- Videó stream letöltése
- Kodi és kiegészítői magyar nyelvű online tartalmakhoz (Linux, Windows)
- Sweet.tv - internetes TV
- Otthoni hálózat és internet megosztás
- Xiaomi AX3600 WiFi 6 AIoT Router
- Telekom otthoni szolgáltatások (TV, internet, telefon)
- Milyen switch-et vegyek?
- Linux kezdőknek
- Hálózati / IP kamera
- A Microsoft feltalálta az olcsó AI-t
Új hozzászólás Aktív témák
-

S_x96x_S
őstag
> Én így képzelem jelenleg:
> 2022 év vége:
> zen5 cpu chiplet 1db (16mag) 5nminkább 2023 lesz abból, hogyha 12-18 hónapos váltásokat nézünk.
És szerintem maradnak 8-12 -es core méretnél, mert az
- AVX512
- SMT4
rengeteg helyet elfoglal.
habár ki tudja ...
de szerintem a következő pár évben az egy core-ra eső teljesítményt próbálják növelni.de az is lehet, hogy több különböző chiplet lesz.
Mottó: "A verseny jó!"
-
Most se a cpu mag az ami sok helyet foglal chippen belül, hanem a cache, így "elfér a több mag", ha kap HBM-et a rendszer a cache növelését akkor meg el lehet halasztani.
és azért gondoltam 16magot, mert nem számolok azzal, hogy áttervezik a ccx-et, hanem csak beledobnak 2db 8magos ccx-et.. így "kiadja".
Azt lehet tévedek.. biztosat csak azon mérnökök és vezetők tudnak még akik ezeken dolgoznak.
De azt majd meglátjuk a zen5 lényegében a zen4 egy finomítása lesz (valószínűleg), sokkal inkább körvonalazódik majd a kép ha látjuk mi meddig jut el .. de nagyon messzire jutottunk még a zen3 sincs a kanyarban.
leginkább arra akartam, utalni, hogy HBM szerintem előbb nem kerül a chippek mellé még pár évig mert a glofo (ha megtartják), csak akkortájt tud elérhető termékekkel rendelkezni majd.. onnantól meg "adja magát" a felépítés, bár közel se biztos, hogy egy ütemben lépik meg ezt mind.
De a méretnövekedése a chipletnek se ördögtől való, nem lehetetlen, most is gyárt amd nagyobb chipeket 7nm-en a cpui chipletjei méreténél.. az interposerrel meg helyet spórólhat és ha úgy is szükség van interposerre az esetleges nagyobb sávszélesség igény miatt, akkor megint "adja magát" az elv.
De igen, ezen mint csak merő spekuláció a különböző információmorzsák összelegózásából... "nem lehetetlen", de nem tudjuk még is lehetséges-e. lehet csak egy valami nem jön össze és minden borul egy ilyen komplex lépésnél (ha terveznék). Így inkább több lépcsős bevezetésre tippelnék, az első ilyen lépcső szerintem zen3ban a 8magos ccx, majd zen4 idejére talán interposer és hbm lehetőség (tippre zen4 inkább felépítésben fejlődik).. zen5 pedig annak a finomítása grafikus vezérlővel kiegészítve. a megvalósulás persze biztos lehetséges, lehet csak az időben tévedek és inkább 23vége 24eleje a céldátum (vagy amikorra ez elkészülhet).. bár szerintem az intel miatt 23eleje a legkésőbbi határidő amikorra kell valami "ütős" (ha nem is ez, de valami más mint ami most van, mert lehet az kevés lesz).
A zen magokat csak mint referencia használom, de a zen3 után szerintem utóbbiak csak finomodni fognak pár generációt és inkább a körítés fejlődésén lesz a hangsúly.The human head cannot turn 360 degrees... || Ryzen 7 5700X; RX580 8G; 64GB; 2TB + 240GB + 2TB || Samsung Galaxy Z Flip 5
-
válasz
 S_x96x_S
#2701
üzenetére
S_x96x_S
#2701
üzenetére
SMT4 esetén eleve nem növelnék szerintem a magszámot. Pusztán a plusz 2 szál per mag exponenciálisan jelentene több teljesítményt, ha az SMT skálázódása megfelelő (4 mag / 8 szál -> 4 mag / 16 szál v. 8 mag / 16 szál -> 8 mag / 32 szál).
Légvédelmisek mottója: Lődd le mind! Majd a földön szétválogatjuk.
-
#2704
 Petykemano
veterán
TRitON
#2693
Petykemano
veterán
TRitON
#2693
Petykemano
veterán
Nemrég vetettem fel, hogy vajon egy ma $200-250-ért árult ryzen-t és egy $300-ért árult navi10-szerűséget 16GB HBME2-vel össze lehet-e pattintani egybe mondjuk alaplappal és hűtővel $500-ért?
De a két dolgot én szétválasztanám.
Tehát egy dolog egy méretes IGP, ami szükségtelenné teszi a dGPU-t a nagy többségnek (elvileg)
És megint egy másik egy olyan IGP, amit nem feltétlenül grafikára használsz.Találgatunk, aztán majd úgyis kiderül..
-
"Most se a cpu mag az ami sok helyet foglal chippen belül, hanem a cache, így "elfér a több mag", ha kap HBM-et a rendszer a cache növelését akkor meg el lehet halasztani."
Pont ezt mondom, hogy a cache-t nem növelve is dupláznád a chiplet tranyószámát, miközben az 5nm nem fog fele akkora effektív terület-hatékonyságot hozni. Csak az marad, hogy csökkented akkor a cache mennyiségét.
A Zen2 esetében a három cache:
L1: 32kB és 4 cikluson belül elérhető
L2: 512kB és 12 cikluson belül elérhető
L3: 16MB és 40 cikluson belül elérhetőAz L3 az I/O modulon van, és per CCX vonatkozik, tehát nem közös L3-at látnak a CCX-ek, hanem minden CCX-nek van egy 16MB-os L3 egysége az I/O modulon belül.
Na most ebből könnyen kitalálható, hogy ha kevesebb cache-t akarsz adni a magoknak, hogy elférj a CCX-en, akkor az L1 és L2 cache-t tudod csökkenteni. Ez a Zen1 óta ennyi, szóval ha csökkented, akkor esélyesen bukni fog a teljesítmény. Ugye emlékszünk, hogy a Zen is első sorban szerverbe szánt chiplet, ami amúgy a desktopokra is jó, szóval neked figyelembe kell venni, hogy mivel jár ez. A szerverekben mutatott teljesítményben pedig sokat számít a cache méret.
Szóval hiába lesz neked akár 4GB-os vagy 8GB-os L3 vagy L4 HBM alapú cache-ed, az esélyesen nem kevesebb, mint 80 cikluson belül lesz elérhető (erős tipp, de biztosan több, mint az I/O és a chiplet közötti elérés). Ezen javíthat, ha a HBM modulok az I/O chipre lesznek felstackelve, így könnyebben és gyorsabban elérné, mintha mellette lenne és interposeren keresztül csatlakozik csak. De nem tudja kiváltani a kisebb L1 és/vagy L2 okozta sebességvesztést. Egy szerverben (is) használt chipletnél ez nem fér bele, pont, hogy inkább növelni szokták a cache méretet...
Ez a logika az, ami miatt kétlem, hogy az 5nm-en a 16 magvas chiplet esélyes. Még az SMT4 esetén is húzós lesz elférni nagyjából azonos alapterületen...
[ Szerkesztve ]
Légvédelmisek mottója: Lődd le mind! Majd a földön szétválogatjuk.
