Új hozzászólás Aktív témák
-

Lina_99
újonc
Sziasztok!
Még csak most ismerkedem a Calibre programmal, de egy-két kérdésem lenne.
Ha például egy könyvnél a helyesírást szeretném ellenőrizni, jól gondolom, hogy a programban nincs ilyen, így jobban járok, ha például a Word dokumentumban ellenőrzöm? Vagy valamilyen gyorsabb lehetőség esetleg? Illetve ha a könyv PDF formátumban van, de ott is leakarom ellenőrizni a helyesírást, hogyan csináljam? Átkonvertálom a Calibren belül RTF formátumba, megnyitom Word-be és kijavítom?
Valamint ha PDF a könyv, de szeretnék tartalomjegyzéket, akkor szintén átkonvertálom RTF-be, megszerkesztem Word-ben, és visszarakom Calibre-be, ahol tudok már hozzátenni tartalomjegyzéket? (vagy akár word-ben is)
Előre is köszönöm a választ!
-
#669
 hampidampi
őstag
Lina_99
#668
hampidampi
őstag
Lina_99
#668
hampidampi
őstag
Leírom, szerintem hogy a legkönnyebb használni a Calibre-t:
Először is szükséged lesz egy forrás dokumentumra, amit betöltesz a Calibre-be. Ez valamilyen szerkeszthető, formázható, a Calibre által konvertálható formátum legyen (ajánlott: docx, rtf, html). A változtatásokat, szerkesztéseket, javításokat (helyesírás-ellenőrzést!) ezen az alap dokumentumon végezd el, majd konvertáld az olvasódnak kedves formátumába. Ez azért is praktikus, mert elég csak a Calibre-ből rákattintani és megnyitja wordben és direktbe tudod szerkeszteni a forrást, biztos nem vész el semmi változás és minden a Calibre Libraryjén belül marad.
Bár a Calibre a pdf-et is tudja konvertálni, azt érdemes tudni, hogy a pdf oldalképeket tartalmaz, nem folyószöveget, ezért a konvertálása általában igen nehézkes. Kvázi egy külön szakma.
Ha lehet, inkább valamilyen e-könyv, vagy szerkeszthető formátumban szerezd meg a könyveket. -

BonFire
veterán
Ha jót akarsz, semmiképpen ne tölts le PDF-et! Ha csak nem olyan könyv, ami rengeteg képet, illusztrációt tartalmaz. A PDF nem szerkeszthető, direkt arra van kitalálva, hogy ne lehessen beleszerkeszteni. Nyomdakész munkákat szoktunk kiadni a kezünkből PDF-ben, hogy a kedves kliens még véletlenül se tudjon belerondítani.
Ennél fogva elektronikus könyvre alkalmatlan formátum. Főleg annak a fényében, hogy a legtöbb felhasználó által készített könyv tele van helyesírási, tördelési, tipográfiai hibával, szkennelési törmelékkel. Nem árt tehát „gatyába rázni”, mielőtt az olvasóra küldöd. Ehhez szövegszerkesztő program kell és egy szerkeszthető állomány.
A PDF nem az! Ha átkonvertálod RTF-be mondjuk, akkor minden sor végén lesz egy bekezdésjel. Makróval ugyan kiszedheted, de akkor kezdheted saját kezűleg újratördelni az egész szöveget. Én már egy 600+ oldalas könyvvel végigcsináltam, aztán azt mondtam: soha többet!
A Prohardveren nem olvasok privátot! Csak topikban vagy a publikus e-mailemen adok tanácsot.
-
BonFire
veterán
-
BonFire
veterán
Sajnos, csak nagyon nagy munkával. Abban az egy esetben, ha semmiképp nem érhető el más változat, akkor neki kell esni makrókkal és kézi korrektúrázással. Egyébként keresni egy HTML-t, DOCX-et, RTF-et, amit közvetlenül tudunk szerkeszteni szövegszerkesztőbe.
Amúgy is tele vannak az OCR-ezettk könyvek apróbb-nagyobb hibákkal, nem árt, ha bele tudunk nyúlni.
A Prohardveren nem olvasok privátot! Csak topikban vagy a publikus e-mailemen adok tanácsot.
-

Oldman2
veterán
Jelenleg egy Calibre Library-t használok, de ma felmerült bennem, hogy ketté kellene ezt a jövőben választanom...
Elég sok könyvet digitalizálok (legtöbbször) PDF-ből, újabban eredeti könyveket is.
Azokat, amik "saját munkák" szeretném teljesen elkülöníteni az egyéb könyvektől.
Tudom, ezt egy könyvtárban is megoldhatom, de ma felmerült bennem hogy ez megoldható lenne-e oly módon, hogy majd az egyikből a másikba kényelmesen (a Calibre segítségével) át tudjak mozgatni egyes könyveket?
-
-
#865
 janosibaja
őstag
janosibaja
őstag
janosibaja
őstag
Sziasztok, az a kérdésem, hogy - tudván tudva, hogy a PDF nem e-könyv formátum -, ha mégis kizárólag pdf-ben tudok fellelni számomra fontos szövegeket, akkor hogyan tudom Kindle PW2-n viszonylag élvezhetővé konvertálni azokat. (Viszonylag - mert nem tudok hetekig kézzel javítgatni több ezer oldalt. Már kaptam jó tippeket a Kindle topicban, de felhívták a figyelmemet, hogy itt a Calibre topicban jobban vágják a dolgot.)
