- Linux programok topic - (Milyen program, ami..? Linux verzió)
- One otthoni szolgáltatások (TV, internet, telefon)
- Starlink
- Vége: a kínai platformok nem adják vissza a pénzt visszaküldött áru nélkül
- Mikrotik routerek
- Sweet.tv - internetes TV
- Microsoft Edge
- Mozilla Firefox
- Nemzetbiztonsági aggályok merültek fel a TP-Link kapcsán
- Windows 11
Új hozzászólás Aktív témák
-
#1950
 aprokaroka87
nagyúr
S_x96x_S
#1949
aprokaroka87
nagyúr
S_x96x_S
#1949
aprokaroka87
nagyúr
-
-

woryz
senior tag
válasz
 S_x96x_S
#1916
üzenetére
S_x96x_S
#1916
üzenetére
Még ugyanazon a felületesen se kapsz - ugyanazzal a modellel - pontosan ugyanolyan választ.
Mondjuk ez nagyon igaz, nem tudom mit gondoltam... Sőt néha kérek egy pontosítást a saját szövegemen, majd 2-3 (stb) kérdezz felek után visszajutunk 99%-ban az én szövegemhez.
Sőt néha kérek egy pontosítást a saját szövegemen, majd 2-3 (stb) kérdezz felek után visszajutunk 99%-ban az én szövegemhez. 
Akkor nincs más hátra, mint előre és tesztre fel... Meglássuk, melyik fog nekem tetszőbb választ adni, de akkor a perplexity-t inkább improved Google-nek tekintem a jövőben, és nem variálok a modellekkel (mondjuk chat GPT-n se variáltam eddig rajta
 )
) -

freeapro
senior tag
válasz
S_x96x_S
#1907
üzenetére
Én ezt a kérdést dobtam be chagpt, deepseek r1, és grok-3 -nak. A chatgpt válasza állt legközelebb ahhoz amit én is gondoltam. A grok-3 is hasonlót adott, a deepseek viszont nem teljesen standard megoldást javasolt #pragma once paranccsal a standard define guardos megoldás helyett. (Nem rossz az sem, csak minek. Jobb a standard út)
Egy windowsos programon dolgozom. C nyelven készül a visual studio projekt. A program kódja nagyon doménekre (domain) bontható, mint a WinMain ablakkezelés, Editor az adatbászis létrehozására és módosítására és a RUN, ami az adatbázison futtat bizonyos feladatokt. A domainben vannak függvények, amik interfacek, és másik domainből meghívhatók, és vannak belsős (internal) függvények, amik a domain belső működéséhez szükségesek. Azt szeretném, ha a domének között kis csatolás és korlátozott láthatóság lenne, de a domainben használt közös változókat egy struct változóban összegyűjteném amit a domainben mindenki elérhet. Hogyan szervezzem a header filekoat és mit tegyek láthatóvá a domainen kívül és hogy legyenek láthatóak a belső függvények a domainen belül? Mutass példákat.
-

S_x96x_S
addikt
válasz
S_x96x_S
#1882
üzenetére
(több gép összekapcsolás - TB5 + 2db M3 Ultra 512GB
Terv: 11 tok/sec jelenleg --->> 20 tok/sec --->> 40 tok/sec"Thunderbolt 5 interconnect (80Gbps) to run the full (671B, 8-bit) DeepSeek R1 distributed across 2 M3 Ultra 512GB Mac Studios (1TB total Unified Memory). Runs at 11 tok/sec. Theoretical max is ~20 tok/sec."
https://x.com/alexocheema/status/1899735281781411907"We’ll keep improving it in @exolabs. Once we approach the “theoretical maximum”, there’s a bunch of other stuff we can do to surpass it for sparse MoE, e.g. expert parallelism. I think we can get to 40 tok/sec."
https://x.com/alexocheema/status/1899737017866719506 -

DarkByte
addikt
válasz
S_x96x_S
#1885
üzenetére
Gbps vs GB/s.
Az az összehasonlítás értelmetlen, a 70B Q4-nek kell közel 40GB VRAM.
Mivel a 24GB-ba nem fér be, beindul a RAM spillover, és onnantól kezdve a rendszer memória sebességét méred egy totál lefolytott 4090-el párosítva.Tipikus idióta marketing. Olyan mint hogy az 5070 hozza a 4090 sebességét játékokban. Persze, csak azt elfelejtették írni hogy DLSS4 és framegen mellett. Natív teljesítményben a 4090 lenyomja mint Süsü a cölöpöt.
-
DarkByte
addikt
válasz
S_x96x_S
#1881
üzenetére
Tisztában vagyok a destillation fogalmával (egy kisebb másik modellt tanítottak be, a nagyobbik modellt tanító modellként használva).
Nyilván ez sosem lesz ekvivalens a naggyal, de a nagyot meg esélyünk sincs lokálban futtatni, csak ezeken a böhöm dögökön amiket linkeltünk.
A Qwen-2.5 alapú DeepSeek 32B szerintem meglepően ügyes.
Mindegyiket a képességeinek megfelelően kell kezelni. Épp a napokban láttam egy ilyen videót hogy melyiknek milyen komplexitású feladatokat érdemes adni. [link]--
#1882: oké, de ez még mindig alig 1GB/s-es tempó, összehasonlítva mondjuk egy 4090 1008GB/s VRAM sávszélességével, megmosolyogtató.
De még akár a PCIe 4.0 8x/16x 16/32GB/s-es tempójával összehasonlítva is jelentős a különbség, és már az is eléggé megcsapja a sebességet ha két kártyának a PCIe buszon keresztül kell kommunikálnia. (konzumer NVLInk pedig ugye nincs) -
DarkByte
addikt
válasz
S_x96x_S
#1872
üzenetére
Mondjuk ezek a 3B és 8B modellek elég limitáltak sajnos.