-
S_x96x_S
őstag
> SMT4 esetén eleve nem növelnék szerintem a magszámot.
az lehetséges ..
-------ZEN5.
ha én tervezném, akkor az egyik prototípus olyan lenne, hogy:
- 1,5x nagyobb foglalat ( téglalap alakúra elnyújtva ) - persze a hütés nem lesz egyszerű ... , de jobban eloszlik a hő ... Ha már úgyis változik a foglalat, a ccx-es legózás miatt nem muszáj négyzet alapúnak lennie. És miért ne lehetne nagyobb ??
- én maradnék mindenképpen 8core -nál ; mert sokkal kisebb ccx-ek ( és ebből akkor több elfér a foglalatban ... és a wafer-en is .. mert ezt sokkal sokkal drágább gyártani az 5nm-en.) és akkor skálázni is könnyebb ...
- Ha kisebb ccx, és a foglalat picivel nagyobb; akkor akár már 4 ccx is beleférne .. --> és íme .. megvan a 32core -is ...És 32-core már simán elvárható is egy desktop-os gépen, ha most 16-nál járunk....
Főleg akkor, hogyha az Intel is ugyanennyit tervez.
De ekkor már kötelező is lesz az AMD részéről !És a ZEN5 idején már jönnek az ARM-es Windows-os Desktop gépek .. és ezeknél is lehet 16/32 core alapból ..
-----------
Vagyis igazából a versenytársak ( Intel, ARM , .. ) legjobb várható lépése alapján kellene az AMD-nek kialakítani a magszámot ..
És így mindenképpen a 32core-t be kell lőnie célként![;]](//cdn.rios.hu/dl/s/v1.gif) ...
...Mottó: "A verseny jó!"
-
chipleten van az L3, csak CCX-hez rendelve de közös címtérrel, így minden cpu hozzáfér, de a jelenlegi cpukban 2x16MB (1chipletes cpu) vagy 4x16MB(2 chipletes cpu), ez akár ki is költözhet az IO diebe, de ha elég gyors az elérés egy HBM kiválthatja ... de lehet akár csak emiatt egy chiplet is külön (nem extrém elképzelés ha már úgy is IF-en csücsül a nagy része és azon át érhető el, esetleg L2-őt kicsit növelve ellensúlyozni a késleltetést ha magon belül lenne a használat). De HBM-el akár csökkenthető a mérete a jelenlegi felépítés mellett is.
Kérdés mi mennyi teljesítmény vesztességgel vagy nyeréssel jár, ezt a belsős szakemberek eléggé jól megtudják tippelni és abba az irányba elvinni a fejlesztést.AVX512 támogatást biztos elhúzzák addig amíg csak lehet (hogy ne legyen). AMD-nek nem érdeke, és eltudnám képzelni, hogy csak "emulálva" jön majd (futtatja, de csak ennyi, nem lesz gyorsabb) az első generáció belőle... de zen4 elé nem raknám a támogatást (a zen3-ra már mondták, hogy nem lesz benne AVX512).
Az is a gond körülötte, hogy "nincs kész", intel esetén is generációról, generációra változik, hogy mi van benne (hozzáadnak, elvesznek)... ez így maximum szívatásnak jó.[ Szerkesztve ]
The human head cannot turn 360 degrees... || Ryzen 7 5700X; RX580 8G; 64GB; 2TB + 240GB + 2TB || Samsung Galaxy Z Flip 5
-
-
S_x96x_S
őstag
Április elején jönnek az új ASUS-os laptopok a 4xxxx APU-val.
-----------
AMD Ryzen 7 4800H Notebook Prices Reportedly Leaked; Launching in April
https://www.hardwaretimes.com/amd-ryzen-7-4800h-notebook-prices-reportedly-leaked-launching-in-april/
Mottó: "A verseny jó!"
-
#2710
Petykemano
veterán
S_x96x_S
#2695
Petykemano
veterán
válasz
S_x96x_S
#2695
üzenetére
"Lehet, hogy Raja re-inkarnálta a OneAPI -ba a legtöbb HSA ötletet."
Nem volna rossz, de csak hogy lássuk, hogy Abu nem habokra tépte a száját.
Amúgy nyilván mindig felmerül a kérdés: mik azok a műveletek, vagy inkább úgy fogalmazok, hogy jobok, batchek, taszkok, amelyeknél egy finomszemcsés gpu gyorsítás megéri mondjuk főleg a vektoros AVX(512)-szel szemben?
Valamilyen elvont értelemben ugye ugyanarról beszélünk: van egy halom adat, amire a frontend ráenged valamilyen feldolgozó egységet. Csak egy CU nyilván lényegesen messzebb van, lassabb adat-összeköttetéssel és a vezérlés sem megoldott.
Találgatunk, aztán majd úgyis kiderül..
-
#2711
Petykemano
veterán
DraXoN
#2699
Petykemano
veterán
"Ez megszüntetheti az említett szűk sávszél problémáját.
A közös címtér miatt meg nem kell majd mindent betölteni a cpu-n levő ramba, csak ami kell, így a gyorsítótárban elfér a fontos adat és ami később kell majd át lehet tölteni a fő ramból (már azt is gyorsabban ddr5 alapokon).
Én mindenképp a zen4 vagy zen5 időszakára várnám a következő nagyobb design ugrást emiatt. Azt nem tudom persze ez már 3D tokozás lesz-e, vagy csak esetleg 2.5D, vagy marad 2D mint a mostaniak. Hely szempontjából a 3D a legjobb, de a hűthetőségnek erősen gondot jelent. A 2D ügye sok helyet igényel, és esetlegesen nagyobb távolságokat ami késleltetésben nem jó. A 2.5D egy jó kompromisszum lehet."Igazából az AMD-nek már megvan a technológiája erre: HBCC
Az pont azt csinálja, hogy a GPU fedélzeti ramját csak gyorsítótárként használja.A cache layerekről persze általánosságban elmondható, hogy minden layer hozzáadhat egy adatkérés késleltetéséhez - amennyiben az nem található meg a cache-ben. Ezt persze szerintem okos prefetcherekkel kezelni, meg azért 2-8GB elég gigantikus ahhoz nagy legyen a haszon az esetleges veszteséghez képest.
Azt nem tudom, hogy vajon a HBCC milyen késleltetést adott hozzá a pcie-en keresztüli adateléréshez? És hogy ehhez képest ha egy ilyen megoldás a RAM előtt van L4$-ként, akkor ahhoz képest ez milyen. Valamint hogy mennyit számíthat az a ram késleltetésében, hogy a HBM2 nagyon közel (pár mm) van az IP chiphez szemben a RAM-mal, ami pár cm-re.
Teszem hozzá, a HBM2 valószínűleg nem késleltetés-bajnok, különben már rég használnák ilyen célre.
A 3D szerintem abban segíthet "csak", hogy szükséges-e interposer. Mert ha most az IOD tetejére rá lehetne pakolni HBM-et, az már most is működne.- (Más kérdés, hogy vajon a két lapka közötti szintkülönbséget mivel hidalnák át?)
Ugyanakkor meg azt is tudjuk, hogy az interposeres lapka-összeköttetés lényegesen tudná csökkenteni a fogyasztást, ami pedig az IF esetén így se kevés.
Bár az IO lapkára pakolni valamilyen cache-t egészen adná magát, hiszen azon keresztül fut minden memória felé való kérés. Én ugyanakkor lehet, hogy több potenciált látnék abban, hogy a compute lapkák 3D tokozásával alá, vagy alá-fölé akár több rétegben (nem is feltétlen HBM) cache-t tennék. Valószínűleg L4$-nek nevezném, megtartva jelenlegi L3$ méretét.
