- Alternatív kriptopénzek, altcoinok bányászata
- Újabb államok perelik az Apple-t, mert sok pénzt szed ki a vevőkből
- Windows 11
- SUSE Linux
- Meggyőző arcjátékkal reagál a kínai humanoid robot
- Milyen routert?
- Telekom otthoni szolgáltatások (TV, internet, telefon)
- Otthoni hálózat és internet megosztás
- Max
- Béta iOS-t használók topikja
-

IT café
A legtöbb kérdésre (igen, talán arra is amit éppen feltenni készülsz) már jó eséllyel megtalálható a válasz valahol a topikban. Mielőtt írnál, lapozz vagy tekerj kicsit visszább, és/vagy használd bátran a keresőt a kérdésed kulcsszavaival!

Új hozzászólás Aktív témák
-

Abu85
HÁZIGAZDA
A felskálázás az jó dolog, de igazából egyik megoldás sem jó. Az a baj, hogy rohanunk az olyan marhaságok felé, mint a képgenerálás, ami olyan eszetlen hülyeségeket eredményez, hogy kész képkockákat tartunk vissza a megjelenítéstől. Ez őrültség.
De a jelenlegi felskálázások nem tökéletesek. Mindegyikkel az a gond, hogy a probléma egyik felét oldják meg. Mert a brute force AI megoldás nem elég, ugyanis nem tud reagálni olyan dolgokra, amelyekkel nem lett a tréning alatt feldolgozva, míg a másik oldalon a kézzel írt algoritmusok szintén nem számítanak elégnek, mert azok meg nem reagálnak elég hatékonyan a dolgokra. Ezek kombinációja lenne a megoldás, vagyis egy olyan algoritmus, ami alapból kézzel van írva, emberi tényezővel, és azt kiegészíti az AI brute force. De valamiért nem érdekeltek benne a cégek, pedig ez ütne igazán. De helyette van ez a képgenerálos marhaság.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
Ez egy szoftveres probléma, ami minden NV GPU-t érint, hiszen szoftverből ered. Ha ez nem lenne, akkor gyorsabb lenne az az RTX 3060 még 13100 mellett is, de a szoftverben az emulációs réteg nem hagyja, hogy a hardver gyorsabb legyen.
#60151 bjasq99 : Igazából ez nem driverhiba. Egyszerűen maga az implementáció a bekötéshez processzort igényel, míg az AMD implementációja a bekötést a proci nélkül is meg tudja csinálni. Értelemszerűen utóbbi nem okoz többletterhelést, mert nem is nyúl a procihoz.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
válasz
 bjasq99
#60155
üzenetére
bjasq99
#60155
üzenetére
Teljesen valid a felvetés, és egyébként már most is lehet ilyet csinálni, az FSR2 ugyanis etethető extra adatokkal, ami pont azokra a helyzetekre van, ahol ezek a felskálázók csődött mondanak az általános jellegük miatt.
[link] - az UE4-re ez bővebben ki van fejtve.
Valószínűleg idővel elmegy mindegyik felskálázó abba az irányba, amerre ment az FSR2, hogy extra adatokkal javítható a működés. És akkor az általános rendszer specifikusan konfigurálhatóvá válik. Az AMD itt előreszaladt, mert az irány egyértelmű, bizonyos helyzetekre sosem fognak tudni reagálni az általános megoldások, így ezekre külön kerülőutak kellenek.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
#60205
Abu85
HÁZIGAZDA
Petykemano
#60161
Abu85
HÁZIGAZDA
válasz
 Petykemano
#60161
üzenetére
Petykemano
#60161
üzenetére
A grafikai problémák nagyon kis része általános annyira, hogy fixfunkciós blokkot legyen értelme építeni rá.
Az RDNA3-ban van WMMA.
#60172 b. : Mivel az FSR2 később készült, így az AMD tudott reagálni olyan dolgokra, amiket a DLSS2 elemzése kapcsán láttak. Például arra a tényező, hogy bizonyos objektumok esetében a mozgásvektorok írása tilos lehet, és ha ez tilos, akkor nem tud velük mit kezdeni a felskálázó. Tehát szükséges egy alternatív módszer az adatok felhasználására. Ezt majd minden felskálázóba be kell építeni, mert maga a probléma általánosan nem kezelhető.
Most még nem tartunk ott, hogy ezzel sokan foglalkoznának, mert berakják a rendszereket általánosan, de a jövőben igazából sokkal több értelme lesz annak, hogy csak az egyiket kiválasztják, és azt extra adatokkal etetve, specifikusan az adott leképező problémáira átgyúrva alkalmazzák, ezzel söpörve le minden általánosra tervezett megoldás képminőségét. Mert valójában még mindig előnyösebb a specifikus technika, mint az általános, mert nem általánosan reagálsz a tipikus problémákra, hanem a te leképeződ saját specifikus gondjait kezeled vele.
#60192 bjasq99 : A metszésvizsgálat mindenképpen fixfunkciós marad. Annak emulációjának nincs előnye, mert ezen a ponton nem igazán van szükséges programozhatóságra.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
#60218
Abu85
HÁZIGAZDA
Petykemano
#60216
Abu85
HÁZIGAZDA
válasz
Petykemano
#60216
üzenetére
A Hogwarts Legacy-ra már október óta van profil az NV és AMD driverekben. Valószínűleg frissítésre szorul, de már régóta ott van. Egyszerűen csak elfelejtették megemlíteni, amikor kiadták a drivert. Persze aki nem érti, hogy miképpen működik ezek fejlesztése, az azt hiszi, hogy jaj nincs profil, mostmilesz...