Gondolkodós modelleknél még kevésbé elég ez a méret, pl. Deepseek R1-nél azt mondják a 14B a legkisebb amivel érdemes foglalkozni.Egyébként side projektnek nekem is listán van megnézzem mire lehet menni egy kis modellel. Van pár kihasználatlan Raspberry Pi 4 4GB-om, és nem real time LLM használatra éppenséggel befoghatóak lennének, egy gemma2:2b-instruct-q4_K_M elmegy rajtuk ahogy olvastam. Olyesmikre akartam megnézni mennyire bevethetőek, mint pl. időzített taszkban egy oldal szövegéből tartalom kinyerése és mondjuk egy Discord bot-on át továbbítás. Esetleg RSS feed-ek szűrése tag-ek szerint.
Ilyesmikre szerintem még képes lehet. -
Zizi123
senior tag
válasz
S_x96x_S
#1829
üzenetére
Akkor jól láttam, hogy olyan, mintha notebook memóriával lehetne bővíteni, na de itt ez már probléma is, hogy az viszont nem gyors....
Tehát ha hiszünk abban, hogy a memória mennyiség mellett, a memória sávszélesség a legfontosabb a nagy LLM-ek használata közben, akkor ez eleve kizárja azt, hogy világverő legyen.
Ha jól gondolom, akkor a 12 csatornás Pl Epyc szerverek memória sávszélessége 576 GB/s, ami "duplája" ennek a tervezett kártya a sávszélességének, és arra jutottunk, hogy a dual Epyc szerver alkalmatlan a nagy nyelvi modellek futtatására, mert tetű lassú.
A Mac Studio M3 Ultra 819GB/s, az RTX 4090 1008GB/s, H100 NVL 3.9TB/s.
Most 2025 elején...
2027 elején már nem ezek a számok lesznek.Tehát nem teljesen vágom, hogy is lesz ez világverő, de nyilván csak valamit nem vettem figyelembe.
-
Zizi123
senior tag
válasz
S_x96x_S
#1819
üzenetére
Ha lenne annyi mFt-om amennyi ilyen ígéretes világmegváltó kártyából nem lett semmi...
Mivel bővíthető egyébként, milyen memóriával?Arról nem is beszélve, hogy az még durván 2 év mire ebből leghamarabb lesz valami. Kicsit csúszik majd, és mire piacra kerülne lesznek sokkal jobbak, és így el sem kezdik gyártani...
-
DarkByte
addikt
válasz
S_x96x_S
#1806
üzenetére
Nézzétek meg Karpathy videóját (most már van második része is). Tök jól elmagyarázza az LLM-ek működését, korlátait. Szerintem tananyag szintű amit ebben a két videóban átad.
Pl. ezt az "r" betű számolást is elmagyarázza, hogy azért hülyeség, mert az LLM nem is karakterekben "lát", mivel token-ekkel dolgozik, amelyek tömörítenek több karaktert egy új szimbólumba.
Ami "fejben számolást" ("mental arithmetic") igényel egy LLM-nek azt mint jó eséllyel elrontja a legtriviálisabb példákat leszámítva. (Ahogy te sem tudsz összeszorozni akármekkora számokat fejben hozzáteszem.) Ahogy Karpathy is mondja, az ilyeneknél inkább meg kell kérni írjon egy Python programot ami kiszámolja a problémát. (ahogy te is előveszel számológépet a nehéz problémáknál)
-

consono
nagyúr
válasz
S_x96x_S
#1806
üzenetére
De ez "buta" kérdés egy LLM-nek... A token predikcio definíció szerint nemntud számolni, nem tudom miért várjuk el.... Látszik is, hogy ami tud válaszolni az valami kerülő algoritmussal válaszolja meg a kérdést.
Persze arra meg pont jó ez a kérdés, hogy rávilágítson arra, hogy nem mindenre jók az LLM-ek, nem minden a diffúzió, meg az attention. -