Ezer köszönet!

-
#866
BonFire
veterán
janosibaja
#865
BonFire
veterán
válasz
 janosibaja
#865
üzenetére
janosibaja
#865
üzenetére
A PDF-et olvasás közben kell korrektúrázni. Nyilván egy rakás dolgot automatizálni lehet, de úgyis olyan sok hiba marad benne (általában rosszul tördelt bekezdések), hogy kénytelen vagy végigolvasni és kézzel javítgatni.
Nem tudom, mások hogy csinálják, leírom, én hogy szoktam.
Keresés és csere funkcióval dolgozunk.
1. Keresse meg a bekezdést, amely kis kezdőbetűvel rendelkezik, és vigye fel az előzőbe (törölje az előző végéről a bekezdés vége karaktert).
2. Keresse meg azt a bekezdést, ami vesszőre, pontosvesszőre, kötőjelre, gondolatjelre végződik. Innen is törölni kell a bekezdés vége karaktert, és a következő – vélhetően szétszakított – bekezdés újra egyesül.
3. Azért is tanácsos ez utóbbit elvégezni, mert az 1 pont szerint nem fog semmit se csinálni, ha éppen tulajdonnév kerül új bekezdés elejére, de még az az előzőhöz tartozik. Az ugyanis nagy kezdőbetű.
Ha ez megvan, akkor el kell kezdeni végigpörgetni a könyvet, és ahol találsz még rosszul tördelt bekezdést, ott manuálisan helyrerakod.
4. Megformázod a fejezetcímeket címsorokkal, javítod az OCR-hibákat és nagyjából kész a könyv.
A Prohardveren nem olvasok privátot! Csak topikban vagy a publikus e-mailemen adok tanácsot.
-
#867
hampidampi
őstag
janosibaja
#865
hampidampi
őstag
válasz
janosibaja
#865
üzenetére
Ha szövegként van a pdf-ben, akkor én a pdf2epub programot szoktam használni. Meglepően jó eredménnyel dolgozik. A kimeneti epubot calibre-rel htmlz-be konvertálom, az wordbe elmentem és szerkesztem, majd újrakonvertálom azw3-ra.
Amennyiben viszont a pdf-ben a szöveg képként szerepel (scannelt), akkor csak az ocr marad. Arra a legjobb az abbyy finereader.
Egykattintásos megoldás nincs. Sajnos a pdf mindenféleképp pepecselős.
Magazinokkal, oktatási anyagokkal, színes-szagos kiadványokkal meg eleve nem érdemes foglalkozni. Azok olvasására tablet a jó, nem e-könyv olvasó. -
#868
janosibaja
őstag
hampidampi
#867
janosibaja
őstag
válasz
 hampidampi
#867
üzenetére
hampidampi
#867
üzenetére
BonFire és hampidampi: mindkettőtöknek köszönöm!
@hampidampi: közben kipróbáltam az Abby PDF Transform+ -t, s szinte hibátlan lett a pdf html-be konvertálva, majd onnan Calibre-vel mobi-ba
-
#869
BonFire
veterán
janosibaja
#868
BonFire
veterán
válasz
janosibaja
#868
üzenetére
Felkeltetted az érdeklődésemet. Kipróbálom a próbaváltozatot, mennyire hatékony. Ugyanis még soha egyetlen programmal sem sikerült a PDF széttördelt bekezdéseit normálisan átkonvertálnom, pedig csak egy kis szemre van szükség, amennyiben normálisan meg van formázva.
A Prohardveren nem olvasok privátot! Csak topikban vagy a publikus e-mailemen adok tanácsot.
-

keep2000
tag
Nektek, mint gyakorlottaknak biztosan könnyebben megy, de én nem boldogulok.
Van ez a könyv, amit szeretnék epub-ba konvertálni:
http://data.hu/get/9021245/The_Dead_of_Jericho_-_Colin_Dexter.pdf
A gond az vele, hogy ez egy két hasábos PDF és a Calibre nem jól konvertálja, néha a két hasábban egymás mellett levő sorokat összevonja.
A cél egy egyszerű folyószöveg lenne, a képek nem érdekesek, ha van benne 1-2 oldal, ami nem jól jelenik meg az is belefér, pl az eleje képként megy mindig. A formázás, tördelés "szépsége" sem érdekes, a lényeg, hogy a szavak megfelelő sorrendben legyenek és epubként tudjam olvasni.
Tudnátok segíteni?Xiaomi 11 Lite 5G NE, Honor MagicWatch 2
-
#876
keep2000
tag
hampidampi
#875
keep2000
tag
válasz
hampidampi
#875
üzenetére
Itt a PDF-ben az első oldal kivételével szövegként van minden, kijelölhető, másolható. Ezzel a részével nincs is gond, csak a két hasáb zavarja meg. Tehát ezt szerintem nem kell OCR-ezni
Xiaomi 11 Lite 5G NE, Honor MagicWatch 2
-

Geripapa
aktív tag
Arra van tippetek hogy mért van az hogy ha pdf et akarok megnyitni olvasásra akkor hibaüzenetet ad, ha a mappáját akarom megnyitni hibaüzenetet ad, ha a mobi formátumod akarom megnyitni azt megnyitja.
