Új hozzászólás Aktív témák
-

NightGT
senior tag
Akkor tulajdonképpen mi volt a teljesítménybeli elmaradás oka?
Tizedannyi ismeretem sincs a hardver felépítéséről, mint neked, vagy néhány korábbi hozzászólónak. De szívesen olvasnám a véleményedet. Amit nem értek, abban segít a google, meg a korábbi cikkek.
Egyelőre nekem mindebből annyi van meg, hogy az FPU az a Quake, és a Cyrix bukása óta elemi része a processzormagnak. Az FX-ekben meg pont azokon kellett osztozni...
DraXoN kicsivel feljebb már írt néhány pontban az okokról...
[ Szerkesztve ]
Speed is the only truly modern sensation
-

Raymond
félisten
-

frescho
addikt
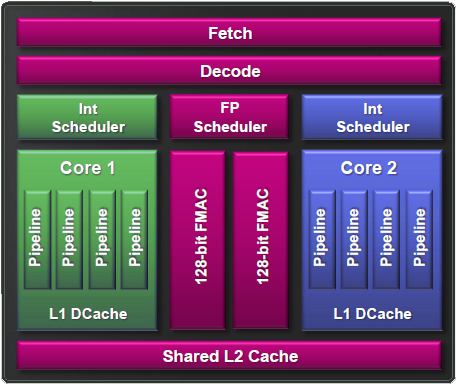
"A fenti képen zöld és kék színnel van jelölve az egy-egy mag dedikált része, lilával pedig a mindkét mag számára hozzáférhető egységek. Az utasítások végrehajtása a következő utasítások kiválasztásával, azok előfeldolgozásával és dekódolásával kezdődik, ezeket az összefoglaló néven front-endnek hívott megosztott részegységek végzik, órajelenként váltva a két szál között.
Az gyártó (AMD) figyelme leginkább egy úgynevezett Cluster-based multi-threading (klaszter-alapú többszálúsítás) felé irányult, mely a korai prognózisok alapján még plusz 50% szilícium felhasználása mellett 80% teljesítmény növekedést ígért."
---
"A Bulldozer front-endje nem volt alulméretezve. Konkrétan ezt kapta meg a Zen is. Még amikor az AMD a Zen briefingeket tartotta, akkor elmondták, hogy alig módosítottak rajta, mert ez volt a legjobb eleme a Bulldozernek, ami messze túl volt méretezve, így megfelelt a Zen magnak is."
Az, hogy a frontend megfelelt 1 Zen maghoz nem jelenti azt, hogy két Bulldozer maghoz nem volt alulméretezve. Ha jól emlékszem, akkor ezt azóta folyamatosan tovább fejlesztik, a Zen 2 esetében az IPC növelés fontos eleme volt. Analógia: Egy kis autó elég lehet egy 4 fős családnak, de 4 gyerekkel már nem férnek el benne.
"A modul lényege az egyszálú teljesítmény maximalizálása volt, mert ha egy szálon futott a számítás, akkor lényegében az a szál egymaga megkapta a túlméretezett, két szálra tervezett részeket."
A válaszodnak ez a részét gondold át. Egyértelműen elbukott a fejlesztő részleg, ha ez volt a cél, ugyanis 1 szálon a Phenom is simán iskolázta. Sokkal jobban megállja a helyét amit utánna írtál:
"A koncepció az volt benne, hogy ilyen formában sokkal kisebb mértékben kell növelni a lapkaterületet, a nagyobb százalékos előrelépéshez. A CMT +60-80%-ot jelenthetett, miközben lapkaterületben nagyjából +40-50%-ot fizettek. Plusz 100%-ért plusz 100%-ot kellett volna fizetni a lapkaterület szintjén."
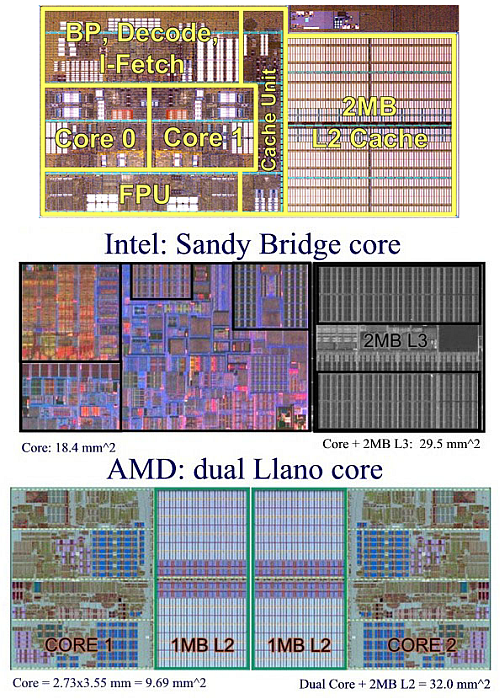