Nagyon sok profil az AMD-nél nem is változik a megjelenésre. Például a Call of Duty: Modern Warfare II profilját október végi meghajtóban említették meg, de változatlan formában ott van tavasz óta.
Az NV és az AMD nem úgy dolgozik, hogy csak az utolsó pillanatban rakják be a profilokat. Az AMD-nek már a Starfieldre is van profilja az idei meghajtóban, oszt mikor jön az még...
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
Ezúttal nem teljesen a driverről lehet szó. A játék nem tipikusan CPU-limites, inkább klasszikus vegyeslimites. Tehát van némi köze az NV driver magasabb bekötési overheadjének hozzá, de nem felel önállóan érte. A nagyobb probléma a memóriaallokáció, ugyanis az elég szimpla lineáris allokáció, amit valamiért virtuális allokációk egészítenek ki. Nem tudni, hogy miért, talán sok a leak? Na most a virtuális allokációk a GeForce-okon jellemzően nem túl jó ötletek, mert hét zéróflages type van a RAM memóriahalmazában, és ha a motor tipikusan jól skálázódik, ahogy egyébként az Avalance szokott, akkor a zéróflagek miatt extra memóriamásolások érzékelhetők lesznek a GeForce-ok mellett a rendszermemóriában, ahogy ugye a zéróflages type-okból valós flages type-okba kerüljenek a CPU-nak szükséges adatok. Ez nyilván extra többletterhelés a procinak, és persze érződni fog a kisebb felbontásokon.
Alapvetően ahogy működik maga a szoftver, az nem túl optimális az NV memóriafelosztásának. Ha másképp működne a memóriamenedzsment, akkor kisebb felbontáson is gyorsabbak lehetnének a GeForce-ok, meg valószínűleg annyi memóriát se zabálna. Tehát ez nem egy tipikus driveres limit.
Őszintén szólva a lineáris allokáció az ilyen "ússzuk meg egyszerűen" a dolgot. Nem mondom, hogy baj van vele, mert működik, de ma már azért jóval jobb megoldások is vannak. És meg sem kell írni, elég letölteni a D3D12MA-t.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
GI-ra lesz egy nagyon gyors szabvány RT alternatíva idén. Szóval attól, hogy az NV a saját megoldását nem fejleszti tovább, a piac még kap alternatívát. Ráadásul háromszor gyorsabban fut. Lehet, hogy ezért nem erőlteti az NV a sajátját, mert minek, ha sokkal gyorsabb is jön helyette.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
#60257
Abu85
HÁZIGAZDA
Petykemano
#60255
Abu85
HÁZIGAZDA
válasz
Petykemano
#60255
üzenetére
Nem mindegyik modellből lesz valós termék.
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
válasz
bjasq99
#60317
üzenetére
Mert csak kiemel hívásokat, de nem csak ennyi a grafikai feldolgozás. Az L2 legnagyobb terhelői a ROP-ok, mert azok az L2 kliensei a modern GPU-dizájnokban (a Maxwell és a Vega óta). A legnagyobb L2 terhelés is innen érkezik, hiszen messze ezek mennek a legnagyobb adamennyiségért a memóriába. Az persze tök jó, hogy a kb. 8 kB-os memóriaigényű shaderek jó hitet érnek el az L2-ben, de a ROP-ok már nagyon nem, és ezek felelnek az L2 adatmásolások legalább 98%-áért. Ezért épített az AMD Infinity Cache-t a lapkákba akár 100 MB-ot, mert az egyszámjegyű megabájtos L2-t teljesen kiheréli a ROP. Alig van cache hit benne a lapok cseréjével. De ez így normális, egyszerűen túl sok adat mozog túl aprócska gyorsítótárban.
#60318 b. : Az Infinity Cache csak egy védőháló, ami felfogja a kidobott L2 lapokat, amelyek kellhetnek még a ROP-nak. Ezt nem lehet program oldaláról befolyásolni, így értelmetlen lenne láthatóvá tenni. De van egy kulcs hozzá, ami megmutatja, csak ahhoz nem elég developer módba kapcsolni a drivert. Szükséges a support mód is, azt meg csak a kiemelt fejlesztők kapják meg.