A pdf is létezik, mindegyiknél ezt csinálja ahol pdf van a könyvtárban.
[ Szerkesztve ]
Segítségkéréshez: NSA320+FFP; Raspberry Pi2 Openelec/Kodi ;
-
Geripapa
aktív tag
Ok, akkor generel nem lehet vele probléma.
Belehet az valahogy állitani hogy idöközönkén frissitse az adatbázist? Vagy elég szürni egy könyvre, stb. akkor amúgy is onnan dolgozik?+1 Ha van egy 2-3 oldalas "könyvem" pdf-ben azt szét tudja szedni 2-3 "könyvre" tehát egy oldal egy "könyv"? Vagy van hozzá esetleg kiegészitö? Vagy ne ezzel a progival akarjak pdf-et szerkeszteni
Segítségkéréshez: NSA320+FFP; Raspberry Pi2 Openelec/Kodi ;
-
BonFire
veterán
válasz
 Geripapa
#929
üzenetére
Geripapa
#929
üzenetére
Jegyezzétek már meg végre, hogy a PDF direkt azért lett kitalálva, hogy ne lehessen beleszerkeszteni! Ha szerkeszteni kell, akkor kell hozzá egy OCR, ami felismeri bekezdéseket és normálisan széttagolt szöveget konvertál belőle. Ha ez nincs, akkor egy Adobe Acrobat, ami szintén nem két fillér és házi használatra nem éri meg vele pöcsölni.
A PDF-et PDF-megjelenítővel érdemes olvasni mondjuk táblagépen. Egyesek olyat is tudnak, hogy a szöveget áttördelik, ami persze még mindig nem az igazi, de egy elfogadható alternatíva.
Az e-book az HTML-fájl, a PDF meg nyomdakész fájl.
A Prohardveren nem olvasok privátot! Csak topikban vagy a publikus e-mailemen adok tanácsot.
-
Geripapa
aktív tag
Félreérted, sem szerkeszteni sem e-könyv formátummá nem akarom alakítani. Igazából nem is könyvekről van szó hanem pár oldalas pdf-ekről.
Szóval azt találtam ki hogy a papír alapú szerződéseket, számlákat beszkennelem és calibrével rendezgetem, mivel így gyorsabban megtalálom ha kell, egyszerűbb keresni benne, ne beszélve arról hogy könnyebb továbbadni másolatot készíteni róla, stb... Szóval be van állitva a szkenner hogy egy adott mappába beszkenneli a dolgokat, ezt a mappát figyeli a Calibra majd mikor megnyitom akkor szépen beteszem a helyére az adatbázisba.És itt jön képbe az amit kérdeztem hogy többször előfordul hogy több levelet kapok egy nap. Ekkor kibontom őket beteszem a szkennerbe megnyomom a gombot és akkor egy pdf lesz az egész... Na ekkor jönne jól, a Calibren belül valahogy ketté lehetne vágni a pdfet.
De ha nem hát nem... Akkor kettévágom más progival...De ezt szerettem volna megspórolni.
Egyébként ha tudsz alkalmasabb programot a fentiek rendezésére szívesen veszem.
Segítségkéréshez: NSA320+FFP; Raspberry Pi2 Openelec/Kodi ;
-
#932
hampidampi
őstag
Geripapa
#931
hampidampi
őstag
válasz
Geripapa
#931
üzenetére
Nyugi, egyáltalán nem hülyeség, amit csinálsz. Ha jól el van látva címkékkel, nagyon nagy segítség a Calibre dokumentumok szervezésében. Sőt, igazából ez az elsődleges funkciója, a konvertálás csak másodlagos.
Én egyébként úgy csinálom, hogy a munkahelyi dokumentumoknak külön könyvtárat (libraryt) nyitok. Így jól elkülönül az olvasmányaimtól.
A pdf szerkesztésére valóban külső programot használj. Én a PDFill PDF Tools-t, vagy a jPDFTweak-et ajánlanám erre. Az előbbit könnyű kezelni, a második kicsit bonyolultabb, viszont tud kötegelt feldolgozást is. -
#947
hampidampi
őstag
lazlogogola
#946
hampidampi
őstag
válasz
 lazlogogola
#946
üzenetére
lazlogogola
#946
üzenetére
Sajnos ilyen, ha pdf-ből konvertált könyvünk van. Érdemes elkerülni, jobb formátumba beszerezni.
Amit esetleg érdemes megpróbálni, hogy konvertáláskor engedélyezd a Heurisztikus feldolgozást és legyen bekapcsolva a Sortörés ki opció. A Sorkiegyenlítési értékkel lehet variálgatni a jobb eredményért. -

lazlogogola
tag
válasz
hampidampi
#947
üzenetére
Akkor vszinűleg az eredeti forrás pdf volt és én abból kaptam az epub formátumot?
Azért ilyen?Ez azért érdekes mert van benne olyan is (sok) amit hivatalosan vettem, csak az előző olvasómon az epub formátum jött be a legjobban és azt rendeltem.