Teljesen egyetértek, ha a CPU maximális sok szálú teljesítményét nézzük. De nem egy szál teljesítménye lett így nagyobb, hanem az adott sziliciumra vetített maximálisan elérhető. A kettő között negy különbség van ami miatt sikertelen lett a Bulldozer széria. Többek között ezért idéztem be a cikkeidből az első két képet. Jól látszik, hogy mi közös és az is, hogy a lapka méretében ez mit jelentett.
"Az AMD-nek van is egy compute core whitepaperje. Abban ezt értik mag alatt: egy mag olyan HSA-t támogató, tetszőlegesen programozható hardveres blokk, amely képes legalább egy folyamatot futtatni saját kontextusán, illetve virtuális memóriaterületén belül, függetlenül a többi magtól."
A második ok amiért a képeket beszúrtam a második mondatod. Egy maghoz eszerint kell fetc, decode, FP scheduler és L2 cache is. Ha kiveszem az egyik maggal ezeket, akkor a másik már nem felel meg az állításnak. A 1.5 magnak megfelelő szilicium azt is jelenti, hogy csak 1.5 mag került oda. 1 modul, de nem teljes értékű két mag. Analógiával egy társbérlet nem felel meg egy teljesen saját lakásnak.
Én úgy látom, hogy az AMD helyes döntést hozott. Ha biztosan nyertek volna, akkor az ügyvédi kültséget nem nekik kellett volna állni. Mérlegeltek és úgy látták, hogy a nyerési esélyük alatta van annak amit megér a megegyezés. Műszakilag is jó váltás a Ryzen vonal.
https://frescho.hu
-
frescho
addikt
Erre adj légyszi valami AMD-s forrást:
"Pedig az egyszálú teljesítmény maximalizálása volt a cél, hiszen a modul egy erősebb összeállítás volt, és a részben osztozkodó erőforrásokat teljesen megkapta az egy szál, ha mellette nem futott semmi."
Kíváncsi lennék ki merte ezt leírni. Nem csak, hogy IPC-ben léptek hatalmasat vissza, de még az előd Phenom II alap órajelen is simán elverte kevés szálat kihasználó programok esetén.
"Az AMD sem tudja, hogy miért terjedt el az a legenda, hogy a front-end kevés volt, de nem volt az, a sokkal erősebb Zen magba is át tudták menteni, és semmi gondja nincs a kiszolgálásával."
Akkor mi volt az oka, hogy sima integer felhasználásnál sem duplázódott a teljesítmény ha egy modulban 1 vagy 2 "core" volt aktiválva? Meg tudod mondani, hogy sima fordításnál mondjuk mi lehetett a szűk keresztmetszet, ha az FPU és a fronted nem?
https://frescho.hu
-
#92
 Dr. Romano
veterán
Abu85
#91
Dr. Romano
veterán
Abu85
#91
Dr. Romano
veterán
A felhasználókat ez mind nem érdekli mert nekik csak a teljesítmény számít. Nyilván olyan processzort kell készíteni ami a konkurenciához mérten erős 1/multi szálas tempóban nem pedig tranzisztorszámhoz képest fest jól.
Ha ez nem sikerül, akkor jöhetnek az ilyen magyarázatok, hogy "rosszul fogod", "ne így nézd dolgot" stb.Az eredménye meg is lett ennek a vakvágánynak: intel dominancia; 4/8-as procik évekig.
[ Szerkesztve ]
Ez....e...ee...ez egy.... ez egy FOTEL???
-