#60320 b. : A CPU-limiten az tudna javítani, ha nem emulálná a bindlesst az NV driver. Ez egy szoftveres probléma, nem hardveres. Amikor kidobják az összes hardver támogatását az Ampere-ig, akkor át tudják írni a drivert bindlessre, de ehhez előbb meg kell szüntetni a Maxwell, a Pascal és a Turing terméktámogatását.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
válasz
 Raymond
#60322
üzenetére
Raymond
#60322
üzenetére
Én meg hosszabban, hogy érthető legyen. A GPU egy heterogén multiprocesszor. Van egy rakás különböző féle-fajta részegység benne, amelyek írják/olvassák a megosztott L2-t. Compute shader esetén viszonylat sok értelme van az L2 cache-nek, mert elég jó hit rate érhető el. Akár sugárkövetésnél is van értelme az elsődleges sugaraknál, mert azok koherensek. Másodlagos sugaraknál már ez megszűnik, így ott már az L2 cache nem igazán ér semmit. A BVH esetében is van némi értelme. Ezek mind olyan feladatok, amelyekben elég nagy hit rate érhető el. De vannak emellett olyan feladatok is, amelyekben nem olyan jó. Persze a tile-alapú leképezés segít, de valójában a ROP blokkok egy rakás gyorsítótársorral dolgoznak. Ezek egy része az L2-be kerül, de ugye ennek kapacitása véges, így idővel a VRAM-ig kell menni. Ebből a szempontból az L2 sosem volt jó, mert nagyon alacsony a hit rate. Ezért van a GPU-kon olyan brutál széles busz, meg gyors memória, mert ezt az alacsony hit rate-et kompenzáljuk vele. A másik opciója ennek ugye az Infinity Cache, ami védőhálóként felfogja az L2-ből helyhiány miatt kidobált gyorsítótársorokat, és esélyes, hogy a ROP blokk megtalálja őket az Infinity Cache-ben, nem kell elmenni a VRAM-ig. De ehhez elég nagy gyorsítótár kell még, és teszem azt 128 MB-nyi gyorsítótárral is csak 50% körül van a hit rate a Navi 21 esetében 4K-s felbontáson. Képzeld el azt a szegényke 4 MB-os L2-t. Ilyenre szintén volt az AMD-nek anno mérése, és 8 MB-os cache esetében van 10% környékén a hit rate. Persze a cache felépítése is fontos, például az RDNA 3 jobban használja az Infinity Cache-t, de itt nem drámai a különbség. Az AMD szerint nagyjából olyan hit rate van 96 MB-os IC-vel a Navi 31-en, amilyen 128 MB-os IC-vel a Navi 21-en. Tehát a strukturális háttér fontos, de annak javítása nem okoz drámai előnyt, azt az extra kapacitás hozza.
#60324 GeryFlash :
1) Az NV-nek ez a CPU-limites dolga egy nagyon specifikus tényező. Nem minden játékot érint, mert bizonyos dolgok szükségesek ahhoz, hogy előjöjjön. Például az, hogy a Microsoft és ne az NV ajánlásait kövesse egy fejlesztő a D3D12 leképező írásakor. Mert ugyan a D3D12-ben mindkét cég utazik, de több helyen homlokegyenest ellenkező dolgot ajánlanak.
2) Azért raknak bele több cache-t, mert heterogén multiprocesszorok a GPU-k. Attól, hogy a ROP-ok hit rate-je nem túl jó, még a compute feladatoké jellemzően az. Csak ugye egy játékban döntő tényező a ROP, tehát ez rontja a működést.[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
#60340
Abu85
HÁZIGAZDA
bitblueduck
#60339
Abu85
HÁZIGAZDA
válasz
 bitblueduck
#60339
üzenetére
bitblueduck
#60339
üzenetére
Drága. Bonyolult NYÁK kell hozzá, és az árnyékolása sem egyszerű ezekkel a gyors memóriákkal. Amúgy nyilván mérnökileg kivitelezhető, de ha van hova menekülni előle, akkor inkább menekülnek a gyártók egy másik megoldás irányába.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
válasz
bjasq99
#60343
üzenetére
Ennél egy kicsit bonyolultabb. Például az AMD specifikusan ment bizonyos adatokat. Az L0 elsődleges feladata a textúrázók és az RT egységek kiszolgálása, és emiatt elég jó lesz a hit rate, mert jellemzően jól cache-selhető koherens adatelérésekről van szó. Az L1 cache már jóval univerzálisabb, az már számos olyan munkafolyamatra is vonatkozik, ami nem jól cache-selhető. Ezen túlmenően sok adat közvetlenül az L2-be lesz kiírva a multiprocesszorból. Tehát az L1 cache rossz hit rate-je attól van, hogy olyan adatok kerülnek bele a mögötte lévő memóriákból beolvasva, amivel nem mindig lehet jó hit rate-et elérni.
Az L2-nél sok múlik azon, hogy az AMD mennyire épít az IC-re. Mert amíg régebben muszáj volt ebből kiszolgálni a ROP-ot, addig manapság már építhetnek arra, hogy van egy védőhálójuk, ami ugyis felfogja a szükséges gyorsítótársorok egy részét, tehát nem muszáj az L2 cache nagy részét rosszul cache-elhető ROP műveletekre használni.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
Mit nevezünk next-gennek? Mert amúgy nem tud kevesebbet az IW9, mint a többi aktuális motor.
#60504 b. : Nem épít be nagyon gyártóspecifikus eljárásokat az Epic. Az UE5 esetében arról van csak szó, hogy magát a motort AMD hardveren tervezték. Egyszerűen tanultak abból a problémából, ami az UE4 kapcsán előjött, hogy voltak teljesítménygondok, majd amikor elkezdték Radeonon tesztelni a rendszert, akkor hirtelen láthatóvá tette a nyomkövető a bugokat, amiket a korábbi teljesítményszámlálós profilozók nem is mutattak. Emiatt hasznosabb alapjaiban Radeonon tervezni manapság a motorokat, mert az alapvetően általános teljesítményproblémák okát több nagyságrenddel egyszerűbb megtalálni. Ez nem az NV ellen megy, ők is előnyt szereznek abból, hogy az AMD fejlesztőeszközeivel meg lehet keresni a motor rejtettebb bugjait.