5leteseN
senior tag
válasz
S_x96x_S
#1800
üzenetére
Igen,
 ez volt az az adat, amire említettem is, hogy nem 100%, hogy jól emlékszem.
ez volt az az adat, amire említettem is, hogy nem 100%, hogy jól emlékszem.Ez már egy szép érték, ehhez jön szűk keresztmetszetként a gépek közötti Thunderbolt 5-ös 120Gbps-ából a kb (általam becsült ! )valósnak tippelt és konvertált 10GBps x 4-5-6(Tb-5).
...ha kell majd egyáltalán egy M3 Ultra felhasználónak, mert ugye az 512GB-ba már minden "civilnek" szánt LLM bele fog férni aki rászánja az x-millió(mennyi is ) HUF-ot/€-t/$-t...
) HUF-ot/€-t/$-t...A piaci-keresleti mérleg serpenyőjében ott leszünk még sokáig majd az ehhez képest sokszor több millióan a korábbi(tipikusan 8-16GB között VRAM-mal szerelt) VGA-kal .
Ezek miatt a piaci arányok miatt nem aggódok azon, hogy nem lesznek rövid időn belül az általam említetthez hasonló további megosztott szoftverek illetve általános+célterület LLM párosítások. A mostani (valóban megdöbbentően eredményes ) Instruct-modelles szoftver alkalmazás mutatja az ebben rejlő lehetőségeket.Józan fejlesztő csoportok (szerintem) szntén eljutottak eddig a lehetőségig, és (úgy gondolom, hogy) már dolgoznak erre a logikusnak tűnő szoftver-válaszon.
...megemlítettem, mint egy (nekem logikus)lehetőség a naponta felbukkanó újak között!
Megtaláltam közben: az 512GB RAM-os Ultra M3 4,5millió HUF.
-
Zizi123
senior tag
válasz
S_x96x_S
#1797
üzenetére
Bár a tenyérben elfér-t jelképesen értettem, és nem raktam " " jelek közé azért a 7cm-es méretkülönbség nem 1 kardinális különbség, nekem kis tenyerem van, de a kb 20cm még nekem is elférne benne....
Mac Studio:
Magasság: 9,5 cm
Szélesség: 19,7 cm
Mélység: 19,7 cmMacMini:
Magasság: 5 cm
Szélesség: 12,7 cm
Mélység: 12,7 cmEllenben a Supermicro Dual Epyc szerverével szemben ami
Magasság:: 178 mm
Szélesség: 437 mm
Hosszúság: 737 mm1 Epyc CPU hűtő majdnem olyan nehéz, mint maga a Mac Studio...
-
5leteseN
senior tag
válasz
S_x96x_S
#1796
üzenetére
A más IT technológiák hasonló párhuzamos működése alapján, ezeket az adatokat:

...figyelembe véve, én úgy tippelem, hogy a (kb csak) laboros körülmények(között lehetséges) 120Gbps-os sebességéből a valóságban 100Gbps lesz.
A szintén IT-technológiák párhuzamosításából átemelve a gyakorlati tapasztalatokat (Pl CPU-k, és sok más terület...), az első almás-kütyü RAM-sebessége(ha jól emlékszem 250GBps körüli). A "Fő-gépet" teljes (250GBps-os) teljesítménnyel számolnám, de a többit kb. 0,7-es szorzóval.
Ez alapján (szerintem):
1, Az öt Tb5-ös rendszer adatátviteli sebessége "összesítve" kb (250GBps+(4x10GBps x 0,7)=320-350GBps.
2, A négy TB 5-ösé pedig a "százassal" csökkentett: 280-300GBps.
(Nem véletlen lett a B vastagbetűs: a bit/s-t "áttettem" kb Byte/s-be.)
Ha jól tudtam az fő-(almás-)gépben meglévő RAM-sebességet, akkor ennyire tippelem a valós számokat. Ha nem akkor ezzel a jó értékkel behelyettesítve érvényes.Magánvélemény:
1, Nem estem hasra! Ez kb a jelenlegi 2080Ti-m sebessége(616GBps), alatti bőven, egyetlen (de nagy)előnye az almás konfignak(a meglévő brutálka hype-presztízs mellett), hogy a 2080Ti-nek csak 22(-44GB ) VRAM-ja van, a 3090-eknek pedig "csak" 24GB.
Ez kb a jelenlegi 2080Ti-m sebessége(616GBps), alatti bőven, egyetlen (de nagy)előnye az almás konfignak(a meglévő brutálka hype-presztízs mellett), hogy a 2080Ti-nek csak 22(-44GB ) VRAM-ja van, a 3090-eknek pedig "csak" 24GB.2, Ez a leírtak alapján megtett saját becslés. Tévedhetek is.

3, Érdekel majd a tényleges (teszt-)érték: pár hónap!!
![;]](//cdn.rios.hu/dl/s/v1.gif)
Ilyen értékekre lehet hogy nem lesz teszt, de a gépek közötti teljesítmény különbségből megállapítható lesz, hogy a kettő kiépítés(öt Tb 5-ös vs. négy Tb 5-ös) közötti különbség ennyi lesz-e?
Szerintem a szoftveres feladatmegosztás és csak ezek eredményeinek mozgatása sokkal többet hozna a konyhára!
A valós élet példájából "pont most" :
A kis(04-1,5GB-os) előkészítő LLM 30-80%-kal növeli a hozzá jól illeszkedő nagy(kb 6-20+ GB-os) LLM hatékonyságát.
Az pedig egy sokkal kisebb programozási feladat(szerintem már dolgoznak rajta), hogy a kis LLM egy "kis" VRAM-os/kis teljesítményű kártyái is igénybe vehessen, mert egy PCIe3-4-5(SLI-Crossfire) elég a két(több) kártya közötti kommunikációra, hiszen ekkor "csak" az előzetes eredményeket kell továbbítani.Az AI-MI-re vágyó átlagos(fizetőképességű) felhasználók széép-nagy tömege miatt lesz ilyen irány is!
Még mindig: szerintem, de !Széljegyzet: remélem, hogy jól értelmeztem az idézett képen lévő Gbps-t: "Gigabit per secundum"!
-
Zizi123
senior tag
válasz
S_x96x_S
#1790
üzenetére
Háááát akkor nagyon úgy néz ki, hogy ez lesz a befutó a DeepSeek R1 Q4 lokális futtatására a Dual Epyc, vagy hibrid rendszer helyett, és még árban is partiban van a csak CPU-s megoldással.
Teljesítményben viszont biztos, hogy sokkal gyorsabb, de azért kíváncsi lennék mennyivel...Várom a review-kat róla...Azért vicces, hogy 1 tenyérben elfér, és sokkal gyorsabb lesz, mint a minimum 1kw-ot evő 2U-s szerver...

