól továbblépni. A Vega 10 is csak most kapott 2 GHz-es HBM2-ket, annak ellenére, hogy már egy éve ezekkel szerelik a hardvert. Ugyanez volt az ok. Az optimális "szemábrát" érdemes célozni. Ezt is húzhattad persze, de egy gyártónak nem elég ha valami két-három óráig stabil a 3DMarkban.
(#18662) b. : A textúrarészletesség egy olyan dolog, ami nem befolyásolja igazán a teljesítményt. Ennek az oka, hogy a mintavételezés a felbontáshoz kötött, a textúra minősége csak a minta minőségén javít, de a mintavételezés mennyisége egységnyi felbontáson ugyanannyi low és high textúrával is. Az egyetlen ami számít az a memória mennyisége, hiszen a textúraminőség javulásával a memóriaigény sokszorosára nő.
A konzolt azért nem érdemes idevenni, mert iszonyatosan másképp működik. Valójában a játékok nem igényelnek annyi memóriát, amennyit amúgy kell nekik adni a gyakorlatban. Az teszi őket rossz hatásfokúvá, hogy a memóriához nincs hozzáférésük. Amikor lefoglalnak valamit a rendszermemóriában, akkor valójában megkérik az operációs rendszert, hogy foglalja le nekik. Minden memória-hozzáférés közvetett, valamilyen szoftveres rétegen keresztüli. A konzolt az teszi annyira hatékonnyá a memória kezelése szempontjából, hogy ott nincs a játék és a memória között egy szoftveres réteg. Ki van jelölve a nyers memória, 5-6-8 GB, konzoltól függően, és ehhez annyira közvetlen az elérés, hogy az operációs rendszer nem is látja mit csinál benne egy program, amivel ráadásul teljesen az adott igényre tervezhető a menedzsment. Ez a módszer lenne jó PC-ben is, mert közvetlenül kezelhető a fragmentáció, nagyon olcsó az allokációk menedzselése, illetve egészen egyedi stratégiák is kialakíthatók. De érthető okokból ilyen PC-n nincs, mert ez nem egy fix hardver, itt kismillió konfiguráció van, vagyis inkább az van, hogy az operációs rendszert kell utasítgatni, ami a memória kezelésének problémáját általánosan elintézi, és azért általánosan, mert fingja nincs ám a OS-nek arról, hogy egy alkalmazásnak mi a jó. Ilyen formában nem lehet mit kezdeni a fragmentációval, és az egész viszonylag nehezen menedzselhető, de hatalmas előny, hogy nem számít a szoftver mögötti gép, akkor is fut a program valahogy, ha 4-5-6-7-8...akárhány GB memória van. Ez az előny viszont nagy áldozattal jár a hatásfok oldalán. A VRAM nagyjából ide kapcsolódik be, ami a Windows esetében közvetlenül a WDDM által van kezelve. Itt is ugyanaz az előny és a hátrány, mint a rendszermemóriánál. De muszáj így csinálni, mert ilyen formában 2-3-4-5-6...akárhány GB-os VGA-n is futni fog valahogy a program. A hatásfok pedig ott romlik, hogy allokációkat kell másolni. Mindegy, hogy abból hány kB kell az alkalmazásnak, akkor is be kell másolni az egészet, ami lehet sok-sok MB is. És a gyakorlat azt mutatja, hogy általában egy mai játéknál a VRAM-ba kerülő tartalom fele-kétharmada a futtatási idő nagyon nagy részében nem is szükséges. De nem tudod eltávolítani az allokációt, mert lehet, hogy kell még belőle pár kB-nyi információ, és ezért ott kell terpeszkednie a VRAM-ban a sok-sok MB-os helyigényével. Szóval elméleti szinten nagyon elég lenne még a 4 GB VRAM is, csak a szoftveres háttér, ami ezt az egészet működteti túl pazarlóvá vált. A konzolokat ez önmagában nem érinti, mert ott van a memória és a program. Köztük viszont nincs semmi, ami pazarolni tudna. Ez a probléma tisztán PC-specifikus, és az okozza leginkább, hogy kismillió eltérő hardverkonfiguráció létezik, amit csak így lehet garantált kompatibilitás mellett lekezelni. Végeredményben tehát egyáltalán nem a hardverek a szarok, vagy alultervezettek, hanem a szoftveres háttér pazarol nagyon, és ezzel nehéz mit kezdeni. Oké a VRAM-ra vonatkozó problémákat kezelheted lapalapú menedzsmenttel, és kipipáltad a WDDM pazarlását, de ettől még a rendszermemóriával nem tettél semmit. Nem is igazán lehet mit kezdeni vele. Dobsz cuccokra még RAM-ot, mert a brute force lehetőség azért még működik.[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