Eleinte egyébként ez vezethet oda, hogy a kezdeti kód jobban megy Radeonon, mert nyilván nem mindegy, hogy egy évet optimalizáltak valamire, vagy csak egy-két hónapot. De ez idővel kiegyenlítődik, ahogy a többi rendszerbe is belerakják az időt.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
Attól függ csak az előny, hogy miképpen használod a motort. A Radeonok akkor szoktak előnybe kerülni az UE 5-ben, ha sok a rajzolási parancs. De ez valószínűleg nem a motor miatt van így, hanem az AMD-féle D3D12 meghajtó hatékonyságából származik.
A Unity 5 az nem hiszem, hogy érdekes lesz, mert az kb. 7 éves.

[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
válasz
 paprobert
#60510
üzenetére
paprobert
#60510
üzenetére
Bármelyik motor képes futni PS4-en is Xbox One-on. Ez nem egy technikai kérdés, mert maguk a konzolok képességei megfelelnek egy bizonyos technikai színvonalnak, és tök egyszerű leskálázni rá a terhelést. Nem azért nem csinálják meg, mert lehetetlen, hanem azért, mert anyagilag már nem éri meg a régi gépekkel foglalkozni.
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
válasz
paprobert
#60515
üzenetére
Miért ne tudna futni? Az egész csak skálázás kérdése. Ami működik PS5-ön, az leskálázható bármikor PS4-re is. Ezt bármelyik motorral meg lehet tenni. Nem technikai limit, amikor nem teszik meg, hanem egy döntés kérdése. A döntés pedig attól függ, hogy akarnak-e erőforrást fektetni bele, hogy futtatható legyen. Ha igen, akkor még az Unreal Engine 5 is menne PS4-en és Xbox One-on.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
válasz
 T.Peter
#60522
üzenetére
T.Peter
#60522
üzenetére
Mert amúgy manapság a next-gen az AI-ról és a rombolhatóságról híres?
A legfőbb előnyt az új gépek ott adják, hogy jobb lehet az assettek minősége, mert gyorsabb a dekódolásuk. De az assettek skálázhatók, és innentől kezdve előállítható az a minőség, ami pont jó a régi gépeknek.
#60521 Busterftw : Ezért kell skálázni a grafikát.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
Mármint az NVIDIA jelenlegi megoldásaival számolódik csak annyi, de ez nem jelenti azt, hogy ne lennének ennél gyorsabb megoldások, amelyekkel jóval több fényforrás kezelhető. Nem érdemes általánosítani az egész iparra az NVIDIA saját eljárásainak limitjeit.
Az, hogy az NVIDIA ezeket a limiteket úgy oldja meg, hogy inkább eltávolodik a GI-tól, és helyette a DI-t erőltetik, még nem feltétlenül jelenti azt, hogy mindenki így tesz. A DI arra jó, hogy jobban skálázható rendszered legyen, de ennek az ára az, hogy kevésbé lesz jó a minősége, illetve sokkal többet kell vele dolgozni, mint a GI-jal. A valós idejű jelenetszintű GI eljárások fő előnye, hogy nagyjából just works jellegűek. Berakod és egy-két nap alatt működik, míg a DI-on heteket-hónapokat kell dolgozni, mire jó eredményt kapsz mindenhol.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
válasz
 Busterftw
#60541
üzenetére
Busterftw
#60541
üzenetére
A Crytek megoldása azért volt gyors, mert nem kötötte egyetlen DXR limit sem. A mai megoldások nagyrészt azért lassúak, mert maga az API rendkívüli mértékben limitál.
#60542 T.Peter : Biztos lesz olyan, aki egyszerre alkalmaz RTXGI-t és RTXDI-t. Mert ugye épphogy az egyikre van erőforrás az API limitjei miatt. Mindkettő együtt biztos hasznos lesz. Amúgy, ha van jó minőségű GI-od, akkor nincs szükséged DI-ra.
#60543 b. : Az AMD GI megoldása teljesen más algoritmust használ, mint bármi eddig. A mai megoldások legnagyobb limitje, hogy vagy gyorsak, de gyenge minőségűek, vagy lassúak, de jó minőségűek. Ezzel küzd mindenki. Az NV is ezért hozta az RTXDI-t, mert egyszerűen az RTXGI eljárásuk nem elég gyors, viszont az RTXDI az gyors, de nem mentes a leakektől, illetve az RTXGI-jal ellentétben pre-processinget igényel. Az AMD inkább azon dolgozott, hogy megőrizze a GI minőségét, miközben a teljesítményét felhozza használható szintre. Így ők egy olyan eljárást hoznak, ami mentes a leakektől, és nem igényel pre-processinget. Tehát a minősége az RTXGI kaliberű, de újszerű cache-mechanizmust alkalmazva a sebessége kétszer-háromszor jobb. Emiatt az AMD nem is gondolkodik DI alternatíván, mert nekik jóval gyorsabb a saját GI algoritmusuk, így számukra nem kell rosszabb minőségű, nehezebben alkalmazható alternatív technika. Nem lenne értelme, mert nem tudnak annyit nyerni vele, mint az NV, ugyanis már eleve sokkal gyorsabb a saját GI-juk. Az NV-nek ez realitás, mert egy RTXGI-nál kb. háromszor gyorsabb RTXDI-ért megéri sokkal többet dolgozni a program oldalán, de az AMD mennyit nyerne vele? +20%-ot? Annyiért nem éri meg több hónapnyi munka, miközben a saját GI-juk elég jó sebességet ad pár napnyi melóval. Senki sem fog +20%-ért hónapokig gürcölni.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
Az AMD GI eljárása teljesen szabványos, csak DXR-t használ. Abban különbözik az NV RTXGI eljárásától, hogy bevezet egy olyan gyorsítótár-hierarchiát, ami cache-sel bizonyos adatokat, hogy ezek később felhasználhatók legyenek. De maga a sugárkövetés része az ugyanaz, csak nem olyan brute force megoldás, mint az RTXGI, hanem próbálnak belevinni egy kis észt, hogy sokkal gyorsabb legyen. És ez konkrétan mindenen gyorsabb, mert magából a caching algoritmusból szerzi a sebességet. Emiatt az AMD-nek tök felesleges egy DI alternatíva, mert ők már GI-ból hozzák a sebességet, ugyanis nem rossz hatékonyságú brute force alapon dolgozik a technikájuk.