Ugyanakkor érdekes kérdés, hogy vajon mennyit érhet (hány % IPC) egy ilyen?
[ Szerkesztve ]
Találgatunk, aztán majd úgyis kiderül..
-
S_x96x_S
őstag
AMD EPYC 7272 Review 12 Cores of Rome
https://www.servethehome.com/amd-epyc-7272-review-12-cores-of-rome/
( A.l.z.a.n.á.l br.258eFt , avagy 203e+ÁFA)
( 12 magos, 24-szálas, 2,9 GHz, Boost technológiával akár 3,2 GHz, 64 MB L3 cache, TDP 120 W, EPYC 7002, hűtő nélkül, AMD SP3 foglalat )
Ami furcsa, hogy a 16magos 7282 10eFt -al több.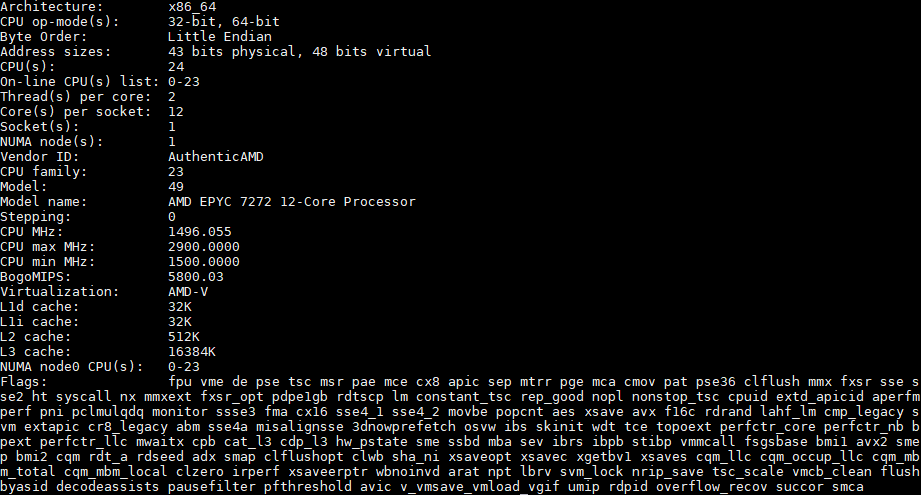
Mottó: "A verseny jó!"
-
S_x96x_S
őstag
> Kicsit furcsán lőtte be az AMD a CPU-k árát...
árazás ...
Az ArsTechnica csinált egy ár-thread összehasonlítást..
Ebben érdekes - hogy az Intel elég jól belőtte az új HEDT-es i9-10980XE prociját egy leheletnyivel az új threadripper 3960X alá ; éppen annyira, hogy azért én is elgondolkodjak. ... (legalábbis a 2x AVX-512 FMA Units -t azért csábító.; de ezen kívül meg minden másban meg nem ... )persze az AM4 -es 3950X ($750/32thread = $23.4 -re jön ki , ..
vagyis az Intel 10980XE - $27.78 thread ára .. éppen elég jól pozicionált.
Sóhaj/óhaj ... lehetne egy 16c/32t -es Threadripper proci is ...
Mottó: "A verseny jó!"
-
S_x96x_S
őstag

AMD EPYC™ Cloud Adoption Grows with Google Cloud
"New Google Compute Engine N2D virtual machines (VMs) based on 2nd Gen AMD EPYC™ processors provide double digit savings and performance improvements over existing N-series instance"
https://www.amd.com/en/press-releases/2020-02-18-amd-epyc-cloud-adoption-grows-google-cloudGoogle-os post ( "N2D" )
https://cloud.google.com/blog/products/compute/announcing-the-n2d-vm-family-based-on-amd
"N2D VMs are now available in beta from us-central1, asia-southeast1, and europe-west4, with more regions on the way!"akit érdekel - FREE Trial $300 free credit .. -es link is van az oldalon ..
https://cloud.google.com/free/[ Szerkesztve ]
Mottó: "A verseny jó!"
-
S_x96x_S
őstag
UE / Játékok >= 16core felett..
Állítólag az "Unreal Engine" - kapott egy kis optimalizációt
(3990X) "AMD’s also verified 64-core scaling for compiling projects like Android OS or Unreal Engine, so there will no doubt be some demand for those tasks as well." ( link )
és mintha a Crysis is UE4 -el fut ..
valamint a Crysis -t lehet tisztán CPU-n is futtatni ( TR3990X-el )
de ezen kívül tud valaki még valamit, hogy az UE - mennyire támogatott több core -on ? melyik verziót érinti, az ezzel készülő játékok mikor jelenhetnek meg ? ( esetleg bármi technikai részletet ? )Mottó: "A verseny jó!"
-
válasz
S_x96x_S
#2716
üzenetére
Állítólag az "Unreal Engine" - kapott egy kis optimalizációt
...a kódfordító motorhoz (compiling), és nem a játékengine-hez magához.
de ezen kívül tud valaki még valamit, hogy az UE - mennyire támogatott több core -on ?
Úgy tudom 64 szálig skálázódik. *Doppergés* függően attól, milyen jellegű terhelést kap.
Ez a fő probléma a fejlesztés terén: bizonyos dolgokat tök szépen lekezel az UE, de nagy általánosságban nehéz a párhuzamos multi-thread megfelelő leprogramozása. Szóval az UE motoros játékok többsége jelenleg jobban szereti a magas IPC-t, mint a több szálat.
Nézd meg az SW: Jedi Fallen CPU teszteket, az i3-8100 (4 mag / 4 szál) kb. olyan teljesítményt nyújt, mint a Ryzen 5 3600 (6 mag / 12 szál). Az i5-8400 (6 mag / 6 szál) pedig lelépi az R9 3950X-et is...
[ Szerkesztve ]
Légvédelmisek mottója: Lődd le mind! Majd a földön szétválogatjuk.
-

Cathulhu
addikt
[link]
Újabb Epyc win. Ha nem elírás a ~100 db V100, akkor ez egy elég CPU heavy szuperszámítógép lesz.Épp melyik nap hagytak jóvá egy majd 1milliárd fontos angol szuperszámítógép beszerzést, arra is kíváncsi lennék ki nyeri
Ashy Slashy, hatchet and saw, Takes your head and skins you raw, Ashy Slashy, heaven and hell, Cuts out your tongue so you can't yell
-
#2720
Petykemano
veterán
Cathulhu
#2719
Petykemano
veterán
válasz
 Cathulhu
#2719
üzenetére
Cathulhu
#2719
üzenetére
Hogy bánhatja szegény AMD, hogy ehhez nem tud még Arcturust kínálni.
(Bár persze lehet, hogy az Arcturus olyan projekt-termék, amit pont az ilyenekbe próbálnak elsősorban eladni, aztán vagy sikerül vagy nem)Kiváncsi vagyok, hogy ha üzembe áll, vagy legalább elkezd épülni a Frontier, közben, vagy utána lesz-e elmozdulás, vagy továbbra is az nvidia CUDA lesz a nyerő minden ilyen célre.
Tegyük hozzá, hogy a 100db V100 nem egy nagy összeg (~$6000). Nem több, mint $1m.
De 290304 mag, ha 64 magos procikkal számolunk, akkor 4536 és ha a legcsúcsabbat veszik, ami kb $8k, akkor sem jön ki több, mint $35mmondjuk ha a többi alkatrészt is beleszámoljuk, nem tudom, hogy jön ki 3db $71m-ból, de mindegy.