-
5leteseN
senior tag
válasz
S_x96x_S
#1792
üzenetére
Gyanítom, hogy a szűk keresztmetszet a két almás-kütyü közötti sávszélesség lesz!
Az mennyi is(elméletileg-papíron)?Jut eszembe: Az egy almás-kütyün belüli sávszélességet/sebességet lehet, hogy írtátok már, de nem emlékszem.
Az elég jó volt egy VGA-hoz képest?
Az alakuló (külföldi)közmegítélés szerint a 3090 kb az etalon.Széljegyzetbe: egyre gyakrabban röppen fel hír a 48GB-os 3090(Ti ?)-ről.
-
5leteseN
senior tag
válasz
S_x96x_S
#1728
üzenetére

S_x96x_S
addikt:
"ouch ... A 96GB RTX 4090 - valószínüleg fake
"384 bit = 24 VRAM Chip w. clamshell = 4GB(32Gb) density per chip. I think it is fake. Afaik, there is no 32Gb density chip one."
https://x.com/harukaze5719/status/1893959550346108975"Ez is jó lenne "holnap":
Reddit
Technical-Titlez
• 1y ago
3090Ti has 24GB using 8 IC's. 3090 has 24GB using 16 IC's. Certainly seems possible to mod a 3090 to 48GB using the same VRAM IC's from a 3090Ti.
-
DarkByte
addikt
válasz
S_x96x_S
#1749
üzenetére
Szerintem meg totál felesleges ennyi topik. Még ezt az egyet se tudjuk megtölteni tartalommal, és az érdeklődés se túl nagy. Ez változhat, de azt látom az emberek többségét az egész alapvetően hidegen hagyja (vagy inkább undorral tölti el), nem hogy még ennyire mélytechnikai módon belemenjen.

A többség majd akkor koppan mikor át lesz verve ezen cuccok által mint sicc.. de még szerintem egy szint után engem is át fognak
 [link]
[link] -
DarkByte
addikt
válasz
S_x96x_S
#1733
üzenetére
Ja, ez nekem sem szerepelt a bingó kártyámon.
Nagy nehezen sikerült végig kattintgatni egy konfigot miután kicsit enyhült a roham, a 128GB-s modell 2TB SSD-vel, Noctua hűtővel nagyjából ~1m HUF + szállítás itthonra.De úgy hogy Q3-tól szállítják, ezt se rohanok előrendelni.
Viszont ilyesmi látszólag légből kapott bejelentésekre számítok még idén.Az szimpatikus hogy kiszórnak 100 darabot ingyen a local AI dev-eknek, hogy elősegítsék a ROCm adopciót.
-
S_x96x_S
addikt
válasz
S_x96x_S
#1726
üzenetére
ouch ... A 96GB RTX 4090 - valószínüleg fake
"384 bit = 24 VRAM Chip w. clamshell = 4GB(32Gb) density per chip. I think it is fake. Afaik, there is no 32Gb density chip one."
https://x.com/harukaze5719/status/1893959550346108975 -

tothd1989
tag
válasz
S_x96x_S
#1713
üzenetére
Mondjuk erre egy hatalmas +1 tudok mondani. De ezzel várok amíg nem tudok venni egy nagyobb nvme-t, a héten vagy 3 alkalommal futottam bele, hogy elfogyott a hely, pedig 500gb a rendszermeghajtó és egyetlen játék sincs ide telepítve. Részemről ott halt le a wsl, hogy a torch telepítés befagyott, nyilván leállítottam a rendszert, aztán gatya lett. Eljátszottam egy pillanatra a gondolattal, hogy átrakom a homelab gépbe a 3070ti-t, de akar a rossebb szenvedni a radeon driverekkel (teljesítményben közel ugyanott van a 6600xt.)
-
-
DarkByte
addikt
válasz
S_x96x_S
#1688
üzenetére
Valójában ennek az összehasonlításnak így nem sok értelme van. Pont olyan mint egy normál PC-t úgy benchmark-olni, hogy megfojtod 4GB RAM-al így az folyton swap-olni lesz kénytelen.
Betonkeverőt is lehet Ferrari mögé kötni, csak minek.Ami ennél vérlázítóbb hogy az a 24GB úgy van reklámozva mintha az olyan hűde sok lenne, főleg AI-nál.
Már rég 48 és 64GB-s kártyáknál kellene járnunk, ha nem lenne mesterségesen visszatartva a konzumer szegmens a pro és szerver kártyák javára ebből a szempontból. -
DarkByte
addikt
-
válasz
S_x96x_S
#1623
üzenetére
Nem teljesen, a Jetson sorozat az elektronikai iparnak szól, gyakorlatilag embedded computing. Pl. a járműipartól kezdve (régebben a Tesla is használt Jetsont, ha minden igaz) a szórakoztatóelektronikáig bármibe tehető, mert vannak egész kicsik is (nekem pl. Jetson Orin Nano-val volt/van munkám). A linkelt változat egy devkit, fejlesztők használják, hogy tudjanak úgy dolgozni, tesztelni, prototípust fejleszteni, hogy ne kelljen forrasztani, vagy a "nyers" Jetson compute modul köré interfészeket és egyéb elektronikákat építeni. Persze nyilván azért van bennük GPU meg unified memory, mert itt is minden az AI-ról szól, de kicsit más a fókusz.
A project Digits is fejlesztőknek szól, de kifejezetten AI modellekhez, asztalra. Külön termékvonal lesz, gyakorlatilag egy új, a Jetsontól független piac az Nvidianak. Mondjuk attól félek kicsit, hogy ettől még a Jetpack OS-üket fogja futtatni ez is, ami nem a kedvencem