Várható volt, hogy valaki előáll majd valami hasonlóval, mert a brute force sosem volt kifizetődő. Csak idő kell, amíg az ésszel dolgozó megoldásokat kifejlesztik.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
Az NV leírása szerint az RTXGI egy probe-alapú adatstruktúrát használ, ami valós időben kezeli a fény- és távolságadatokat. Ennél vannak jobbak is, például a reservoir-alapú újramintavételezési technikák, de ha teljesítményt is akarsz, akkor még jobb kell, és leginkább ott van értelme javítani, ahol ezek a meglévő technikák a brute force miatt csődöt mondanak, leginkább a meglévő adatok újrafelhasználhatóságában.
Az RTXDI az nem is GI technika. Nyilván megközelítőleg sem fog olyan minőséget adni, mint egy globális illumináció. Ha adna, akkor ma senki sem használna GI-t, mert elég lenne a szimpla DI. Ráadásul a DI esetében nem is annyi az egész, hogy berakod a játékba, mert a direkt illumináció miatt rengeteg pre-processinget igényel. Tehát hiába működne jól maga a technika, ha nem szánod rá a több hónapot, hogy minden jelenetben jól beállítsd, akkor nem ér majd semmit. A GI ezért jobb, mert arra nem kell rászánni az időt. Azt csak berakod és működik.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
Az NVIDIA sosem volt erős ezekben az effektekben. Lásd Gameworks. Komoly félrefejlesztésük is volt, lásd VXGI. Nem azért ők a legnagyobb GPU-gyártó cég, mert jól tudnak effekteket írni, mert valójában messze ez a leggyengébb képességük. Az Intel is jobban teljesít náluk itt. Viszont a piacon nem ez a döntő tényező.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
A zártság önmagában azt jelenti, hogy nincs jól megvalósítva, mert nem tudod átírni a hibáit. Például a Hairworkshöz azért nem tudtad hozzáadni a jó minőséghez szükséges OIT-t, mert nem volt nyílt forráskódú. Ha nyílt lett volna, akkor ki lehetett volna javítani a jelentős dizájnhibáit. Az RTXGI is átírható lenne, ha megadná az NV erre az engedélyt. Nyilván egyszerűbb lenne a fejlesztőknek kijavítani a hibáit, mint nulláról fejleszteni valamit.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
#60560
Abu85
HÁZIGAZDA
bitblueduck
#60558
Abu85
HÁZIGAZDA
válasz
bitblueduck
#60558
üzenetére
Az NVIDIA önhatalmúlag itt nem járhat el. Nyilván a nyílt forráskód miatt bárki beépítheti az AMD rendszerét, akár az NV is, de az AMD engedélye nélkül az NVIDIA nem említheti meg a céget.
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
válasz
 #32839680
#60624
üzenetére
#32839680
#60624
üzenetére
Nem az a bug, hogy max órajelen pörgeti a VRAM-ot, hanem az, hogy magasabb az idle fogyasztás a normálisnál több kijelzővel. És ez egy tényleg létező bug a 7000-es sorozatnál, ugyanis a mostani meghajtókkal nagyjából +4-8 watt többletet mér az AMD is a hitelesítési tesztekhez viszonyítva. De nem attól, mert magas az órajel, hanem attól, mert valami bug miatt van pár extra memóriamásolás. Mivel ehhez újra kell írni pár dolgot a meghajtóban, így ezt később fogják megoldani, és akkor nagyjából 4-8 wattot csökken is majd a fogyasztás.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
Tudok erről. Ezzel konkrétan az a bajuk, hogy nem tudják reprodukálni. Pedig már ezres nagyságrendő mintán dolgoznak, de nem tudják előhozni a hibát a laborban. Volt olyan, akitól bekérték a kártyát, de arról kiderült, hogy maga a hardver volt hibás, azzal meg ugye nem tudnak szoftveresen mit kezdeni, arra a gari van.
Az fontos, hogy ha valamit beírnak a know issues részbe azt már reprodukálták. Minden hiba, ami jelentve van, de saját részről nem sikerült reprodukálni, nem kerül be a know issues közé.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
Igazából a usereknek kell változtatniuk azon, hogy nem elég a fórumba beírni. Ott van a report tool a drivernél. A driveres csapat csak azt nézi. A fórumot nem. Ha valaki jelent valamit a legfrissebb driverrel, akkor arra kap választ. És ha olyan válasz érkezik, hogy vigye garira a hardvert, akkor ne várjon tovább, mert azért küldik azt a választ, mert saját laborban nem tudták előhozni a hibát.