Kansas
addikt
Bírom ezeket az IT-s "szabályokat", mint "Pollack-szabály" meg "Moore törvénye", csak épp ezek nem fizikai szabályok meg törvények, hanem megfigyelések a múltra nézvést, amik a jövőre nézve csak akkor hordoznak relevanciát, ha a fejlesztési irány nem változik. Elég egy architektúra határainak az elérése, vagy egy nagyobb design-/irányváltás, és mennek ki az ablakon...
Nincs olyan MI, ami képes lenne szimulálni az emberi hülyeséget... ha valaha lesz, annak tuti az emberi hülyeség lesz az oka... A Föld erőforrásai közül a legjobban az ész van elosztva - mindenki meg van róla győződve, hogy több jutott neki, mint másoknak.
-
#98
Dr. Romano
veterán
Abu85
#94
Dr. Romano
veterán
Ezek szerint az AMD az FX procik eladásánál rossz célcsoportott válaszott. A processzort saját mérnökeinek kellett volna csak értékesítse akik a CPU lassúságát elfogadják mert értik hogy ez lehetett volna méglassabb.
A mezei usert ez úgysem érdekelte, nekik csak tempó kellett a melóval megtermelt pénzéért (és nem megmagyarázás) ami még a modulos felépítéssel sem volt meg nemhogy anélkül (ahogy írtad is)! Ez itt a probléma, ezért mentek inkább a konkurenciához és lett az amit írtam.
Ez....e...ee...ez egy.... ez egy FOTEL???
-
Kansas
addikt
Ez nem csak a felhasználók tudása miatt volt így, hanem főleg az AMD marketingje miatt. Ahelyett, hogy úgy reklámozták volna a procikat, hogy 4-modulos, inkább a 8 magra fókuszáltak. Joguk volt hozzá, lévén a mag definíciója nincs kőbe(szabványba) vésve, de így ahelyett, hogy az i5-ökkel versenyeztek volna, amikkel pariban voltak, az i7-ekkel álltak szemben, és többnyire alulmaradtak.
Még azt se lehet mondani, hogy anyagilag megérte nekik, hisz gyakorlatilag i5-szintre voltak kénytelenek lecsökkenteni az áraikat..."Csak ugye nem tudod megmagyarázni nekik, mert nincsenek meg az ismereteik hozzá, hogy megértsék." - és ezért voltak kénytelenek alkut kötni a bíróságon...
Nincs olyan MI, ami képes lenne szimulálni az emberi hülyeséget... ha valaha lesz, annak tuti az emberi hülyeség lesz az oka... A Föld erőforrásai közül a legjobban az ész van elosztva - mindenki meg van róla győződve, hogy több jutott neki, mint másoknak.
-
Kansas
addikt
Erősen kétlem.
Ha az lenne, ilyen cikkek sem születnének, mint a "Generalization of Pollack Rule and Alternative Power Equation", amiből egyértelmű, hogy több verzió létezik, és mindegyik korlátolt hasznosságú.Vagy olvasd el ezt a hozzászólást egy vonatkozó diskurzusban.
Egyrészt:
"Also keep in mind pitfalls defining complexity for purpose of comparison between different devices." - tehát már a design-ok összehasonlítási alapja is sántít...
Másrészt:
"In any case, even for the more unfavorable case of the 4790k, the difference between the core area and the value predicted by the rule was of 30% or something as that." - ha 30% eltérés van a predikcióhoz képest, az nem fizikai törvény, hanem, ahogy írják is, egy "rule of thumb" - mint kb. az összes többi ilyen megfigyelt szabályszerűség az IT-ban.De hagyjuk, ez nagyon off...
[ Szerkesztve ]
Nincs olyan MI, ami képes lenne szimulálni az emberi hülyeséget... ha valaha lesz, annak tuti az emberi hülyeség lesz az oka... A Föld erőforrásai közül a legjobban az ész van elosztva - mindenki meg van róla győződve, hogy több jutott neki, mint másoknak.
-
#105
 BerserkGuts
őstag
Abu85
#94
BerserkGuts
őstag
Abu85
#94
BerserkGuts
őstag
Hát annyit értek hogy egy E8400 jobb egyszálas teljesítményt nyújtott és az 2008-as termék
Amíg a buldózer 2011-es,
8350 2012 kb