Most meg a Kindlere át kell konvertálgatnom.Azt nem tudom még,hogy visszamenőleg a bolt kiadná-e nekem más formátumba.
Mert ilyet még nem kértem. -
#949
hampidampi
őstag
lazlogogola
#948
hampidampi
őstag
válasz
lazlogogola
#948
üzenetére
"Akkor vszinűleg az eredeti forrás pdf volt és én abból kaptam az epub formátumot?
Azért ilyen?"Igen.
-
#951
 newmoonlight
senior tag
newmoonlight
senior tag
newmoonlight
senior tag
Sziasztok! A kérdésem az lenne, hogy Adobe Acrobat XI Pro-val, ha PDF-ben egy adott szövegmezőt akarok formázni (pl. sorkitöltést akarok csinálni), akkor ráteszem a kurzort és a program automatikusan csinál egy kijelölést. (Tkp. kijelöl egy keretet, amelyen belül szerkeszthetek.)
Sok esetben viszont nem pont azt, amit én szerettem volna. Jelen esetben itt is az 1. pont első sora (a piros nyíllal jelzett sor) nem "kereteződik be". Tehát a bekezdés első sorára nem vonatkozik a tervezett formázás. A kijelölést viszont nem tudom alakítani úgy, mint a "kijelölés szabad alakításával" pl. a Photoshop-ban. Hogyan tudom a kijelölést "felhúzni" az első sorra is, hogy arra is vonatkozzon az utasítás? (Jobb egér klikkel nem kínál fel semmi kijelölés-szerkesztési lehetőséget, de a menüben sem találok semmi olyat, amivel alakíthatnám a kijelölés keretét.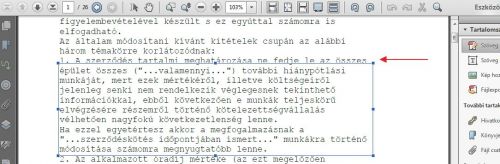
[ Szerkesztve ]
“Míg az ENIAC számológép 19 ezer vákuumcsővel van felszerelve és 30 tonnás, a jövőben a kompjútereknek talán ezer cső is elég lesz, és az is lehet, hogy nem lesznek nehezebbek másfél tonnánál.” (Popular Mechanics magazin, 1949.)
-

asuspc96
senior tag
Helló!
Létezik a neten valami jó leírás, hogy hogyan kell hatékonyan pdf/doc-ból használható ebook formátumot varázsolni, ami még igényesen is néz ki a könyvolvasón ?
ABBYY FineReader-t szoktam használni a beolvasásra, aztán ezt formázgatom wordbe, de reményvesztettnek látszik az ügy, elég hosszadalmas számomra
-
#1106
hampidampi
őstag
asuspc96
#1105
hampidampi
őstag
válasz
 asuspc96
#1105
üzenetére
asuspc96
#1105
üzenetére
Docból Calibre-ben is lehet konvertálni. Vagy plugin kell hozzá, vagy worddel átkonvertálod előbb docx-re.
A pdf már egy másik történet. Annál nincs egyszerű megoldás. Pdf-ből olvashatót alkotni gyakorlatilag egy külön szakma.
Mindenesetre az ilyen "egylépéses" konvertálásokat tuti felejtsd el. Mindenféleképpen kézi-pepecselős meló. -
#1109
newmoonlight
senior tag
asuspc96
#1105
newmoonlight
senior tag
válasz
asuspc96
#1105
üzenetére
Ugye jól értem, hogy az ABBYY-val (ahogy azt én is csinálom) a PDF-et egyből epub-ba konvertálod? (Egyébként valóban elnyammog rajta egy ideig, de amíg csinálja addig a már elkészült fájlokat rakom a Calibre-ba, majd a Kindle-re. Pont egyszerre szoktunk végezni.
)“Míg az ENIAC számológép 19 ezer vákuumcsővel van felszerelve és 30 tonnás, a jövőben a kompjútereknek talán ezer cső is elég lesz, és az is lehet, hogy nem lesznek nehezebbek másfél tonnánál.” (Popular Mechanics magazin, 1949.)
-
#1246
 frankstork
aktív tag
frankstork
aktív tag
frankstork
aktív tag
Sziasztok. Ebook fórumban javasolták hogy jöjjek ide...
Új nekem a calibre, nem igen értem néha mi miért történik. Csináltam magamnak egy válogatást kb 440 könyvet tartalmaz. Van ott minden. Doc, rtf, txt, html, pdf. (Egyébként költői kérdés, de minek ennyi kiterjesztés?)
Gondoltam hogy miután mindenki dicséri ezt a programot, biztos tök egyszerű lesz. Aha. Bemásoltam a könyvtárba az egészet, aztán elküldtem az eszközre. Alcor Myth Led.