Az NVIDIA is szenved olyan fórumban jelentett hibáktól, amiket nem tudnak reprodukálni. Egyszerűen hiába próbálják, nem jön elő az, ami a usereknél. Ez tök normális jelenség. Eladnak ezek a gyártók havonta milliós nagyságrendő hardvert, és 10-20 user beír xy hibát a milliós eladott mennyiségre. Megnézik, ha tényleg jelentve lesz, de az esetek egy részében hardverhiba az ok.
Ezek a típusú dolgok olyanok, mint most a Diablo 4 esete, ami állítólag megfőzött két GeForce-ot, és mindenki pánikol. De vajon nem romlottak volna el amúgy is azok a VGA-k? A user nem tud nagy tételben gondolkodni. Nem érti, hogy két halott VGA az nem sok, ha milliók játszanak.[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
#60649
Abu85
HÁZIGAZDA
bitblueduck
#60648
Abu85
HÁZIGAZDA
válasz
bitblueduck
#60648
üzenetére
Ezek a dolgok teljesen kiegyenlítik egymást, mert ide-oda menekülnek a userek. Aztán idővel megunják és vesznek konzolt.
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
válasz
 GeryFlash
#60650
üzenetére
GeryFlash
#60650
üzenetére
Egy helyen lehet jelenteni bugot. Ott a driverben a report tool. Egy gombnyomás. Ha nem ott teszik, akkor az user error.
#60652 fatal` : A rendszer csak azokat a reportokat engedi át, ami a legfrissebb driverből megy. Ezért minden report előtt szükséges a friss driver telepítése.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
válasz
GeryFlash
#60656
üzenetére
Ha a monitoros problémáról van szó, akkor azt írtam, hogy az AMD nem tudja reprodukálni. Azért nincs még benne a know issues részben. Hiába van róla fórum, ha a laborban két hónapja nem tudják előidézni. Ha a segged vered a földhöz, akkor sem lehet ezt gyorsabban csinálni, mert van kb. 10-20 ember, aki erre panaszkodik a fórumban, ebből talán 5 hivatalos formában is ír, amit felvesznek, és keresik az okát, de annyira extrém ritka kb. 5 jelentés több millió eladott hardverre vetítve, hogy valami nagyon eldugott valami lehet, ha nem azzal a pár hardverrel van baj ténylegesen. Akinél megtalálták, annak hardverhibája volt, és a gari oldotta meg.
A report tool egyébként pont arra van, hogy ott az AMD felvesz egy rakás adatot. Például a teljes konfig paramétereit, BIOS verziókat, OS-t, stb. Ezt a szoftver összegyüjti, így ha x hardverrel nem is találják a hibát, össze tudják rakni pontosan ugyanazt a konfigurációt, pontosan ugyanazzal a szoftveres háttérrel. De egy fórumon erre mekkora az esély? Az se biztos, hogy a user jól adja meg az adatokat. Emiatt nem foglalkoznak a cégek a fórumbejegyzésekkel. Csak az időt viszi, de nem segít.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
-
Abu85
HÁZIGAZDA
A DirectStorage az csak ront a memória problémáján, mert a GPU-s dekódolás miatt nem csak a dekódolt textúrákat kell tárolni, hanem a kódoltakat is. Tehát az lehet, hogy ez a technika gyorsabb betöltést és jobb streaming képességeket biztosít, de ennek az ára, hogy jobban zabálja majd a VRAM-ot.
Ezen egy olyasmi módszer segítene, hogy lenne egy API a lapalapú menedzsmentre, hogy ne teljes nagy allokációkat, hanem szimplán 4 kB-os lapokat mozgasson a rendszer. De ez PC-n nincs csak konzolon.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
Az AMD inkább a FidelityFX Brixelizert fejleszti. Ennek a lényege, hogy a mostanihoz hasonló RT effektek 3-4-szer gyorsabban is kiszámolhatók lesznek. Az FSR 3 meg majd gyün, de annyiban nem fog különbözni a DLSS3-tól, hogy használhatóbb legyen, szóval ugyanaz a fos generálás lesz tele hibával és plusz késleltetéssel. Úgy meg minek?
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
Ahogy csinálják ez normális lehet, hiszen a mostani RT problémája az, hogy fos az API működése. Ha SDF-et használnak, akkor az bőven gyorsabb ennyivel, mert pont kikerüli azt a részt, amiben a DirectX Raytracing iszonyatfos, és ez a rész okozza azt, hogy sokkal több erőforrást zabál a rendszer, mint amennyit amúgy kellene.
Többször írtam már, hogy a mostani DXR brutálisan korlátozott, mert iszonyatosan sok limitet generál, amit nem lehet kikerülni. Technikailag ezt az AMD sem tudja, de át lehet ugrani, hogy megszabadulj ezektől a limitektől.
Például a Dreams című játék pont azért használ SDF-et a PS4/5-ön, mert nagyon gyors lehet az eredmény. Csak PC-re ezt soha senki nem csinálta meg. Most lényegében ez lesz a Brixelizer.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
Itt ez nem arról szól, hogy min jó és min nem. A probléma az, hogy a DXR egy zárt konstrukció, amit nem lehet kiismerni. És amíg különböző licencproblémák miatt ezen nem változtat a Microsoft, addig szar teljesítménye lesz. Ergo kell valami megoldás, hogy jobb legyen a teljesítmény. Ez minden hardveren működő megoldás lesz.