[ Szerkesztve ]
12600KF/ROG Strix 4070ti/ROG Strix B660/Noctua NH-D15S/ROG Strix AuraEdition 850W/SamsungOdysseyG7 32" 1440p/ThermaltakeTower900/RazerViper8K/F4-3200C14D-16GFX(FlareX)/Kingston A2000
-
Kansas
addikt
Az elejére válaszul: én sem állítottam mást, csak annyit, hogy ha nem magok számával hanem modulok számával reklámoznak, nincs olyan rossz szájíze az embereknek és talán ez a per se lett volna(tudom, akkor az lett volna, hogy ahol a Bulldozer erősebb, ott "nem fair az összehasonlítás, 2x annyi mag van"
 )
)"Az IT-szabályok 99%-a megfigyelésre alapoz, viszont valós fizikai ok is van a többségük mögött." - lehet, viszont amíg a fizikai törvények nem függenek a fejlesztések irányától, az IT "törvények" csak annak változatlansága mellett maradnak igazak. Mihelyt a szekvencialitásról a masszív többszálúságra, vagy X86/64-ről RISC-V-re, már csak igen korlátozott predikciós képességük marad.
Természetesen a visszafelé kompatibilitást nem lehet elvágni egyik napról a másikra, akármennyi teljesítményt is lehetne nyerni, hisz azok akik még a proci-gyártóknál is többet invesztáltak az x86/64-be 3rd party programok, komplett folyamatrendszerek, adatközpontok, stb. képében, nem fogják hagyni, illetve nem fogják venni az újat helyette, hanem megvárják az átállással, míg kirohad alóluk a régi(és a processzor lassan rohad...).
Nincs olyan MI, ami képes lenne szimulálni az emberi hülyeséget... ha valaha lesz, annak tuti az emberi hülyeség lesz az oka... A Föld erőforrásai közül a legjobban az ész van elosztva - mindenki meg van róla győződve, hogy több jutott neki, mint másoknak.
-