-
válasz
S_x96x_S
#1618
üzenetére
itt most olyan projektről van szó, ami videó/filmgyártási igényt fed le, magyarán filmkészítés. nem egész estés hálivúd, hanem bármi, reklám, oktatás, self-promo stb. tehát az ide kapcsolódó AI modellek használata (és nem csak a runway/sora/kling hármasra gondolok, meg 3D modellezés is stb.).
-
consono
nagyúr
válasz
S_x96x_S
#1597
üzenetére
No, mértem gyorsan egyet, kicsi modellel, hogy ne a memória legyen a lényeges (gemma2:2b), meg ez belefér a 4GB-s RTX3050-embe a notin
Ryzen Controllerrel állítottam a CPU TDP-t. A kérdésem a jó öreg "Why is the sky blue?" volt. Ez jött ki:RTX3050 20W TDP
total duration: 7.6621896s
load duration: 31.8506ms
prompt eval count: 15 token(s)
prompt eval duration: 670ms
prompt eval rate: 22.39 tokens/s
eval count: 245 token(s)
eval duration: 6.956s
eval rate: 35.22 tokens/s
RTX3060 45W TDP
total duration: 7.905915s
load duration: 33.1591ms
prompt eval count: 15 token(s)
prompt eval duration: 187ms
prompt eval rate: 80.21 tokens/s
eval count: 270 token(s)
eval duration: 7.684s
eval rate: 35.14 tokens/s
5600H 20W TDP
total duration: 20.0323558s
load duration: 2.1782538s
prompt eval count: 15 token(s)
prompt eval duration: 386ms
prompt eval rate: 38.86 tokens/s
eval count: 284 token(s)
eval duration: 17.465s
eval rate: 16.26 tokens/s
5600H 45W TDP
total duration: 11.6120709s
load duration: 29.8466ms
prompt eval count: 15 token(s)
prompt eval duration: 49ms
prompt eval rate: 306.12 tokens/s
eval count: 220 token(s)
eval duration: 11.532s
eval rate: 19.08 tokens/sJa, a GPU-t a "/set parameter num_gpu 0"-val tiltottam ollama-n belülről, ellenőriztem a task managerben, tényleg nem használta a VRAM-ot. Minden futtatás után kiléptem az ollama-ból, hogy ne legyen keveredés. Ezek alapján nekem az jön le, bár lehet, hogy kellene még máshogy is tesztelni, de igen is számít a CPU teljesítménye, nem csak a RAM, ha CPU-n futtatunk.
-
consono
nagyúr
válasz
S_x96x_S
#1594
üzenetére
Nem a kínai SDK-ban a bizalom a kérdés, hanem a kínai AI modelben
Nálunk betiltották CEO szintről a használatát...A CPU-ra visszatérve én is futtatott kisebb modelleket AMD CPU-n, az a tapasztalatom, mint neked (ugyan úgy ollama, csak Windows alatt). Szerintem ha nincs GPU számít a proci sebessége is, nagyon, de nem mértem semmit. Délelőtt majd kipróbálom valahogy, lehet, hogy a privát notimon, bár ott van GPU is, de tudom változtatni könnyedén mennyit egyen a proci
-
Zizi123
senior tag
válasz
S_x96x_S
#1582
üzenetére
DeepSeek 761B Q8 (720GB) vagy Q4 (404GB) futtatása lenne a feladat.
12 csatornás EPYC-re gondoltam. Minden porcikám tiltakozik ellene, de ez a kiadott feladat.
Mivel pénz nem sok van (mert ha sok lenne, akkor volna GPU-ra is )A kérdés pl arra irányult volna, hogy van-e tapasztalat, hogy a CPU-t mennyire kell kimaxolni.
Csak mert ha a memória sávszélesség lesz a szűk keresztmetszet, akkor teljesen mindegy, hogy 2x 64 magos EPYC van benne, vagy csak 2x 32 esetleg 2x 16.
Ahogy nézem a szóba jöhető CPU-k a AMD EPYC™ 9005 széria lehet a 6000Mhz-es RAM-ok miatt.
2x Epyc 9135
2x Epyc 9355
esetleg iszonyatosan indokolt esetben 2x Epyc 9555.De az is kérdés, hogy egyáltalán a dual CPU előny-e, mert tesztekben panaszkodtak, hogy az LLM modellel való dolgozáskor is meglévő jelenség, hogy a 2 CPU terheltsége nincs szinkronban.
Tehát lehet, hogy jobban járnék 1db 64GB core-os CPU-val, mint 2x32 Core-al?Esetleg erre tapasztalat?
-
5leteseN
senior tag
válasz
S_x96x_S
#1582
üzenetére
Nekem ey>
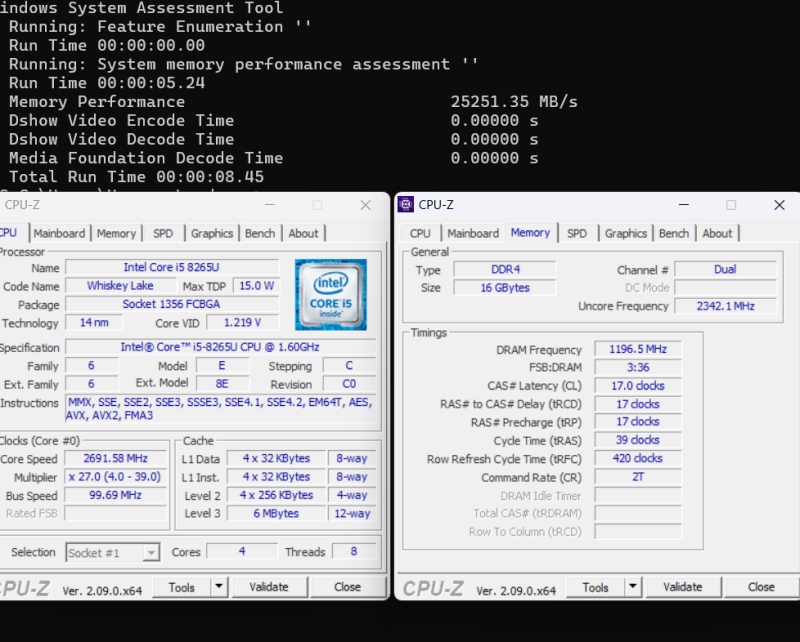
...a laposom(DELL Latitude 3500, DDR4/2400MHz, két-csatornás RAM) ennyit tud a "winsat mem" parancsra: 25.521MBps.
Nálad mennyi RAM, hány csatornán megy, hogy megvan a kb 4 token/s?Lehet, hogy lemérem én is W11-alatt(a tied Linux-os).
Milyen llama és melyik LLM?
...csak hogy ugyanazok legyenek, a jó összehasonlítás alapjaként!
Érdekel, hogy vajon mennyi lesz a különbség és kinek a javára:
L : W ? -
#1511
Komplikato
veterán
S_x96x_S
#1510
Komplikato
veterán
válasz
S_x96x_S
#1510
üzenetére
És egymásra pakolva ezeket összeadódik a teljesítmény, így pl. 2db már elbír egy 405B LLM-el is. A bemutatóban nem igazán hangzott el, hogy hányat lehet így összekapcsolni. Mondjuk engem megleptek, hogy a Mediatek/NVidia kooperációs chip nem a lepkefing Snapdragon X konkurenciája lett, hanem egy kis fogyasztású Petaflops teljesítményű AI szerver.