Találgatunk, aztán majd úgyis kiderül..
-
#2721
Cathulhu
addikt
Petykemano
#2720
Cathulhu
addikt
válasz
 Petykemano
#2720
üzenetére
Petykemano
#2720
üzenetére
Az AMD tul kishal a HPC piacon, hogy lehetosege legyen a CUDA ellen tenni, raadasul az sem segit, hogy par evente iranyt valt. Akkor lesz itt erdemi valtozas, ha az intel kartyai erdemi teljesitmenyt tudnak felmutatni, mert akkor hirtelen az intelnek is erdeke lesz a CUDA-t levaltani, mert tud majd egy olyan platformot nyujtani, amit az AMD is akart a HSA-val (OneAPI khm). A helyukben osszefognek es nyilt szabvany melle tennem le a voksot, mert az idovel ugyis gyozedelmeskedik/het es ha eleg nagy a nyomas, akkor az nVidianak is be kell allnia moge, lasd freesync pl. De nyilvan ez utobbinak nem erdeke, ezert tenyleg nagy nyomas kell hozza, amihez az AMD es a Frontier egyedul nagyon keves.
szerk:
"Hogy bánhatja szegény AMD, hogy ehhez nem tud még Arcturust kínálni."
Szerintem ha tudna se erdekelte volna a megrendelot. Nekem az aranyokbol az jon le, hogy viszonylag keves GPU-n futo projekt lehet, azokat meg ugyis CUDA alapon irjak, szerintem.[ Szerkesztve ]
Ashy Slashy, hatchet and saw, Takes your head and skins you raw, Ashy Slashy, heaven and hell, Cuts out your tongue so you can't yell
-
S_x96x_S
őstag
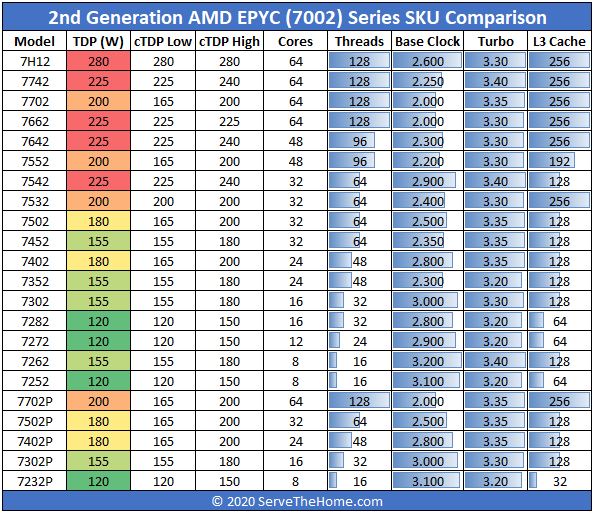
új EPYC :
- 7662 (64c/128t; 225W ) ~ $6650 körül
- 7532 (32c/64t; 200W) ~ $3600Expanding the AMD EPYC™ processor portfolio
https://community.amd.com/community/amd-business/blog/2020/02/19/expanding-the-amd-epyc-processor-portfolio[ Szerkesztve ]
Mottó: "A verseny jó!"
-

#82819712
törölt tag
-
S_x96x_S
őstag
válasz
S_x96x_S
#2722
üzenetére
Az új 32c/64t -es CPU-nál (7532) kimaxolták az L3-as cachet - 256Mb-lett, mint a 64c-é. Lehet, hogy ez is valamilyen összefüggésben van a VMware-es licensz módosítással.
Update: We now have list pricing from AMD “In our standard 1Ku pricing, the 7662 is $6,150 and the 7532 is $3,350.” (Source: AMD)
AMD says that Dell and Supermicro will now offer the two new SKUs while HPE and Lenovo will follow. We requested list pricing and will update this piece when we get it.
https://www.servethehome.com/amd-epyc-7662-and-epyc-7532-launched/
Mottó: "A verseny jó!"
-
S_x96x_S
őstag
Synopsys' Fusion Compiler + AMD EPYC
https://news.synopsys.com/2020-02-19-Synopsys-Fusion-Compiler-Adopted-by-AMD
"
* AMD deploys Synopsys' Fusion Compiler RTL-to-GDSII product for the development of its next-generation processor products
* Unique, single-data-model architecture and unified, full-flow optimization engines deliver superior performance, power and area metricsSynopsys, Inc. (Nasdaq: SNPS) today announced that AMD is deploying Synopsys' Fusion Compiler™ RTL-to-GDSII product for its full-flow, digital-design implementation. Based on an evaluation process, the Fusion Compiler product delivered industry-leading performance, power and area (PPA) metrics. This work has additionally resulted in an expanded collaboration between Synopsys and AMD to optimize Synopsys applications on AMD EPYC™ processors, targeted to deliver marked runtime acceleration benefits when deploying the Fusion Compiler RTL-to-GDSII product across servers powered by AMD EPYC processors. These advancements will be made available to all users in upcoming service packs.
....
"ha jól értem, akkor ez a chiptervezést gyorsítja fel - mindenféle mesterséges intelligenciás és egyéb optimalizációs okoságokkal.
 eddig is partnerek voltak, csak most egy újabb szoftvert is elkezdtek használni ..
eddig is partnerek voltak, csak most egy újabb szoftvert is elkezdtek használni ..spekuláció:
- és lehet, hogy a TSMC N5 (5nm) miatt kellhet? (feltételezem, hogy a ZEN3 tervek már készek)
Synopsys and TSMC Collaborate for Certification on 5nm Process Technologies to Address Next-generation HPC, Mobile Design Requirements
https://news.synopsys.com/2019-09-26-Synopsys-and-TSMC-Collaborate-for-Certification-on-5nm-Process-Technologies-to-Address-Next-generation-HPC-Mobile-Design-Requirementspersze TSMC 7nm-re is van mindenféle segédanyag ( 7FF ; 7FF Plus )
https://www.synopsys.com/dw/emllselector.php?f=TSMC&n=7&s=r3YRJQTSMC - Synopsys Collaboration
https://www.synopsys.com/community/partners/tsmc.html[ Szerkesztve ]
Mottó: "A verseny jó!"
-
S_x96x_S
őstag
válasz
S_x96x_S
#2725
üzenetére
Fusion Compiler ...
The Singular RTL-to-GDSII Digital Implementation Solution
https://www.synopsys.com/implementation-and-signoff/physical-implementation/fusion-compiler.html"Benefits
* Single, integrated data model architecture for unmatched capacity, scalability, and productivity
* Unified RTL-to-GDSII optimization engines unlocks new opportunities for best performance, power, and area results
* Built-in signoff timing, parasitic extraction, and power analysis eliminate design iterations
* Pervasive parallelization with multi-threaded and distributed processing technologies for maximum throughput
* Leading foundry process certified FinFET, gate-all-around, and multi-patterning aware design
"
És az ARM -es új chipek tervezésénél is ezt használták.
( Fusion Compiler on Arm’s Latest Performance-Optimized CPUs )
[ Szerkesztve ]
Mottó: "A verseny jó!"