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
Nem kell támogatnia, hiszen ez nem egy API, hanem egy framework, ami magán a DirectX Raytracingen fut. Csak a nem gyors részeit compute shaderre váltja, hogy gyors legyen. A DXR-nek alapvetően vannak nagyon jól működő részei, azokat fel is használja a Brixelizer. A problémás részeket ugorja át. A Microsoft számára teljesen jó megoldás ez is, mert az alap API marad a DXR-jük. Még új driverek sem kellene hozzá. Mindegyik mostani jó lesz. Módosítani sem kell semmit.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
Az a baj ezzel a megoldással, hogy nagyon gyors, így nem venne senki nagyon drága VGA-t. Az NV megoldásai azért előnyösek a cég számára, mert nagyon lassúak, és ez eladja a hardvert. Azt meg a GameWorks idejében sem kérdezte senki, hogy miért lassú a kód. Az NV és az AMD felfogása itt nagyban különbözik. Az NV egyszerűen nem is kutatja a gyors lehetőségeket. De ez nem azért van, mert nem tudnák kutatni, hanem azért, mert nem része a gazdasági koncepciójuknak, mert ha gyors lenne egy effekt, akkor nem gondolkodnál RTX 40-es VGA-n. De azt amúgy sosem állították, hogy a megoldásaikat ne lehetne sokkal gyorsabban megcsinálni, tehát nem is hazudnak, csak nem fejtik ki az igazság minden részletét.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
#60883
Abu85
HÁZIGAZDA
bitblueduck
#60881
Abu85
HÁZIGAZDA
válasz
bitblueduck
#60881
üzenetére
A VRAM-ot egyszerűen nem lehet ilyen dolgokkal pótolni. Azt jó menedzsmenttel lehet megoldani. De a DirectStorage ezen pont ront.
#60882 HSM : Ez nem olyan egyszerű ám, ahogy leírva tűnik. Amíg a dekódolás tart, addig a VRAM terhelése nagyobb. Emellett maga az allokációk törlése sem ingyenes. Tehát addig például nem is érdemes törölni a kódolt adatokat tartalmazó allokációkat, amíg nem feltétlenül muszáj, mert a törlés művelet maga sebességvesztést okoz.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
Itt a Portal RTX konkrétan profilozva.

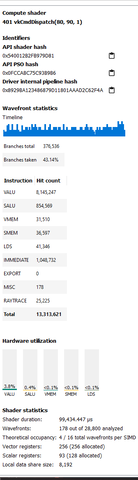
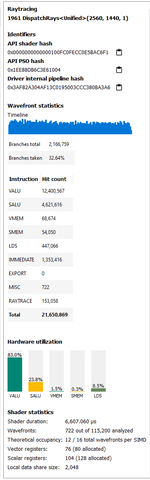
Ez az optimalizáció mindennek ellentmond, amit az egyetemeken tanítanak. Nem a hardver a lassú, hanem maga a kód annyira szar, hogy nem tud futni normális sebességgel a hardvereken.
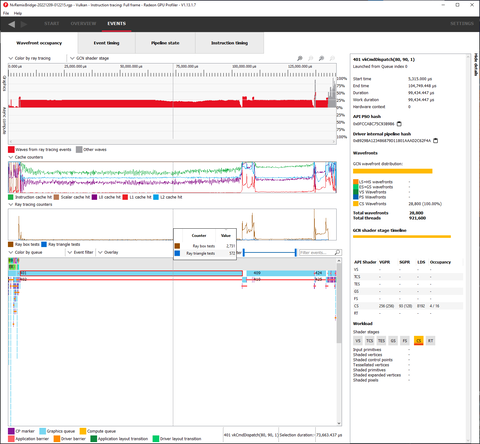
Az RT műveletek pedig elég lightosak.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
válasz
paprobert
#60887
üzenetére
Hát nem, mert az azt jelenti, hogy konkrétan ugyanaz a fos lesz. De amúgy nem látom, hogy az ilyen frame generálási megoldásokból hogyan lehet kevésbé fost kihozni.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
válasz
paprobert
#60889
üzenetére
A probléma az, hogy a DLSS3-hoz mérünk, aminek a képminősége eleve problémás a belegenerált hibák miatt. Ahhoz, hogy egy ilyen működőképes legyen, a DLSS3-nál sokkal-sokkal jobban kell működnie, sokkal-sokkal kevesebb hibával. Különben pont annyira nem lesz értelme, mint a DLSS3-nak.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
válasz
Raymond
#60892
üzenetére
Elejére: CURRENT LIMITATIONS
Végére: Brixelizer Global Illumination is still under development!
Csak, hogy ne hagyjuk már ki ezeket sem. Elnézést, hogy belekontárkodtam.