válasz
Jack@l
#18656
üzenetére
Ez erősen játékfüggő.
Nem downclockolnak semmit. Ennyit bír a dizájn, illetve a Hynixtől 14 Gbps-os memóriákat vesznek. A Samsung 16 Gbps-osakat árul, de nem tudja ezt az órajelet a memóriavezérlő és a tervezett NYÁK.[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
A ray-tracing számításának azért vannak sávszélt lezabáló részei, tehát annyira azért nem meglepő, hogy itt bővítettek erősebben.
(#18651) b. : Mondok jobbat. Csak az extrém magas memóriaárak miatt van ez. Eredetileg 24 GB-ról lehetett hallani csúcskártya szintjén. De hát tudta a fene, hogy a memóriagyártók kartellezni fognak, és úgy felnyomják a DRAM árát, hogy le kell vinni 11 GB-ra. Ezzel most az NV sem tud nagyon mit kezdeni. De nem is igazán kell, megmondják a szoftverpartnereiknek (EA/DICE, Square Enix, Warner), hogy beszopta az ipar a RAM-okkal, mert kétségtelenül beszopta, így szelektálják ki azokat a textúrákat, amelyekből elég csak a közepes minőségűt szállítani. Végeredményben nem egy nagy probléma, még a játék mérete is kisebb lesz.
Egyedül azzal kell megküzdeni, hogy az AMD ennek az ellentettjét fogja nyomatni a saját partnereiknél (Ubisoft, Bethesda, Capcom). Ez a része izgi lesz.
Hosszabb távon úgyis nő majd a memória kapacitása, már csak azért is, mert nem valami acélos, amit eddig mutattak a fejlesztők memóriamenedzsment címén az explicit API-kban. Én ha a Microsoft helyében lennék, simán lemásolnám DX12-be az AMD VMA-ját, és hoznák legalább egy opcionális funkciót a dedikált allokációra, utóbbi az NV-nek nagyon sokat segítene, előbbi meg kvázi mindenkinek. De gondolom a Microsoft szarik bele, jó ez így, úgy vannak az egésszel.[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
Szerintem együtt láttuk, hogy az egyik pillanatban még elég volt 2 GB a VGA-kon, aztán beütött az explicit API, és hirtelen 8 GB kellett. Rohadtul nem egyszerű ám a megfelelő memóriamenedzsment megírása. Nem véletlenül rohant az Intel és az AMD egy hardveres megoldás irányába.
(#18640) huskydog17: Sose mondtam, hogy nem az elbaszott memóriamenedzsment ennek az oka. Nyilván amikor hirtelen elkezdtek 8 GB-ot követelni a játékok minden előjel nélkül, akkor nem az történt, hogy nagyon megugrott a minőség. Egyszerűen csak az allokáció-alapú menedzsment nem kielégítő egy bizonyos terhelés felett. Ezért lett bevezetve a lapalapú menedzsment.
Észre lehet venni, hogy a legtöbb motorban, különösen a Frostbite-ban a DX11-es módról DX12-re kapcsolva, architektúrától függően azért 1-1,5 GB-ot szemetel a motorba épített memóriamenedzsment. Nem azért, mert annyira megugrik a grafikai minőség, hanem azért, mert rosszul van megírva. De a nagyobbik gond, hogy annyira nehéz jól megírni, hogy a legtöbben nem is fektetnek bele erőforrást, kicsit átszabják a Microsoft Residency Starter Library-t és úgy megy is ki. Ugyanez igaz Vulkan API-ra, csak ott azért az AMD VMA library sokkal fejlettebb, illetve van dedikált allokációra kiterjesztés, tehát effektíve több lehetőség van arra, hogy jó memóriamenedzsmentet kapjon egy játék.[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
válasz
keIdor
#18629
üzenetére
Az lesz az izgi meccs, hogy az NV azért fog puncsolni, hogy ne fussanak ki a memóriából, míg az AMD azért, hogy futtassák ki őket. Tényleg nem nehéz ezt megcsinálni egy 8 GB alatti VGA-val, míg a Vegának mindegy a memóriaigény, ~16 GB-ot is lekezel úgy, hogy a hardveren fizikálisan 2 GB van. Ezért megy a HBCC-s Kaby Lake-G-n is folyamatosan az alapvetően 14 GB VRAM-ot igénylő ME: Shadow of War maximális textúrákkal.