-
S_x96x_S
őstag
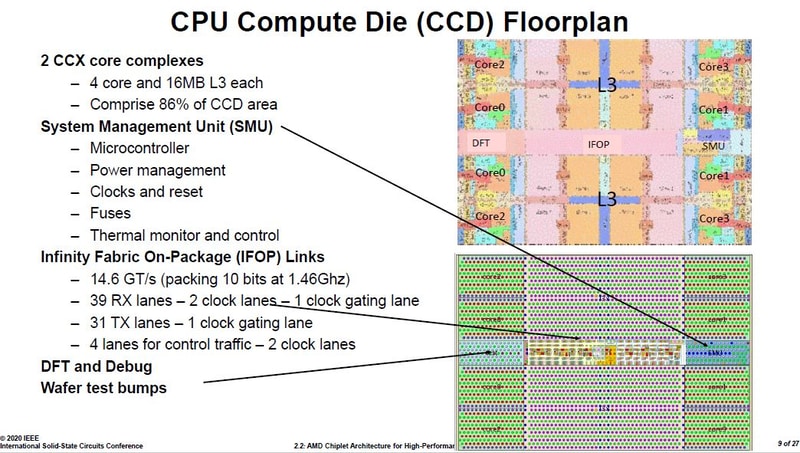
ZEN2-es infók a ISSCC 2020 - konf.-ról. ( 27 angol slide; japán kommentek)
https://pc.watch.impress.co.jp/docs/column/semicon/1236258.html


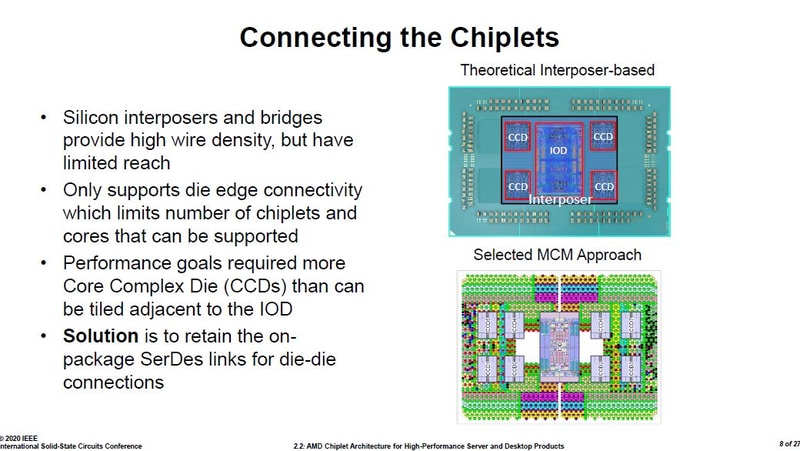
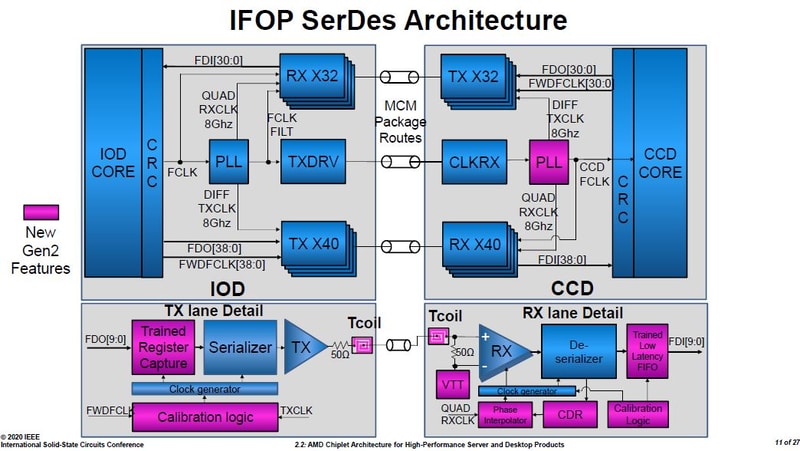
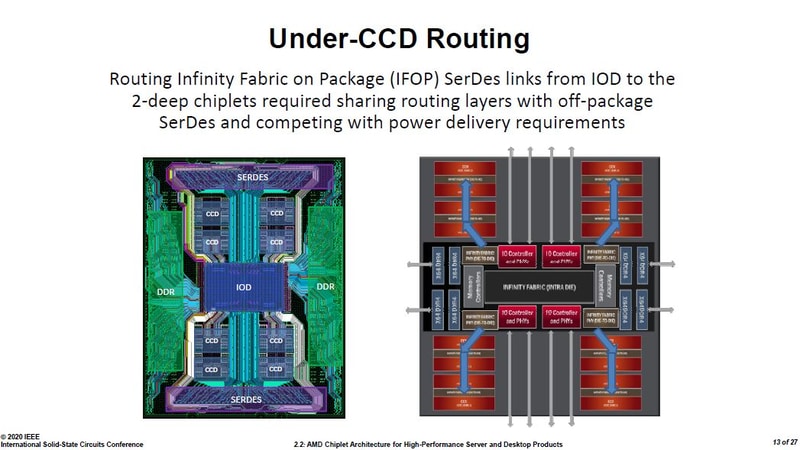
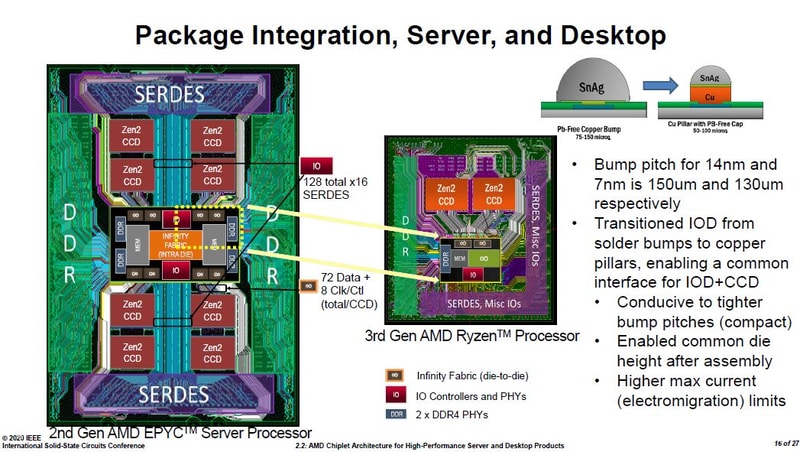
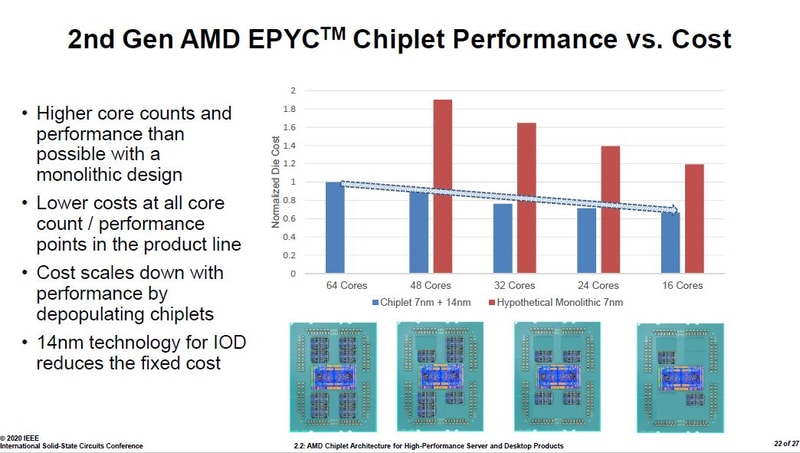
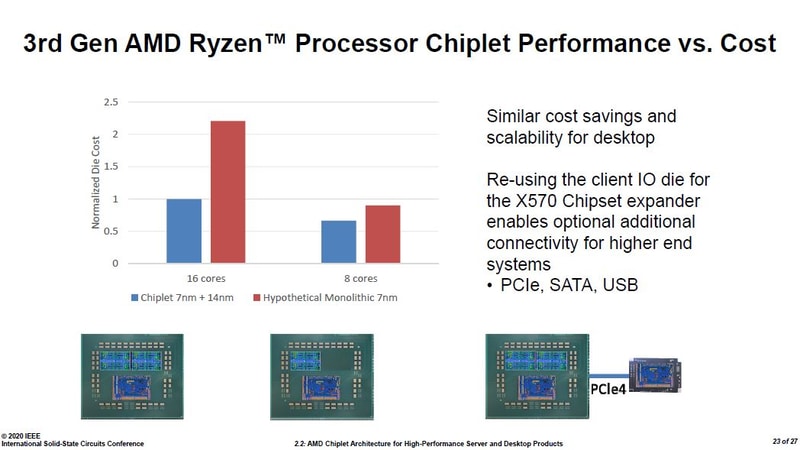
Mottó: "A verseny jó!"