[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
Már bocsánat, de egy már kész képkockát csak azért nem kiküldeni a kijelzőre, hogy előbb generálj elé egy kevésbé friss, ráadásul potenciális képi hibákkal tarkított képkockát, a mélypont a rossz ötletek tárházában. És ha az AMD is ugyanezt csinálja, akkor ugyanolyan fos marad, mert pont ugyanazt a rossz ötletet lovagolják meg. Ha kész a friss és jó minőségű, valós adatok alapján számolt képkocka, akkor azt ki kell rakni! Nem érdemes húzni az időt. Azért vesz a játékos új hardvert, hogy ezt megkapja, és nem azért, hogy a nagyobb kiírható FPS-érték miatt parkoltatva legyen.
Én abszolút nem értem, hogy ezekben a lehetőségekben mit láttok. Vesztek egy új hardvert, amiben bekapcsoljátok a köztes frame generálását, hogy végül az elméletben lehetségesnél később kapjátok meg a legfrissebb képkockát. Why?
 Pont azért veszitek a drága új hardvert, hogy hamarabb kapjátok meg az eredményt, és bekapcsoltok egy olyan dolgot, ami ezt késlelteti. Nem beszélve a belegenerált képi hibákról.
Pont azért veszitek a drága új hardvert, hogy hamarabb kapjátok meg az eredményt, és bekapcsoltok egy olyan dolgot, ami ezt késlelteti. Nem beszélve a belegenerált képi hibákról.  Nem az a durva, hogy van ilyen, hanem az, hogy ezt el is lehet adni, és láthatóan már két cég hiszi azt, hogy van piaca annak, ha a játékos a nagyobb FPS-ért rontja a saját felhasználói élményét.
Nem az a durva, hogy van ilyen, hanem az, hogy ezt el is lehet adni, és láthatóan már két cég hiszi azt, hogy van piaca annak, ha a játékos a nagyobb FPS-ért rontja a saját felhasználói élményét.[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
válasz
paprobert
#60907
üzenetére
Amíg visszatartanak kész frame-et akármilyen generált frame miatt, addig ez érdektelen. A kész frame-ekért fizetsz a boltban, amikor VGA-t veszel, nem azért, hogy azokat ne kapd meg, amikor elkészülnek.
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
De az felbontásfüggő. Alapvetően akkor optimális a textúra felbontása, ha minden pixelsorhoz külön texelsorból származnak a minták. Ezt a legegyszerűbb úgy elérni, ha a textúra felbontását növeled.
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
Nem pont a textúrázás határozza meg a VRAM terhelését, hanem maga az alkalmazott leképező. Vannak kifejezetten memóriakímélő leképező algoritmusok, majdnem minden forward renderer, de ezeknek megvan a maguk baja, például a számítási kapacitás szempontjából a megnövekedett igény. Ezért alternatíva a deferred renderer opció a különböző lehetőségekkel, mert az kevésbé eszi a TFLOPS-ot, de több memóriát zabál. Játékfüggő, hogy melyik fejlesztő számára mi a fontos, és ebből a szempontból nagyon egyedi döntések születnek. Leginkább az határozza meg ezt, hogy a fejlesztő hogyan érzi az adott címre a vállalható limitet, a memóriát jobb-e lezabálni, vagy a számítási kapacitást.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
#61038
Abu85
HÁZIGAZDA
huskydog17
#61037
Abu85
HÁZIGAZDA
válasz
 huskydog17
#61037
üzenetére
huskydog17
#61037
üzenetére
Igazából nem pont ugyanaz a motor. Az első rész DirectX 11-et használt, míg a második már DirectX 12-t. Ez elég jelentős változás. Ráadásul az új részben van RT, ami ugye eszi a VRAM-ot.
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.























 Pont azért veszitek a drága új hardvert, hogy hamarabb kapjátok meg az eredményt, és bekapcsoltok egy olyan dolgot, ami ezt késlelteti. Nem beszélve a belegenerált képi hibákról.
Pont azért veszitek a drága új hardvert, hogy hamarabb kapjátok meg az eredményt, és bekapcsoltok egy olyan dolgot, ami ezt késlelteti. Nem beszélve a belegenerált képi hibákról.  Nem az a durva, hogy van ilyen, hanem az, hogy ezt el is lehet adni, és láthatóan már két cég hiszi azt, hogy van piaca annak, ha a játékos a nagyobb FPS-ért rontja a saját felhasználói élményét.
Nem az a durva, hogy van ilyen, hanem az, hogy ezt el is lehet adni, és láthatóan már két cég hiszi azt, hogy van piaca annak, ha a játékos a nagyobb FPS-ért rontja a saját felhasználói élményét.

Új hozzászólás Aktív témák
A topikban az OFF és minden egyéb, nem a témához kapcsolódó hozzászólás gyártása TILOS!
MIELŐTT LINKELNÉL VAGY KÉRDEZNÉL, MINDIG OLVASS KICSIT VISSZA!!
A topik témája:
Az AMD éppen érkező, vagy jövőbeni új grafikus processzorainak kivesézése, lehetőleg minél inkább szakmai keretek között maradva. Architektúra, esélylatolgatás, érdekességek, spekulációk, stb.
- Amlogic S905, S912 processzoros készülékek
- Honor Magic6 Pro - kör közepén számok
- Alternatív kriptopénzek, altcoinok bányászata
- Diablo IV
- Skoda, VW, Audi, Seat topik
- Google Pixel topik
- AMD K6-III, és minden ami RETRO - Oldschool tuning
- Óra topik
- Mesterportrékkal érkezett a Honor 200 Pro
- OTP Bank topic
- További aktív témák...