Mindenképpen itt fogják ütköztetni az akaratukat, hiszen tényleg ellentétesek lettek az érdekeik. Az AMD-nek innentől az a jó, ha brutális, akár 8K-s textúrákkal szállítja a partner a játékot, míg az NV-nek az, ha közepes, leginkább 2K-s méretűekkel. A legtöbb fejlesztő gondolom behúz majd középre, mert egyrészt a 4K az ideális, másrészt mondhatják a cégeknek, hogy a 8K nagyrészt faszság, a 2K pedig nagyrészt kicsi. Szóval egyiknek se tettek a kedvére, és pont.[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
válasz
 NightGT
#18608
üzenetére
NightGT
#18608
üzenetére
Nem, de drága nagyon a DRAM. Felkarterezték az árát. Emiatt jön ilyen 11 GB, stb, mert egy lapkán is hatalmasat lehet spórolni. Mindeközben az egész helyzetet tudja úgy kezelni az NV, hogy a partnerstúdiókkal lebeszélik, hogy ne használjanak már olyan sok VRAM-ot, amit eléggé egyszerűen el lehet érni, ha nem szállítják mondjuk a legnagyobb tervezett textúrákat, stb. Egyedül az AMD lesz a probléma, mert ők pedig pont azt fogják mondani, hogy de-de szállítsátok csak, a Vegának pont ez az erőssége. Szóval izgi lesz.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
válasz
 hoolla
#18526
üzenetére
hoolla
#18526
üzenetére
A bányászat miatt a legtöbb fejlesztés eleve csak állt a fiókban. Tehát ez most nem olyan start, mint régen. Ha nem lett volna bányászláz, akkor már kint lenne több új termék is, de sajnos volt. Emiatt is tűnhet furcsának, hogy nem 7 nm-en jönnek, de ezek amúgy hamarabb jöttek volna "túrás nélkül". Mivel a túrásnak annyi, így ömlesztve megéri frissíteni. Nem mindent egy héten belül, de a szokásosnál gyorsabban lezavarva.
Persze a Vega 20-ból bármikor csinálhatnak halandó verziót. Az Instinct minta kint volt a SIGGRAPH-on. Elzárták, de nem elég jól, ilyen Nano-szerű apróság 1 darab 6 tűs PCI Express csatival. Úgy néz ki fizikailag, mint az Instinct MI6 a csicsák nélkül.
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
válasz
 Looserke
#18524
üzenetére
Looserke
#18524
üzenetére
Ők a TSMC-nél minden új lapkát 7 nm-re visznek. A GloFo-nál elvileg lesz még egy GPU 12/14 nm-es node-on (azt nem tudom, hogy 12 vagy 14 nm-en, de igazából majdnem mindegy, olyan hatalmas különbség nincs a 12/14/16 nm-es node-ok között - sőt alig van, a nanométer előtti szám nem igazán jó indikátor). Később a GloFo esetében is EUV-s 7 nm-re váltanak, de tudtommal csak a Matisse CPU-ra vonatkozóan, ami gyakorlatilag ugyanaz, amit a TSMC-nél készítenek a szerverekbe. A GPU marad a TSMC-nél.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
válasz
hoolla
#18520
üzenetére
A Vega 20 elérhető lesz az adatközpontokba idén. Erre a SIGGRAPH-on volt utalás, de arra nem, hogy máshova mikor jön, viszont a lapka kész, ősszel már a végleges mintákat szállítják.
Azt figyelembe kell venni, hogy a TSMC-nek egyelőre az EUV nélküli 7 nm-es node-ja érhető csak el. Az EUV-s 7 nm-es eljárás kísérleti gyártása csak jövőre kezdődik meg (kicsit most a vírus is bekavart, így a TSMC a kísérleti gyártások eltolásán próbálja behozni a rendelésekben keletkezett elmaradását), és a tényleges, tömeggyártáshoz szükséges gyártósorok elérhetősége legalább egy év múlva esedékes. Az NV mindenképpen az EUV-s 7 nm-re ugrik, mert a mostanit túl drágának tartják. Az AMD-nek az EPYC-ekkel a hátuk mögött ez belefér, de az NV-nek csak GPU-ja van ide, amivel a mostani waferár nem realitás, és tavasszal sem lesz az, mert akkor sem lesz EUV-s node.
Egyébként a költségek szempontjából nem járnak rosszul. A 7 nm-es váltás eleve egy olyan tényező, hogy ami mondjuk 12 nm-en egy 600 mm2-es lapka, az 7 nm-en kb. 380-400 mm2- lesz. De árban ettől még nem lett olcsóbb, mert a 7 nm-es waferek legalább ennyivel drágábbak is.[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.