-
#2728
Petykemano
veterán
Petykemano
veterán
Geekbench 5
Google Cloud - n2d-standard
AMD EPYC 7B12
https://browser.geekbench.com/v5/cpu/1257340Találgatunk, aztán majd úgyis kiderül..
-
#2729
Petykemano
veterán
Petykemano
veterán
Úgy tűnik, küszöbön a Comet Lake rajtja
Lesz AMD oldalon áreső? (Már persze a jelenleg is tapasztalható 12-13%-os MSRP-hoz viszonyított kedvezményhez képest)
Találgatunk, aztán majd úgyis kiderül..
-
válasz
Cathulhu
#2719
üzenetére
Itt van egy másik, dupla akkora gép ugyanennek a hétnek a termése:
https://www.computerbase.de/2020-02/hpe-apollo-9000-hawk-supercomputer-24-petaflops-amd-epyc-rome-7742/ -
#2732
S_x96x_S
őstag
Petykemano
#2729
S_x96x_S
őstag
válasz
Petykemano
#2729
üzenetére
> Comet Lake rajtja ... Lesz AMD oldalon áreső?
biztos kell pár helyen igazítani az árakon.
"One of the more interesting duels will likely be between the i5-10400F, which apparently costs $160-$175, and the Ryzen 5 3600 that's priced at $175. Both fighters come with six cores and 12 threads, so it'll be exciting to see which comes out as the winner."
https://www.tomshardware.com/news/intel-10th-generation-comet-lake-pricing-cpusHabár remélem ~április körül - már az új ZEN2-es desktop APU-król is lesz hír. ( 4400G? ) és igazából ezek árazása lesz érdekes ..
Vagyis egy 8c/16t -es APU-t erős Vega-val hova pozicionálnak ;
- mennyivel az Inteles árak felé lesz belőve.
- és mit jelent ez a normál ZEN2-es procik árazására. ( 3700X )Vagyis mennyi lesz az APU-s felár - ugyanannyi magszám esetén.
Mottó: "A verseny jó!"
-
S_x96x_S
őstag
érdekesség; az új z15 (IBM ) maradt 14nm-en és 5.2Ghz + monolitikus design - mindenféle (Gzip?) -es gyorsítással.
és van L4-es cache is.--------------------
IBM z15 ( ISSCC konf. )
https://pc.watch.impress.co.jp/docs/news/event/1236519.html

---------------
Valamit a CEA-Leti 96 core-s 6chipletes proci prototype is érdekes.
512core-ig skálázható!https://www.cdrinfo.com/d7/content/cea-leti-presents-high-performance-96-core-processor-made-chiplets
"The prototype's 96 computing cores are organized in six chiplets in 28nm FDSOI, CMOS node, which are 3D-stacked in a face-to-face configuration using 20µm pitch micro-bumps onto an active interposer embedding through-silicon vias (TSVs) in a 65nm technology node. The overall system architecture offers a fully scalable distributed cache-coherent architecture between all the chiplet computing tiles, which are interconnected through the active interposer. The cache-coherent architecture allows easy software deployment through a hierarchy of caches, for full system scalability up to 512 cores. "
"
[ Szerkesztve ]
Mottó: "A verseny jó!"
-
S_x96x_S
őstag
3990X 128thread skálázódás ..
( ebben a tesztben a "CentOS Stream" a legjobb )
de van kivétel ; ahol meg a FreeBSD ...összesítés:
"Lastly is a look at the geometric mean for all of the benchmarks conducted for this FreeBSD vs. Linux scaling comparison on the AMD Ryzen Threadripper 3990X. In the end, both CentOS Stream and Ubuntu 20.04 (development) delivered similar performance and were basically tied for first. FreeBSD 12.1 performed well and in terms of LLVM Clang 8.0.1 (their default compiler) versus GCC 9, the GNU compiler tended to offer slightly better performance in these particular benchmarks on this AMD Zen 2 HEDT processor."link: https://www.phoronix.com/scan.php?page=article&item=3990x-freebsd-bsd&num=1
Mottó: "A verseny jó!"
-
#82819712
törölt tag
Megjelent a Process Lasso 9.7 verziója - Processor Group Extender
Ez az új algoritmus lehetővé teszi a processzorcsoport számára ismeretlen alkalmazások számára a teljes CPU használatát. Ezt úgy valósítja meg, hogy megfigyeli a célfolyamatok szálait, és szükség esetén dinamikusan hozzárendeli a szálakat a kiegészítő processzorcsoportokhoz.In the case of AMD’s 3990x, for a CPU bound group unaware application with 128 threads, the performance boost would be nearly 100%.
Ez kegyetlen jól hangzik. -
#2736
Petykemano
veterán
S_x96x_S
#2733
Petykemano
veterán
válasz
S_x96x_S
#2733
üzenetére
Érdekes, hogy az ibmnél már a L3$ is eDram.
Kár, hogy nem mondanak.többet erről a 96 magos prototípusról. Persze nyilván itt nem a CPU a lényeg, hanem az aktív interposer, az összeköttetés és a skálázódás.
Ja, meg persze a 3d
Bár ez nekem magyarázatra szorul. Itt 6 lapka van. Ezek vannak 3d stackelve? Vagy arról van szó, hogy egy lapka 8 magos, ebből van 2db 3d stackelve.és ilyen 2x8-as toronyböl van 6?Mindenesetre igen, azt korábbi mérésekből tudjuk, hogy interposerrel Lehetne jelentősem csökkenteni az összeköttetés fogyasztását.
Active interposer lehet egyben IO lapka is. Adoredtv csinált videót a lehetséges topológiákról is.
És hát ez azt is bemutatta, hogy miképp Lehetne megduplázni a magok számát úgy, hogy közben az egész package kiterjedése nem nő.Találgatunk, aztán majd úgyis kiderül..
-
#2737
S_x96x_S
őstag
Petykemano
#2736
S_x96x_S
őstag
válasz
Petykemano
#2736
üzenetére
> Kár, hogy nem mondanak.többet erről a 96 magos prototípusról.
remélem lesz folytatás ..
csak ezt találtam még:
http://www.leti-cea.com/cea-tech/leti/english/Pages/What's-On/Press%20release/CEA-Leti-Presents-High-Performance-Processor-Breakthrough-Active-Interposer-3D-Stacked.aspx-----------
ami még érdekes, hogy a konferencián 2 másik AMD-s előadás mellé tették be.