Össze vissza könyvtárakat kaptam, van ahol semmi sincs, van amit nem is konvertált. Ha egyesével szüttyögök vele akkor minden rendben. De pl Asimov összes tartalmaz vagy 4 formátumot, konvertálás után a várt 6mappa helyett van 20, és van amit nem konvertált mert valamit hiányolt, van amit igen, de nem epubra, hanem hagyta doc.-ban. Szóval bonyolult. Nincs valahol valami leírás? Most úgy csináltam hogy egy mappát megnyitottam, a doc. és a html. kiterjesztésűeket megnyitva a tartalmukat atmasoltam txt.-be, és azt konvertáltam. Így viszont nem tudom az egészet megcsinálni, mindig csak annyit, amennyit a közel jövőben olvasni fogok, hátrány hogy nem tudok egy könyv elolvasása után válogatni több szerző közül, csak abból azb5-6 könyvből amit megcsinálgatok egyesével. -
#1247
 tecsu
addikt
frankstork
#1246
tecsu
addikt
frankstork
#1246
tecsu
addikt
válasz
 frankstork
#1246
üzenetére
frankstork
#1246
üzenetére
Ez egy ilyen bicikli, messze van a tökéletestől.
Sajnos sokféle formátum kering a neten, mint e-könyv, de valójában a jpg, djvu, pdf, txt, doc stb. nem annak való.
Érdemes tényleg e-könyv formátumban leszedni a könyvet (epub, mobi, prc, azw, kepub stb.). A Calibre próbálkozik az előzőkkel is, de ez utóbbiakkal boldogul igazán.
Txt-ből konvertálni nem jó dolog, hiszen úgy újra kell formázni a szöveget (szinte sorról sorra).A Calibre inkább csak rendszerező, mint konvertáló, viszont vannak kifejezetten (ingyenes) konvertáló programok. Figyelni kell a magyar ékezetekre, elválasztásra, szó és sortávolságra különböző fejezetek esetén (pl. párpeszéd szokott érdekes lenni).
A Calibre-hez pedig le lehet tölteni plug-ineket, pl. a Kobo olvasóhoz, de konkrétan már nem emlékszem, mert egyszer megcsináltam (talán két éve) és azóta van olvasnivalóm. Nem mindegyik könyv lett jó, nekem sem.
Nem mindegyik könyv lett jó, nekem sem.Leginkább a trehány feltöltés miatt van probléma. Én már azt sem értem, hogy a szerzőt és címet miért nem lehet helyesen megadni a metaadatokban...
Sajnos ezeket nekünk kell utólag kijavítani - ha pl. szerző szerint szeretnél keresni majd az olvasódon.https://www.youtube.com/watch?v=F7uwRuF6pYw
-
#1248
 Delfi
tag
frankstork
#1246
Delfi
tag
frankstork
#1246
Delfi
tag
válasz
frankstork
#1246
üzenetére
Ennek nekifuthatnánk újból, mert egy szót sem lehet érteni abból, hogy eddig mit csináltál.
Nem ismerem az Alcor olvasókat, szóval azt neked kellene tudni, hogy mit szeret és mit nem. Szögezzük le gyorsan, a Calibre könyvtárprogram, ez az elsődleges funkciója. Az, hogy emellett több-kevesebb sikerrel át is konvertálja a könyveket, csak egy másodlagos funkció, ennek megfelelően vagy jó lesz, vagy nem.
A "Bemásoltam a könyvtárba az egészet" számomra értelmezhetetlen. Ha esetleg arra gondolsz, hogy bedobtál egy könyvtárba 440 könyvet, majd az új könyv ikon "könyvek hozzáadása mappából" funkciójával behúztad őket a Calibrébe, akkor az nagyon rossz megközelítés és oltári katyvasz lehet a végeredmény.
Miután a felsorolt kiterjesztéseid közül egy sem e-book formátum, így jó eséllyel egyik sem jött létre helyes szerzővel és címmel. Ugyan a Calibre tud olyat, hogy a fájlnév alapján teszi be, de elég sok alkalommal megzavarja ha a fájl fejlécében talál valami szemetet. Ez a könyv készítőjének hibája, de mielőtt ezen elkezdenénk lovagolni, inkább köszönjük meg neki, hogy dolgozott vele. Aki tökéletes e-bookokat szeretne, az fáradjon a Libri pénztárához.
Nos, ha a fájlokat szépen egyesével húzod be(új könyv ikon), akkor a megjelent könyvet a "metaadatok" részen tudod az általad kívánt megjelenésre formázni. Szerző, cím borító hozzáadása, fülszöveg, és ami fontos, itt kell hozzáadni ugyanannak a könyvnek a több kiterjesztését! Pl, van neked egy .pdf, de megkaptad wordben is, akkor nem veszed fel kétszer, hanem jobbra fent ott lesz egy plusz jel, "új formátum hozzáadása". Ilyenkor a Calibre fő részében azt látod majd, hogy jobb oldalon a formátumoknál már pdf,doc is lesz, kattinthatóan, szóval megnyithatod onnan is. Akár ki is törölheted ha felesleges.
Amikor csatlakoztatod az olvasódat, akkor megváltozik a felső menüsorod, megjelenik az olvasó is. A főoldalon pedig új oszlop lesz, ami mutatja, hogy az adott könyvet áttetted-e már. Ilyenkor tudsz küldeni könyvet az olvasóra, a Calibre megkérdezi, hogy konvertáljon-e. Az én Kindlém pl. kezeli a pdf-et, de csak bicebócán, mert nem lehet ilyenkor nagyítani. Így én .mobit szoktam használni. Te tudod, hogy az olvasód mit szeret, így neked azt kellene kérned a Calibrétől. Alapvető ismeretként fogadd el, hogy a pdf nem szöveg, hanem kép. Egy nyomdai formátum, ami elszabadult és mindenki használja. Ha kapsz egy 40 megás könyvet pdf formátumban, azt előre tudhatod, hogy nem fogja tudni konvertálni a Calibre, mert ahhoz már egy karakterfelismerő program kell, mint pl. az ABBYY finereader, de még ott is hetekig fogod javítgatni az eredményt, hogy jó legyen. De az már egy másik témakör, az e-book készítése komoly feladat.