-
Zizi123
senior tag
válasz
S_x96x_S
#1420
üzenetére
Az RTX 4060 TI low cost gamer kártya, ami nem speciálisan AI-ra lett fejlesztve., mint az M4 Pro. (vagy mint amennyire az M4 PRo-nál rá voltak gyúrva)
Viszont sebességben elveri az M4 Pro-t, mert minden +16GB RAM-ért kapsz 1 újabb RTX 4060 16GB-ot."MacBook Pro -n ( kimaxolva 128GB-ra )"
Az már 2,2m fölött van az már igencsak az a kategória, amikor ha valakinek van 2.2m AI-ra gépe, akkor akad ott 3m is, és akkor mér lehet tényleg olyat venni ami tényleg gyors.
(Bár csak 48GB RAM lesz a GPU-n.)Mondjuk az más kérdés, hogy mit kezd a 100MB-os modelllel a MacBook Pro, mert bár 128GB-val meg tudja nyitni, de a sebessége az a 11 token elég lightosnak tűnik.
-
Zizi123
senior tag
válasz
S_x96x_S
#1411
üzenetére
Akkor ezek szerint a channels és a controllers ugyanaz?
Csak mert a dual, quad, eight channels rendszerekbe ugye annyi darab memóriát kell rakni ahhoz, hogy kihasználja a rendszer sebességét.
Az Apple-né viszont 1-2db memória modul van max, és az tud 16, 24, 32 channelt???"kétcsatornás DDR5 memória ;
2x64 = 128 bit ; vagyis annyi tudhat mint az alap M4
és kevesebbet mint az "M4 Pro"
Ez azért fura, mert ahogy írtam is jelen pillanatban a létező leggyorsabb DDR5 memória modulok tudnak 40GB/s-et. azért nagyon elmarad a 120GB/s-től.Sajnos az Apple memória sebességről semmit nem lehet találni, hogy milyen gyors, mekkora a tényleges átviteli sebessége.
Visszatérve az AI-ra:
A Geegbench AI alapján:Single Precision (FP32) score:
M4 Pro 5.770
RTX 4090: 42.338Half Precision (FP16) score:
M4 Pro: 38.425 (RTX 4070 szint)
RTX 4090: 56.949Quantized (INT8) Score:
M4 Pro: 51.440
RTX 4090 31.147Tehát nagyon jó az Apple proci, főleg, hogy tartalmazza a GPU-t is, de 1 ugyanolyan árú PC-vel csak bizonyos AI feladatok esetén tudja felvenni a harcot.
-
Zizi123
senior tag
válasz
S_x96x_S
#1409
üzenetére
Értem, csak senki nem beszélt eddig notebookról.
Emlékeim szerint MacMini-ről, mini PC-ről volt szó utána én hoztam fel a PC-t, mint alternatív megoldást a MacMini helyett.Viszont még mindig nem értem, hogy a memória sebessége a controllerek számától függ?
Tehát a memória végtelen sebességű, csak attól függ a gyakorlati sebessége, hogy mennyi controller van a gépben?
Én eddig azt hittem, hogy maga a memória modulnak , a rajta levő chipnek van 1 sebessége. De akkor ezek szerint nem.
Pl az Intel i5-14500 CPU-ban mennyi memória controller van? -
Zizi123
senior tag
válasz
S_x96x_S
#1392
üzenetére
Bocs tényleg benéztem, hogy 16GB RAM van benne, így 100et-al olcsóbb, mint írtam.
Viszont amit írtál csak részben igaz."A gyors egyesített memória sebessége eléggé fontos, és egy M4 PRO-s 273GB/s of memory bandwidth -et lehetetlen összehozni 2 csatornás DDR5-ből."
Ez így igaz, ahogy az Apple sem tudja összehozni szerintem. Ez max 1 elvi sebesség lehet, mert maga a DDR5 memória nem tud annyit amit használ az Apple is. A csúcs DDR5 memóriák tudnak 40GB/s körül olvasni az LPDDR5 viszont nyilván nincs a közelébe ennek. Ha DDR5-ből csinál GPU memóriát, akkor annak kellene lennie a gyenge láncszemnek.
Vagy valamit nagyon félreértek.Nem túl sportszerű mobil GPU-val hasonlítgatni a MacMini-t
Ha a 4070 Ti-vel, vagy Ti Super-al hasonlítjuk összes akkor már nagyon csúnyán alúlmarad a MacMini a az RTX 4070 GPU-k 672.3 GB/s memória sávszélességhez képest.
Vagy az RTX 4080 Super 736MB/s-jéhez képest.Igen ezek csak 16GB-os kártyák azt nem tudom, hogy tudnak-e az AI alkalmazások több kártyát használni egyszerre, pl a (ComfyUI biztos nem, mert azzal szórakoztam én is, de azt írják, hogy csak 1 kártyát tud kezelni egyszerre)
Tehát azért 1 próbát megérne, hogy az említett 48GB-os modell-t ha betöltöd az milyen sebességgel dolgozik, a LPDDR5 memória visszafogja-e vagy sem ...
De persze ez józan paraszti logika, símán lehet, hogy nem így működik a dolog.
Írdd már meg légy szíves ha nem stimmel a gondolkodásom. -
S_x96x_S
addikt
válasz
S_x96x_S
#1399
üzenetére
És egy 28GB -os modell ; csak 1.55 token/sec
cpu mód:
"""
# ollama run gemma2:27b-instruct-q8_0 --verbose
>>> hello
Hello! 👋
How can I help you today? 😊
total duration: 26.185456189s
load duration: 72.464752ms
prompt eval count: 10 token(s)
prompt eval duration: 17.71s
prompt eval rate: 0.56 tokens/s
eval count: 13 token(s)
eval duration: 8.372s
eval rate: 1.55 tokens/s
"""
( Minisforum UM790 Pro - Ryzen 9 7940HS - 32 GB DDR5 RAM )Persze kinek mire kell;
de a nagy modellek sebessége egyre csak csökken és nem árt a memória sávszélesség.
emiatt a CPU módot hamar ki lehet nőni ... -