( Az egyik AMD előadáson ovelockoltak
https://twitter.com/david_schor/status/1229581188928401408 )
----------
A japán oldalon találtam még pár érdekes AMD-vel kapcsolados technikai slide-ot.
pl. Ryzen Threadripper -es ..
https://pc.watch.impress.co.jp/docs/column/kaigai/1223210.html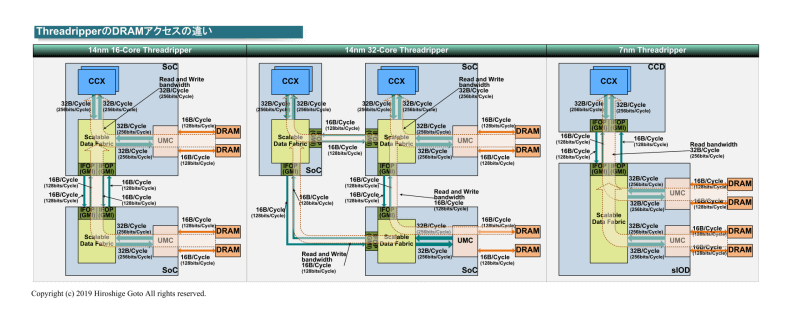
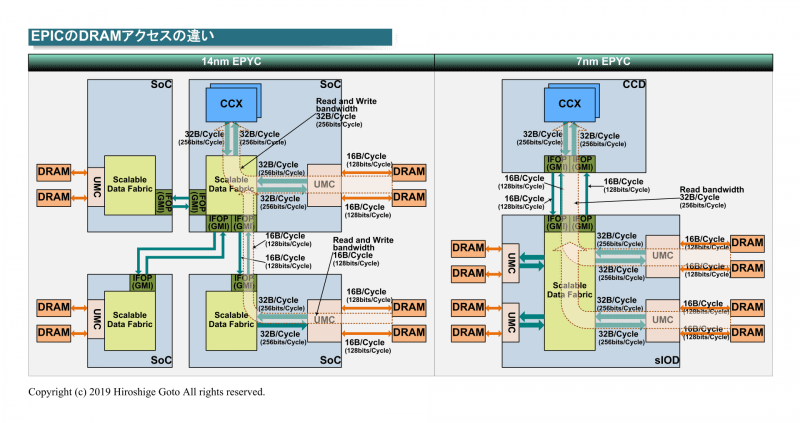
Mottó: "A verseny jó!"
-
#2738
 joysefke
veterán
Petykemano
#2731
joysefke
veterán
Petykemano
#2731
válasz
Petykemano
#2731
üzenetére
Elsősorban azért mert AMD. Egyébként ez a most üzembe helyezett gép Németország leggyorsabb szuperszámítógépe és 5-ik a toplistán.
Nyilván ha intel lenne az az intel hatalmas részesedését a sz.számgép piacon figyelembe véve nem lenne hír.
Egyébként most nyert egy intel alapú pályázat egy német szuperszámítógép tenderen a legnagyobb áramzabáló Xeonokra alapozva. Van némi felzúdulás, "hogy ezt hogyan"...
Erről van szó: https://insidehpc.com/2020/01/intel-powers-hlrn-iv-supercomputer-at-zib-in-germany/
Hát mégis léteznek az 56-magos Xeonok
[ Szerkesztve ]
-
S_x96x_S
őstag
"Demand for AMD's new 7nm EUV processors remains robust, with development projects for the chips commenced by PC, motherboard and graphics card makers this year set to be 10-20% higher than the levels in 2019, according to industry sources."
https://www.digitimes.com/news/a20200221PD207.html
--------
TSMC & STMicroelectronics .. kooperáció a 10x gyorsabb chipek miatt."STMicroelectronics and TSMC are collaborating to accelerate the development of gallium nitride (GaN) process technology and the supply of both discrete and integrated GaN devices to market. Through this collaboration, ST's products will be manufactured using TSMC's GaN process technology, according to the companies."
"GaN is a wide bandgap semiconductor material which offers significant benefits over traditional silicon-based semiconductors for power applications. These benefits include greater energy efficiency at higher power, leading to a substantial reduction in parasitic power losses. GaN technology also allows the design of more compact devices for better form factors. Additionally, GaN-based devices switch at speeds as much as 10X faster than silicon-based devices while operating at higher peak temperatures. These robust and intrinsic material characteristics make GaN ideally suited for broad-based adoption in evolving automotive, industrial, telecom, and specific consumer applications across both the 100V and the 650V clusters."
Ami érdekes, hogy emlitik CEA-Leti -t , akik a 96core-os 6 chipletes procit csinálták.""This cooperation complements our existing activities on power GaN undertaken at our site in Tours, France and with CEA-Leti. GaN represents the next major innovation in power and smart power electronics, as well in process technology," said Marco Monti, president of STMicroelectronics' automotive and discrete Group."
https://www.digitimes.com/news/a20200220PR202.htmlmegj:
- A gallium nitride (GaN) -os technológiát a chipset-es architektúra jól ki tudja használni
( egy adott funkciójú lapot a neki ideálist gyártástechnológián gyártanak )
"The semiconductor material used to make each chiplet is not limited to silicon, which is another chiplet advantage. For example, specialized chiplets could be made from a variety of composite semiconductor materials including SiGe (silicon germanium), GaAs (gallium arsenide), GaN (gallium nitride), or InP (indium phosphide) to exploit the unique electronic properties of these semiconductor materials." ( link PDF )persze a probléma ott van, hogy Kínához köthető a világ gallium termelésének a 95%-a
és az 5G-s termékek is erősen fogyasztják. ( link )És meg kell még említeni, hogy az Intel is elég sok pénzt tol a szilícium alternatívájának keresésébe - vagyis a TSMC is versenykényszerben van.
Intel at IEDM: Stacking Nanoribbon Transistors and Other Bleeding Edge Research
https://www.tomshardware.com/news/intel-at-iedm-stacking-nanoribbon-transistors-and-other-bleeding-edge-researchMottó: "A verseny jó!"
-
#2741
S_x96x_S
őstag
Petykemano
#2740
S_x96x_S
őstag
válasz
Petykemano
#2740
üzenetére
> 7nm EUV ...
lehet, hogy már a ZEN3-ra gondoltak
( és gyártják ? )
de az is lehet, hogy csak elírás.Mottó: "A verseny jó!"
-
#2742
joysefke
veterán
Petykemano
#2740
válasz
Petykemano
#2740
üzenetére
Fene se tudja, lehet az OEM gyártók előre lefoglalnak notebook és szerver chipeket a majdani termékpalettához. Ezt az AMD és TSMC már tényleges keresletként tudja elkönyvelni.
Az intel tavalyi bénázását és jelenlegi szállítási nehézségeit figyelembe véve elképzelhető, hogy néhány gyártó hosszú távra tervezhetővé akarja tenni ez ellástái láncot és nem ad hoc rendelgetni a legkritikusabb komponensből (processzor).
Aztán lehet hogy szimpla elírás és a "sima" 7nm ZEN-ről van szó...