Szóval, ha van egy text formátumod, abból több-kevesebb hibával csinál megfelelő(inkább mondjuk úgy, hogy kompromisszumokkal olvasható) verziót a Calibre. A 3 mega körüli pdf-ekből is, mert ott már valaki átalakította a fájlt, az biztosan nem scannelt pdf.
A könyvtárszerkezetet ne piszkáld, szerintem teljesen mindegy, hogy hogyan kezeli a Calibre, neked nincs vele dolgod. Amúgy elég jó rendszere van, a Calibre Library(oda teszed, ahova akarod, nekem a gyökérben van) alatt szerző szerint könyvtárba teszi, majd alatta könyvek szerint is. Ott már látsz egy számot is, ami a könyvtár szerinti sorszáma, szóval azt sem kellene piszkálni. Egyáltalán nincs semmi dolgod sem ezzel, ahogy az olvasódon sem, ahol ugyanezt a metódust fogod megtalálni, ha fájlkezelővel nézel rá. De ne tedd!
Azt tudnod kell, hogy a .mobi nem kezeli a sorozatokat, így ha szeretnéd tudni, hogy a Harry Potter negyedik könyve melyik, akkor sajnos azt a fájlnévben kell megjelenítened, különben az olvasón nem fogod tudni. Az .epub kezeli ezt, így viszont érdemes a Calibrében a helyén kezelni ezt.Nem szeretnélek megsérteni, de az illegális e-book olvasás a türelmeseknek való. Akik hajlandóak elfogadni a sok munkát a könyvtárukkal, a kompromisszumokat amit az olvasás érdekében hozol, amikor pl. minden sor között van egy üres sor, vagy amikor bent marad az oldalszám, esetleg a lábjegyzet bekerül a törzsbe.Ha ez téged zavar, akkor marad a vásárlás, azok elvileg profi formázáson esnek át, megfelelő felhasználói élményt nyújtva.
-
#1251
frankstork
aktív tag
Delfi
#1248
frankstork
aktív tag
és @tecsu:
Köszönöm a türelmeteket, és az érthető beszédet. Sok kérdésre kaptam választ.
Tehát, ha szeretnék rendes könyvtárat, akkor bizony egyesével kell rakosgatni, konvertálgatni. Ami különben nem akkora érvágás, havi 2-3 könyvet olvasva, egy félévre való pakk is csak 15perc, persze előre kell tudnom mit szeretnék majd olvasni.
Megtudva hogy a calibre nem transzformátor elsősorban, már nem utálom annyira. Kiismerni kell egy kis idő, de majd csak belejövök.
Egyébként az Alcor szereti az epub.-ot, úgyhogy arra konvertálok, pdf.-ből is sikerült már beforditani, nem lett rossz, a html.-ben lévőket pedig txt.-ben elég jól elviszi, igaz ahogy mondtad vannak sor közök, meg tördelési anomáliák, de ez a kompromisszum...[ Szerkesztve ]
-
#1254
tecsu
addikt
frankstork
#1251
tecsu
addikt
válasz
frankstork
#1251
üzenetére
Pdf-et átalakítani nagyon változó eredménnyel jár. Az egyiket sikerül, a másikat nem. Az egyik pont ,megfelelő betűméretű lesz, a másik nem; az egyik jól van tördelve, a másik összefolyik...
A pdf inkább magazinok, brossúrák formátuma, amit 1:1-ben jó olvasni mondjuk színes tablettel.[ Szerkesztve ]
https://www.youtube.com/watch?v=F7uwRuF6pYw
-
#1347
hampidampi
őstag
excalibur36
#1342
hampidampi
őstag
válasz
 excalibur36
#1342
üzenetére
excalibur36
#1342
üzenetére
Szerintem inkább szerezd be eleve rendes formátumba. Ne próbál Pdf-ből normális e-könyvet csinálni, az egy külön szakma.
Egyébként a Kindle-re érdemesebb azw3-ba konvertálni, nem mobiba. Az azw3 sokkal nagyobb tudású. -
#1349
Degeczi
nagyúr
excalibur36
#1342
Degeczi
nagyúr
válasz
excalibur36
#1342
üzenetére
Fogadd meg Hampidampi tanácsát: a PDF konvertálás NEM egy egyszerű save-as kérdése, hanem rengeteg tapasztalat és sok munka kell a korrekt eredményhez.
Valóban sokkal célszerűbb eleve e-book formátumban beszerezni a könyvet - és ha az népszerű, sokak által olvasott, akkor biztosan be is szerezhető úgy, valaki más már megcsinálta.