Frawly
veterán
Abban egyetértek, hogy az ARM meg a tisztán RISC architektúrák a jövő. Az x86-ban túl sok a legacy korlát, amit dobni kéne már az i686-tal együtt. Ez a visszafelé kompatibiltási mánia is felesleges, a mostani modern gépek már eleve nem kompatiblisek a régi OS-ekkel, nincs floppy, nincs soros/párhuzamos port, IDE még emuláva van egy ideig a Legacy BIOS-szal együtt, de ez meg fog szűnni, ha jönnek az UEFI only gépek, NVMe-vel sem tudnak mit kezdeni meg a sok terabájtos lemezekkel, új hardverekhez sincs driver. Így visszafelé kompatibilitás van elméleti szinten (még egy DOS is ugyanúgy fut a mai procikon, ahogy anno egy XT-n vagy 286-oson), de gyakorlatilag nem használható semmi értelmesre.
Akinek meg kellenek legacy appok, játékok, futtatja emulációval, még emulációs overheaddel is simán bírják futtatni ezeket a modern gépek.
-
frescho
addikt
"A Zen bemutatóján volt két mérnök. Az egyik mondta, hogy a Bulldozert anno úgy tervezték, hogy egy modulon belül maximalizálják az egyszálú teljesítményt. Ezért gyorsult a második száltól csak 60-80%-ot a rendszer két magra vetítve, mert az első szál már eleve megnövelt erőforrásokat kapott, így gyorsabban tudott dolgozni, mintha két kisebb magot alakítottak volna ki. Két kisebb maggal ugyanott lettek volna két szállal, de egy szállal lassabb lett volna a rendszer."
Tervezték, de végül nem lett igaz. Mérnökként nem lett volna képem kiállni és ezt elmondani. Nem értetted félre amit mondtak? Írásos/videó anyag van róla? Amiért még mindig kételkedek:
- Az elérhető anyagokban a tervezési alapelv a szilicium méret (transistor budget) / teljesítmény javításról szólt. Ilyen szempontból nagyon sok szálas programokban jól sikerült a Bulldozer. Az utolsó mondatod is ezt erősíti és azzal egyet tudok érteni.
A második mondatodra megint visszakérdeznék:
- Mik voltak a közös részek?
- Ha azok nem voltak alulméretezve, akkor miért nem tudtak kiszolgállni egy komplett modult? (Itt arra gondolok, hogy lehet, hogy egy maghoz képest 160%-ra volt méretezve, de két maghoz bizony 200% kellett volna.)A P4-es résszel nem értek egyet, mert ott a felépítés sokkal kevésbé volt egzotikus és a két problémából csak egy volt közös a Bulldozerrel. P4-nél a legegyszerűbb programok is gyorsultak. A közös probléma a gyártástechnológia volt. Nem véletlen, hogy ma is 4GHz körül mozog a procik értelmes órajel limite, az 5GHz bár elérhető de brutális TDP-vel. A P4-nél az Intel, a Buldozernél a GF nem tudta ezt átugrani. Egyszerűen érthetetlen, hogy az AMD mérnökei miért futottak neki ugyanannak a falnak amibe az Intelnek már beletört a bicskája.
A AMD másik hibájának bemutatásához tőled idézek.
"A limit a szoftver."
"A felhasználók tudása rendkívül korlátozott a mérnökökéhez képest. Nem értik, hogy mit miért csinálnak, rosszabb esetben félreértik. Lásd a Bulldozer esetében. Az volt a hit, hogy a modulos felépítés miatt volt lassú az egyszálú teljesítmény. Pont emiatt volt nagyobb, mint amilyen lett volna a modulos felépítés nélkül. Csak ugye nem tudod megmagyarázni nekik, mert nincsenek meg az ismereteik hozzá, hogy megértsék."
Aminél tévúton jársz és az AMD is belement ebbe a zsákutcába az a piac megreformálásának a hite. 10% alatti részesedéssel prófétának lenni nem működött. A szoftver adott volt és mindenki nagyon jól tudja, hogy évek kellenek egy új technológia bevezetésétől annak széles körű kihasználásáig. Ebbe a környezetbe az alapcsony IPC és órajel páros kihozatala hiba volt. Nem kicsit "mindenki szembejön a pályán" érzés lehetett a mérnököknek.
A felhasználókat az teljesítmény, illetve az ár/teljesítmény érdekli. Mérnökként lefuttattam rajta 10-20 tesztet és gyengének bizonyult. Még ott is, ahol elvileg sok szál volt maximum egyenlőt tudott hozni magasabb fogyasztással, azonos áron. Nem érdekelt senkit, hogy 10 vag 20 mm2-ert sziliciumot megspóroltak. A reakció az volt nem 1-2 embertől, hogyha az új architectúra lassabb IPC-ben és szinte abszolút értékben is, akkor miért nem a Phenomot kalapálták ki jobban.
"A célcsoportot nem választják. Viszi, akinek kell."
"célcsoport (Target Group): azon - marketing célok alapján meghatározott - emberek csoportja, akiket a kampány illetve egyéb kommunikációs tevékenység során elérni szeretnénk."
Márpedig azt a marketing/sales választja. Ha az AMD nem tudta kinek akarja eladni, akkor ott még nagyobb volt a gond. De ezt nem hiszem, nem merem elhinni.
Frawly: Az nem ekézés, ha kimondjuk, hogy a tervezésnél rossz irányt vettek. Intelnek is volt ilyen és most éppen az AMD-nek van jövőbemutatóbb, skálázhatóbb procija. Nekem az nem tetszik amikor nem mondjuk ki, hogy valami bizony el lett kefélve.
Az ARM már évek óta "jön" de valamiért nem akar ideérni. Két gondot látok. Az egyik, hogy amikor felskálázzák máris sokat veszít az energiahatékonyságából. Egy mai CPU-nál a fogyasztás nagy részét már nem is a klasszikus "mag" , hanem az azt kiszolgáló részek kérik. Az AMD ezt vágta szét most ügyesen, csak ehhez kellett a megfelelő interposer, a magok közötti összeköttetést biztosító busz és még kismillió más dolog. A másik gond az, hogy egy google-nél is nagyon sok pénznek számít egy meglévő komplett OS-nek akár más processzoros verzióját bevezetni. Csak pár dolog ami hirtelen eszembe jut:, hogy kell belőle szeparált: hardver tervezés, beszerzés, szoftver build, deploy, test/staging, repository...
[ Szerkesztve ]
https://frescho.hu
-
Tudom, ismerem a ROCm stack-et, legalábbis azt a részét, ami linuxon is megy.
A "nem jött be" alatt azt értem, hogy a heterogén compute nem tette szükségtelenné a gyors procikat.Yutani: Én nem róvom fel. Legalább próbáltak valamit alkotni.
[ Szerkesztve ]
Eladó régi hardverek: https://hardverapro.hu/apro/sok_regi_kutyu/friss.html
-

paprobert
senior tag
"A modul lényege az egyszálú teljesítmény maximalizálása volt, mert ha egy szálon futott a számítás, akkor lényegében az a szál egymaga megkapta a túlméretezett, két szálra tervezett részeket."
vs.
2012-es magyarázatod
"A Bulldozer fő szempontja a throughput teljesítmény kitolása volt, amihez elővették Pollack szabályát. Ha egy szálon várod a teljesítményt, akkor nem az volt a cél, hogy ott jó legyen. Ha a throughput tempót várod, akkor az növekedett."Itt valami nem kóser.