 Aki UE4-gyel akar DXR-t, annak magának kell implementálnia. Az EPIC egyhamar nem teszi ezt meg.
Aki UE4-gyel akar DXR-t, annak magának kell implementálnia. Az EPIC egyhamar nem teszi ezt meg.

 Ez nem véletlen, mert meg lett kérdezve az MS által egy rakás user, és sokan a DXR offot mondták szebbnek. Igazából alig látszik a hatása. Inkább úgy fogalmaznák, hogy a DXR on/off más, de egyik sem szebb a másiknál. Ezért is döntött sokszor az ízlés.
Ez nem véletlen, mert meg lett kérdezve az MS által egy rakás user, és sokan a DXR offot mondták szebbnek. Igazából alig látszik a hatása. Inkább úgy fogalmaznák, hogy a DXR on/off más, de egyik sem szebb a másiknál. Ezért is döntött sokszor az ízlés.



 De ez még nem végleges, idén valószínűleg nem is lesz az.
De ez még nem végleges, idén valószínűleg nem is lesz az.








 Plusz az online rész folyamatos üzemeltetési költsége.
Plusz az online rész folyamatos üzemeltetési költsége.















![;]](http://cdn.rios.hu/dl/s/v1.gif) Hacsak nem tervezik végre bele a modellt a megjelenítésbe, és akkor végre lesz lábunk is, juhhu.
Hacsak nem tervezik végre bele a modellt a megjelenítésbe, és akkor végre lesz lábunk is, juhhu. 










Új hozzászólás Aktív témák
A topikban az OFF és minden egyéb, nem a témához kapcsolódó hozzászólás gyártása TILOS!
MIELŐTT LINKELNÉL VAGY KÉRDEZNÉL, MINDIG OLVASS KICSIT VISSZA!!
A topik témája:
Az NVIDIA éppen érkező, vagy jövőbeni új grafikus processzorainak kivesézése, lehetőleg minél inkább szakmai keretek között maradva. Architektúra, esélylatolgatás, érdekességek, spekulációk, stb.


- EVGA Nvidia GTX 1080 Ti FTW3 ICX 11Gb
- GeForce RTX 3080 Ti GAMING OC 12G - Gyári Garancia
- BESZÁMÍTÁS! Gigabyte RX 6800 XT Gaming OC 16GB videokártya garanciával hibátlan működéssel
- BESZÁMÍTÁS! ZOTAC Trinity RTX 3070 Ti OC 8GB videokártya garanciával hibátlan működéssel
- PowerColor Radeon Hellhound RX 6600 XT 8GB - GARIS
Állásajánlatok

Cég: Axon Labs Kft.
Város: Budapest

Cég: PCMENTOR SZERVIZ KFT.
Város: Budapest