-
#1350
 Ajándékok
aktív tag
excalibur36
#1342
Ajándékok
aktív tag
excalibur36
#1342
Ajándékok
aktív tag
válasz
excalibur36
#1342
üzenetére
Ha nem grafikus a pdf (max pár megabyte), a mobipocket creator használható eredményt ad.
Nagy raktár kis helyen! Anyagáron eladó ~200m hosszú rakódófelületű gördülő polc rendszer. A helyigénye csak 3.6m*1.4m. Akár egy lakáscserét is megspórolhat vele!
-
#1352
 excalibur36
senior tag
Ajándékok
#1350
excalibur36
senior tag
Ajándékok
#1350
-
#1353
Ajándékok
aktív tag
excalibur36
#1352
Ajándékok
aktív tag
válasz
excalibur36
#1352
üzenetére
Importnál a 4. pozíció a pdf. PRC a kimenet, de átnevezheted mobi-ra.
Nagy raktár kis helyen! Anyagáron eladó ~200m hosszú rakódófelületű gördülő polc rendszer. A helyigénye csak 3.6m*1.4m. Akár egy lakáscserét is megspórolhat vele!
-
#1355
excalibur36
senior tag
Ajándékok
#1353
-
BonFire
veterán
válasz
 Ajándékok
#1350
üzenetére
Ajándékok
#1350
üzenetére
Én nagyon ritkán kényszerülök PDF-et konvertálni, de az első lépés mindig az, hogy szövegszerkesztő számára emészthető formátumba konvertálom. Mondjuk RTF-be. Aztán az RTF-et Writerben megnyitom, és korrektúrázom. Ha a konverter elbarmolta a sortöréseket, azokat helyre kell állítani, ha pedig tabulátorral húzza be a bekezdések első sorát, azt is ki kell szedni és behúzatni rendesen (már ha a képernyőn is rendes behúzást akarsz, mert egyébként a könyvolvasó megcsinálja ezt programból helyetted). Aztán kialakítom címsorokkal a tartalomjegyzéket, majd megtem az ODT-t, amit aztán a Calibre-rel a kívánt formátumba tudok alakítani minden további nélkül.
A Prohardveren nem olvasok privátot! Csak topikban vagy a publikus e-mailemen adok tanácsot.
-
BonFire
veterán
PDF?

Konvertáld szövegszerkesztő által emészthető formátumba (DOCX, ha MsWord-öd van, RTF, ha LibreOffice), majd rá lehet uszítani egy rossz sortörés szkriptet, valahogy így:
LibreOffice Writer Batch
[Name] Széttört bekezdések egyesítése
[Find]([a-zA-ZéáűőúöüóíÉÁŰŐÚÖÜÓÍ–,-])$
[Replace]\1
[Parameters] MsgOff MatchCase Regular
[Command] ReplaceAllHa vannak széttört szavak is elválasztójellel külön sorban, azt is külön egyesíteni kell, így:
[Name] Szétszakított szavak egyesítése
[Find]-\p
[Replace]
[Parameters] MsgOff MatchCase Regular
[Command] ReplaceAllEz utóbbit kézzel kell egyesével ráengedni, mert ha történetesen valódi kötőjeles szóösszetétel kerül külön sorba (már-már, egy-egy, egy-két), akkor ott nem hiba, ha el van választva, de ellenőrizni kell, hogy valóban indokolt-e hogy külön bekezdésbe került. Ezeket ki kell hagyni és egy következő körben korrektúrázni.
[ Szerkesztve ]
A Prohardveren nem olvasok privátot! Csak topikban vagy a publikus e-mailemen adok tanácsot.
-
#1438
BonFire
veterán
hampidampi
#1436
BonFire
veterán
válasz
hampidampi
#1436
üzenetére
Van, amikor nincs más opció a PDF-en kívül. Wordben, Writerben lehet ezeket korrektúrázni, ha van az embernek néhány fölösleges órája. Nekem már a legtöbb ilyen műveletre van szkriptem, de vannak bizony helyzetek, amit kézzel kell egyesével felülbírálni, ami nem megy gyorsan, és a gondos munka ellenére még azért befigyel egy-egy hiba.
Ami már azért annyira nem zavaró.
A Prohardveren nem olvasok privátot! Csak topikban vagy a publikus e-mailemen adok tanácsot.
-
#1439
zseko
veterán
hampidampi
#1436
zseko
veterán
válasz
hampidampi
#1436
üzenetére
Nem. Ez mobi. Csak trehány volt aki készítette. Már évek óta nem olvasok pdf-et, csak ha muszáj, tableten is, és telefonon is jobb volt eleve mobit vagy epubot használni.
(#1437) BonFire köszi, ez most épp nem jutott eszembe, pedig múltkor hasonlóképp csináltam
 Nem vagyok rutinos, na Azóta sikerült részeredményt elérni, AZW3-ba konvertáláskor ráengedtem a heurisztikus keresést, vagy mit, az elég sokat javított, most már csak a maradékot javítom át, bár itt a vége felé meg már kicsit túlzásba is esett
Nem vagyok rutinos, na Azóta sikerült részeredményt elérni, AZW3-ba konvertáláskor ráengedtem a heurisztikus keresést, vagy mit, az elég sokat javított, most már csak a maradékot javítom át, bár itt a vége felé meg már kicsit túlzásba is esett
LibreOffice van egyébként.[ Szerkesztve ]
HR24.hu
-
tecsu
addikt
Eljött az idő, hogy több év után újra feltöltsek könyveket a Kobo Aura H2O olvasómra a Calibre-ből, de sajnos nem emlékszem, hogy csináltam azelőtt.