Lokarson
tag
válasz
S_x96x_S
#1391
üzenetére
Én most Intel 1135g7(Iris XE) notit használok 24GB Ram-mal. IPEX-LLM-mel már GPU támogatásom is volt (taskbar-ban is láttam a GPU terhelést: 90%), de nem volt gyors.
A Mac-től egy kicsit tartok (nem ismert Op.rendszer, programok, perifériák, nem bővíthető stb.), ezért gondoltam a 125H/155H vonalra.
A 780M-re még nincs rendes GPU támogatás? (Ezt is néztem egyébként.)
Olvasva a többiek hozzászólását is, talán egy használt 3060 12GB-os gép lenne a legköltséghatékonyabb megoldás számomra, vagy heti néhány órára runpod. -

ptesza
senior tag
válasz
S_x96x_S
#1349
üzenetére
Nekem nagyon úgy tűnik, hogy nem az AI-t használják. Hanem a régi jólbevált végeselem módszert amit az ANSYS fog adni. Egy helyen meg is villantották. Egy ilyen hidraulikus szimuláció a háló sűrűségétől függően akár több napig is eltarthat egy 2000-3000 magos klaszteren is. Ez drága játékszer a nagyfiúknak. Eddig sem az volt a baj, hogy a mérnök nem értette azt amit csinált és kellett volna hozzá egy AI, hanem ilyen eszközökhöz inkább csak a nagy multi cégek tudnak hozzáférni és megfizetni.
-