[ Szerkesztve ]
640 KB mindenre elég. - Steve Jobs
-
paprobert
senior tag
De akkor mégis hova a csudába bújt el a jó egyszálas teljesítmény? Toporgás, IPC-visszalépés történt.
Ha technikailag helytálló lenne az, amit írtál, akkor erre az egyetlen logikus magyarázat az lenne, hogy kisebbek lettek a magok, mint aminek kellett volna lenniük. Gyakorlatilag túltolták a throughput-optimalizáltságot, és ennek az egyszálas teljesítmény látta kárát.
De ha megnézzük az elköltött tranzisztormennyiséget és a méretet az adott gyártástechnológián, akkor a Zambezi pazarlóbb mint a Thuban, nyoma sincs annak, hogy akár tranisztorszámban, akár méretben visszavágták volna az FX magokat.
[ Szerkesztve ]
640 KB mindenre elég. - Steve Jobs
-

apatyas
Korrektor
És mégse ott murdelt meg mindkettő, hanem az elérhető órajeleken illetve a bezabált fogyasztáson - gyártástechnológiai kérdések. Noha az igaz, hogy a Bull egy szálon kevesebb volt, de órajellel behozta volna. Vulkánnal meg dx12-vel kellett volna kicsit jobban iparkodni, és egyből nincs annyi nyávogás. Aki meg dolgozik rajta, annak jó. Kivéve a szintén őskövület, egyszálas, vagy tényleg nem többszálúsítható folyamatokat. Azokat attól tartok, a heterogén éra se menti meg.
Szőni tessék vele, az többszálú[ Szerkesztve ]
pezo77 #5 2017.12.14. 13:29 Hmm. És ez az e-hajó akkor hol is tud kikötni? Az e-bay -ben? ;)
-
paprobert
senior tag
Az Intel által megszellőztetett tervek a CPU fronton valóban a CPU feldolgozókkal való kitömését célozza, illetve megfejelik az egészet a GPU-val a párhuzamosított ökoszisztémával. Teljesen kukába dobják az egyensúlyt? Koránt sem.
Látni kell, hőgy ők is evolúcióban gondolkodnak, simán a P6 DNS-re építkezve.
De odaállni a fejlesztők elé, hogy "Szevasztok, holnaptól lesztek szívesek megoldani a feladatot az eddigi 1 helyett 0.5-0.7 teljesítménnyel". Na ez így nem megy. (Bulldozer)
Egy ma jól működő dizájnt is lehetséges optimalizálni throughputra. A szoftverfejlesztők szeretni is fogják, mert ha ki tudod használni, nyersz, de ha nem tudod sem baj, mert az extra teljesítmény továbbra is ott van a régi jól bevált keretek között.
Én az AMD-től is ezt várom, a CCX-ek nagyon jó lehetőséget kínálnak egy felpimpelt, throughput-barát működésre, ahogy a belső interconnect tempója növekszik a következő 2-3 generációban.
[ Szerkesztve ]
640 KB mindenre elég. - Steve Jobs
-
frescho
addikt
"Úgy magyarázták, hogy hardveres szinten alig volt közös rész. Annyi történt igazából, hogy az egyes kritikus részegységeket tervezték túl, hogy ki tudjanak szolgálni két szálat is."
Nem válaszoltál a kérdésemre, hogy konkrétan mik voltak a közös részek. Az eredeti Bulldozer bemutatódban a chip nagy része közös.
"A Pentium 4 ugyanott csúszott el, ahol a Bulldozer. Az nem véletlen, hogy az Intel és az AMD is letér a P6-szerű dizájnok irányáról, és együtt elcsúsznak."
Konkrétan mi volt az amiben a P4 elbukott és megegyezik ugyanez a hiba a Bulldozerben? Könnyű a szoftverre fogni, de semmi konkrétumot nem írtál, hogy mi volt a közös a P4 és a Bulldozer platformban. Konkrétan mit jelent az, hogy "P6-szerű dizájn" és a P4 miért skálázódott elfogadhatóan addig amíg nem futottak bele a maximális frekvencia/fogyasztás falba?
https://frescho.hu













 )
)




Új hozzászólás Aktív témák

it Az AMD 12,1 millió dollárért kisakkozta magát a perből. Jól járt mindenki?