A Kobo-nak van egy saját "desktop" alkalmazása, amivel lehet(ne) frissíteni a drivert, de egyszerűen nem csatlakozik az eszköz.
Micro USB be, az olvasó kiírja, hogy csatlakozott és tölt is, sem a Windows 7-es, sem a Kobo Desktop, sem a Calibre nem jelzi, hogy észrevette volna.
Valaki tud ezzel kapcsolatban segíteni?Majd ezután szeretnék a Calibre-ben könyveket elkülöníteni, amit próbáltam virtuális könyvtárral, de oda nem tudom áthúzni a "rendes könyvtárból" az adott könyveket.
(A nagy fájlokat szeretném külön kezelni, mert pl. 120MB-os pdf-vel nem próbálkoznék az olvasón, így lenne egy "Nagy fájlok" mappa vagyis "virtuális könyvtár" külön, de fizikailag mégis egy helyen.
Külön "Library" mappát nem akarok, mert a biztonsági másolások esetén esetleg elfelejtem...)
Vagy van erre más megoldás? "Tag"-gel megjelölni szerintem nem a legpraktikusabb, hiszen az csak akkor válik külön, ha éppen azt a tag-et szűröm.[ Szerkesztve ]
https://www.youtube.com/watch?v=F7uwRuF6pYw
-

snowdog
veterán
Nem mondod komolyan, hogy 5 GB könyvet akarsz az olvasóra másolni! Soha az életben nem tudod elolvasni. Akkor meg minek rámásolni?
Phülöp
Minek tartogatsz minden könyvet két formátumban? Kétszer annyi helyet foglal a semmiért. Ha van egy rendes formátumod, mondjuk az AZW3, akkor minek a MOBI formátum? Ha netán mégis szükséged lenne a MOBI-ra, a Calibre egy pillanat alatt átkonvertálja AZW3-ból.Most álltam neki (több év után ismét) rendbe tenni a Calibre könyvtáramat. Először 2013-ban fogtam neki, akkor nyitottam ezt a topikot. Aztán évekig nem értem rá vele foglalkozni. Most ismét nekikezdtem.
Csak olyan formátumú könyvet tartok meg, amit a PW olvasó elfogad. Tehát az EPUB, a PDF és hasonlók szóba sem jönnek.[ Szerkesztve ]
-

G.F.
aktív tag
Konvertáltam egy könyvet pdf-ből. Jó sokat molyoltam vele, és mostmár csak egy nagy gondom van.

A képen látott módon, néhány párbeszéd gondolatjel helyett 'felsorolásos lista' formázással jött létre. Ezeket szeretném valahogy cserélni rendes gondolatjelre, csak épp nem tudom hogyan... Ebben kérnék segítséget.
Alt. Find ana Replace pluginom van, csak nem tudom mit cseréljek mire...-gf-
-

moma
őstag
köszi hampidampi az ideirányítást!
Sziasztok kicsit off lesz, de talán itt van legjobb helyen, mert úgy érzem a calibre központi helyen lehet a megoldásban.
Szeretnék kialakítani egy jó struktúrát olvasáshoz. Az lenne a szempont, hogy amit elkezdek olvasni telefonon és szöveg kiemelek benne jegyzeteket rakok bele, azt tudjam folytatni asztali gépen is. És a jegyzeteket könnyen kiszedni aztán ha szükséges szöveges fileba. És ezt minél kevésbé file formátum függően(esetleg webes cikkekhez is). Van hasonlóra kialakult módszere, alkalmazásai valakinek? Szeretnék venni egy ebook olvasót is és akkor azon is olvasni, szöveget kiemelni, jegyzetelni. De először meg kéne értenem a lehetőségeimet egyáltalán a fileokkal szerintem és ha értem az igényeimet hozzá egy olvasót majd.
Először használtam telefonon a moon+ readert, de annak nincs asztali verziója. Meg nem is értettem meg egészen a jegyzet kezelést, hogy azt hogy lehetne áthozni egyszerűen asztalira.
Aztán most próbálkozom a xodo nevű appal, de ez csak pdf.
Meg amit észrevettem, hogy pdf-et nem túl jó olvasni asztali gépen, mert túl hosszúak nekem a sorok. Szóval lehet mindenképp ott indul a dolog, hogy a pdfet alakítani kellene olvasás előtt valami rugalmasabb formátumba. epub talán? vagy valami webes fileformátum lenne a jó. pl firefoxban szeretem a reader viewt pl de ott nem lehet szöveget kiemelni, meg jegyzetelni egyszerűen bele.
Ha nem is tudtok megoldást, de ha van akit érdekel ez a téma, akkor lehetne együtt gondolkodni.
we all deserve a bit of luck.

























 Nem mindegyik könyv lett jó, nekem sem.
Nem mindegyik könyv lett jó, nekem sem.