repvez
addikt
válasz
S_x96x_S
#1338
üzenetére
majd ha melo mellett több időm lesz megg látom, hogy esetleg tudok valamit kezdeni a dologbol, akor ugy is jobban rá álnék a témára, de addig mig semmit nem tudok addig nem akarok pénzt belefeccolni, föleg ha tényleg nem ugy halad ahogy szeretném.
Ezért lett volna jo ha van egy olyan ismerős aki hasonlo érdeklödésu mint én és tud programozni, mert akkor folyamatába tdtuk volna egymást segiteni és az ötletelésel ö meg a kodolással és akkor elöbb utobb már mindenki beleszokott volna és átlátta volna a kodot, hogy mit miért hogyan . -
#1337
Komplikato
veterán
S_x96x_S
#1335
Komplikato
veterán
válasz
S_x96x_S
#1335
üzenetére
OFF: Nekem nagyon vicces, hogy ma a Phyton mennyire megkerülhetetlen. Mikor anno Amigára (!) kijött ez a nyelv, az alapjait tartalmazó könyvet alig bírták elsózni. Annyit tudtak felhozni mellette, hogy könnyebb és észszerűbb, mint a C.
Érdekelne hogyan vészelte át azt az 1-2 évtizedet, amíg annyira el volt ásva, hogy nem is hallottam felőle. -
repvez
addikt
válasz
S_x96x_S
#1335
üzenetére
ezeket a kröket már megfutottam évekkel ezelött, nincs senki ismerős aki kodolni tud, a codolos topicokbol meg elhajtanak azzal, hogy az ugy nem megy ahogy én gondolom, mert elöbb tanuljak meg basicet meg más egyszerü nyelvet majd utána ha az megy akkor tanuljak meg olyan nyelvet amivel már mindent lehet aztán azon is gyakoroljak kis programokat és majd utána nekiállhatok .
Mert azt ugy nem lehet, hogy egy nagy projectnek nekiálok és elöszor felépitem a vázát , és majd kicsinnyenként épitem fel hozzá a részleteket.
YT-on és könyvekbol meg egyedül nem leht , ugy hogy közben nincs senki aki megválaszolná azokat a részeket ami nem tiszta és ott se tudom átultetni olyan programba ami nekem tetszik, olyant meg nem szeretnék, hogy csak azért csinálok egy telefonkönyvet, vagy számologépet , amit utána nem használok, de az idő meg eltelik vele és nem haladok azzal ami érdekelne.Ezért is örülök, hogy már van ilyen AI leetőség,mert bár nem értem a kodot,, de legalább már most olyan dolgokat sikerült vele megcsinálnomm, amit szerettem volna , igaz, hogoy bajlodni kell vele, hogy megértse mit akarok, vagy hogy müködjön egyáltalán, de legallább valamerre visz.
-
repvez
addikt
válasz
S_x96x_S
#1333
üzenetére
mivel nem tudok egyáltalán kodolni és a legtöbb ilyenhez azért kéne érteni minimálisan valamit , ezért mégha le is van irva nem teljesen tiszta, hogy mikor mit és hogyan kéne használnom, a github meg amugy is nekem egy elég átláthatatlan valami
Csak annyira szoktam használni, hogy a zip filet le tudom tölteni .
DE inkább maradnék valami jobban átlátható leirásnál vagy egy OCI install nál vagy egy next next ok, stilusnál.
Ezért is kérdeztem, mert a YT-on látom hogy használják páran, de a pontos részleteit nem mutatják meg, hogy akkor most mégis mit honnan kell letötlteni beállitani.
Meg általában nálam sose szokott mukodni elsöre az ami ott igy a hibákat se tudom, hogy lehet kijavitani vagy mit kell olyankor tenni.









![;]](http://cdn.rios.hu/dl/s/v1.gif)


 Sőt néha kérek egy pontosítást a saját szövegemen, majd 2-3 (stb) kérdezz felek után visszajutunk 99%-ban az én szövegemhez.
Sőt néha kérek egy pontosítást a saját szövegemen, majd 2-3 (stb) kérdezz felek után visszajutunk 99%-ban az én szövegemhez. 







 ez volt az az adat, amire említettem is, hogy nem 100%, hogy jól emlékszem.
ez volt az az adat, amire említettem is, hogy nem 100%, hogy jól emlékszem. ) HUF-ot/€-t/$-t...
) HUF-ot/€-t/$-t...

 Ez kb a jelenlegi 2080Ti-m sebessége(616GBps), alatti bőven, egyetlen (de nagy)előnye az almás konfignak(a meglévő brutálka hype-presztízs mellett), hogy a 2080Ti-nek csak 22(-44GB
Ez kb a jelenlegi 2080Ti-m sebessége(616GBps), alatti bőven, egyetlen (de nagy)előnye az almás konfignak(a meglévő brutálka hype-presztízs mellett), hogy a 2080Ti-nek csak 22(-44GB 





 +
+ 















Új hozzászólás Aktív témák
- Xbox Series X|S
- iPhone topik
- Elder Scrolls IV - Oblivion - Olvasd el az összefoglalót, mielőtt írsz!
- E-roller topik
- Üvegben nem szűköldködő GameMax mikrotorony, "lopakodó" alaplapokhoz is
- PlayStation 5
- Milyen TV-t vegyek?
- Hobby elektronika
- Kormányok / autós szimulátorok topikja
- Eredeti játékok OFF topik
- További aktív témák...

- LG UltraGear 27GS85Q-B Gamer IPS Monitor! 2560x1440 / 200Hz / 1ms / FreeSync
- Thinkpad T14 Gen4 14" FHD+ IPS i7-1355U 16GB DDR5 512GB NVMe ujjlolv IR kam gar
- Spirit of Gamer ELITE K70 Gaming Billentyűzet
- LG UltraGear 27GP850-B GAMING IPS Monitor! 2560x1440 / 165Hz / 1ms / FreeSync / G-Sync
- FÓLIÁS! LG UltraWide 34WP75CP-B VA Monitor! 3440x1440 / 160Hz / 1ms / FreeSync
- ÚJ Asus TUF Gaming FX707 - 17.3"FHD IPS 144Hz - i7-13620H - 16GB - 1TB - RTX 4060 8GB- 2 év garancia
- Xiaomi Redmi Note 10 Pro 128GB Kártyafüggetlen, 1Év Garanciával
- Fotó állvány eladó
- ÁRGARANCIA!Épített KomPhone Ryzen 5 4500 16/32/64GB RAM RX 6500 XT 4GB GAMER PC termékbeszámítással
- LG 27GN800P - 27" IPS - 2560x1440 - 144 hz 1ms - NVIDIA G-Sync - AMD FreeSync - HDR 10
Állásajánlatok

Cég: PCMENTOR SZERVIZ KFT.
Város: Budapest

Cég: Laptopszaki Kft.
Város: Budapest