[ Szerkesztve ]
-
S_x96x_S
őstag
éppen emiatt áll a bál .. ( legalábbis a Hacker News-on )
"AMD Threadripper 3970X under heavy AVX2 load: Defective by design?"
https://forum.level1techs.com/t/amd-threadripper-3970x-under-heavy-avx2-load-defective-by-design/153883+ https://news.ycombinator.com/item?id=22382946
-------------------------------------------------------------Wikichip elemzés a már posztolt ISSSCC -előadással kapcsolatban
"7nm Boosted Zen 2 Capabilities but Doubled the Challenges"
https://fuse.wikichip.org/news/3320/7nm-boosted-zen-2-capabilities-but-doubled-the-challenges/
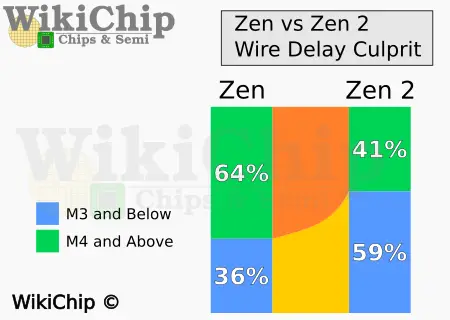
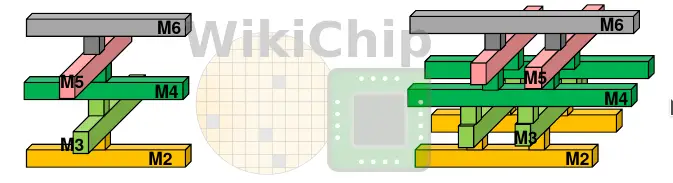
[ Szerkesztve ]
Mottó: "A verseny jó!"
-
S_x96x_S
őstag
durva ... jövőre PCIe 6.0 ... mikor szivárog ez le a mezei ZEN chipekbe ?
kb ~128GB/sec lesz a x16 a sebesség. ( a PCIe4.0 x16 csak ~32GB/sec )
Ez már mintha lenyomná a dual chanel-el DDR4-et .. ( vagy valamit elszámoltam?)-----------------
"PCIe 6.0 Specification Hits Version 0.5: On Track for 2021"
https://www.anandtech.com/show/15540/pcie-60-specification-hits-version-05-on-track-for-2021
Mottó: "A verseny jó!"
-
#2747
S_x96x_S
őstag
Petykemano
#2744
S_x96x_S
őstag
válasz
Petykemano
#2744
üzenetére
> Ez csak TR vagy EPYC is érintett?
nem tudom .. korai még bármit mondani .. akár szoftver bug-is lehet.
Ha komoly, akkor gondolom pár technikai újságiró is teszteli egy héten belül.
valamint az AMD is csinál rá fixet ...A furcsa,hogy nem az eredeti helyen kommentelik. hanem a HN-on aktív ..
Mottó: "A verseny jó!"
-

HookR
addikt
válasz
S_x96x_S
#2743
üzenetére
A második linkeden van egy érdekes, látókör szélesítő komment, remélem nem gond, ha bemásolom:
olliej: "I still don’t understand what it is about avx2 that results in these kinds of issues - is it really just a matter of increased number of execution units running at once causing weird power and heat issues?"
paulmd: "Not increased number of execution units, but increased number of transistors, yeah.
A normal multiply does 1 number at a time (32 bit for simplicity). AVX2 can do up to 8 multiplications at a time. That's a huge amount more transistors firing all at once and that causes the voltage to start to droop.
AVX-512 takes that even further and now it's 16 multiplications per unit, oh and Intel moved from 1x256-bit unit per core on Haswell/Broadwell to 2x512-bit units on Skylake-X, so it's potentially 32 multiplications at a time.
Basically to prep for that much power being drawn all at once, the chip has to wind everything else down and switch to a higher-voltage mode to account for the voltage droop caused by all those transistors switching at once in one place.
At this level behavior is intensively analog and thermals/voltage both significantly affect transistor current draw and switching time, which feeds back into heat and power consumption.
This gets even more problematic on 7nm/10nm type nodes and especially in GPUs where you are doing a huge amount of vector arithmetic all the time. Essentially it is no longer possible to design processors that are 100% stable under all potential execution conditions, or even under normal operating conditions, so you have to have power watchdog circuitry that realizes when it's getting close to brownout/missing its timing conditions and slows itself down to stay stable. That's why AMD introduced clock stretching in a big way with Zen2 (despite the fact that it's nominally been around since Steamroller). NVIDIA piloted this with Pascal, AMD piloted it with Vega and brought it to CPU with Zen2. You simply cannot design the processor to be 100% stable at competitive clocks anymore. You have to have power management that's smart enough to withstand small transient power conditioning faults.
https://semiengineering.com/managing-voltage-drop-at-107nm/
https://semiengineering.com/power-delivery-affecting-performance-at-7nm/ "▌www.thunderbolts.info | youtube.com/ThunderboltsProject ▌16personalities.com▐
-
válasz
S_x96x_S
#2745
üzenetére
A specifikáció lezárása egy dolog, a piacra kerülés egy másik. 2021-ben örülhetünk, ha a 2019-ben lezárt PCI-Express 5.0 megérkezik. Ugyebár a lezárt specifikációkat még be kell építeni a jelenleg fejlesztés alatt lévő CPU-kba, SKU-kba...
Röviden egyébként a "szokásos" előrelépés, vagyis duplázódik a sávszélesség a PCI-Express 5.0-hoz képest és alacsonyabb válaszidő.
Légvédelmisek mottója: Lődd le mind! Majd a földön szétválogatjuk.
-
S_x96x_S
őstag
pice6.0 : igazad van, inkább 2022 .. 2023 ... a várható bevezetés.
> 2021-ben örülhetünk, ha a 2019-ben lezárt PCI-Express 5.0 megérkezik.
Elméletileg az Intel Server fronton ( LGA4677 ) azzal tervez - 2021 -re ( + DDR5 )
persze addig még sok idő.Mindenesetre az AMD-nek szintén meg kell ugyanezt célozni az Epyc -nél
( Desktop szinten már más tészta .. ott lehet, hogy a PCIe4.0 -val még elvannak a felhasználók még egy 1-2 évig. Viszont ha az Intel meglepetésszerűen a desktop szintre is lehozza, akkor az AMD-nek is lépnie kell. )A szerver fronton a CXL és a CCIX ; GEN-Z miatt lényeges a jövőbeli PCIe5.0 megjelenés.
amúgy az AMD túl nyitott lett és ezt a mérnökei szívják meg.
Mert nekik - minden szabványt be kell integrálni a chipjeikbe, ami szerintem szívás.
A CXL mellett ott van a GEN-Z,CCIX,OpenCApi, ... kiváncsi leszek, hogy fogja -e mindet tudni.
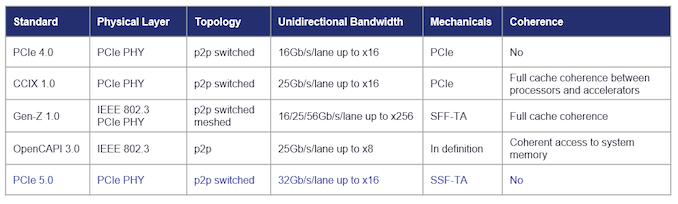
persze egyesek szerint [Gen-Z + CXL] összeolvadásának és túlélésének van a legnagyobb esélye, de az is lehet, hogy minden ötletet a CXL következő verziójába integrálnak be.
egyre nagyobb a lista:
https://www.computeexpresslink.org/membersCXL erőteljes ütemű PCIe6.0 bevezetést vár
"CXL usages expected to be key driver for an aggressive timeline to PCIe 6.0"
ajajj .. hamar el fognak avulni a gépek .. lehet frissíteni.
Mottó: "A verseny jó!"








![;]](http://cdn.rios.hu/dl/s/v1.gif) ...
...







 eddig is partnerek voltak, csak most egy újabb szoftvert is elkezdtek használni ..
eddig is partnerek voltak, csak most egy újabb szoftvert is elkezdtek használni ..



 "
"




