Új hozzászólás Aktív témák
-

-NoVa-
őstag
válasz
 FőDudu
#28994
üzenetére
FőDudu
#28994
üzenetére
Próbálom egyszerűen és érthetően összefoglalni mennyiséggel pótolva a mélységeket.
Szóval a legkisebb egység egy neuronháló. Ami áll akárhány bemenetből, és legalább 1 kimenetből, valamint egytől akárhány rétegig mélységekből. Szélessége is tetszőleges. Szerkezetileg így néz ki:
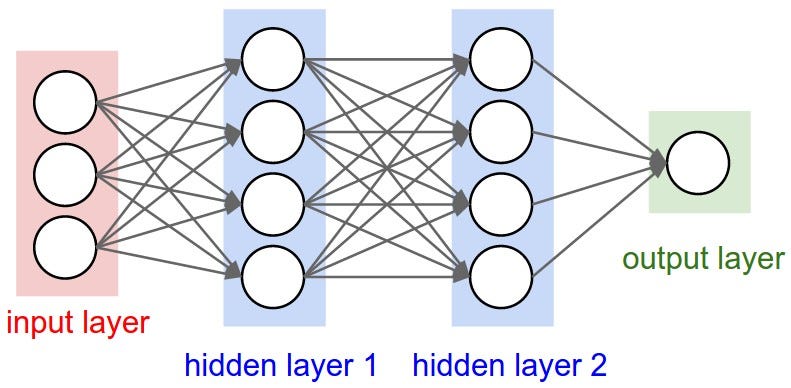
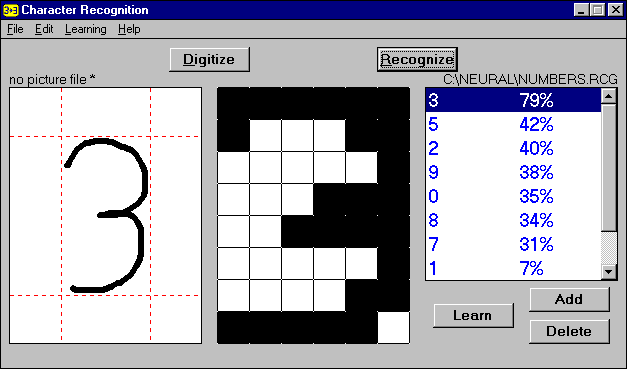
Ebből pl a bemeneted lehet egy homályos kép egy leírt számról. A rétegek és a rétegek közti kötések a fontosak. Feltöltöd nagyjából véletlenszerűen 0 és 1 közötti számokkal, és a kimeneted is egy ilyen lesz. Ezt a konkrét kis hálót pl be akarod tanítani arra, hogy magabiztosan mondja meg, hogy egy kézzel írott 7-es szám van-e a bemeneten. Legyen pl 3 réteg, rétegenként 100 neuron, a bemeneted meg egy 9x9 greyscale kép az egyszerűség kedvéért. Vagy akár kisebb, binarizált.
A tanítás alatt párfajta 7-est, valamint egyéb nem 7-es inputot adsz a bemenetre, de nem feded le az összes lehetséges iterációt, ami inputként valaha előfordulhat. Ellenben lesz sok véletlenszerű adatokkal feltöltött hálód, amik mindenféle bemenetre 0-1 közötti pontot adnak a kimeneten, és kiválasztod azokat, amik a kiértékeléseden a legtöbb pontot értek el, azaz a legkevésbé szar eredményt. Ezekből készíted el a következő generációt, az eredeti véletlenszerű értékeket mindegyik példányban kicsit torzítva, majd újra versenyeztetve kezdeni előről.
Sok sok ismétlléssel később kialakulhat egy olyan viselkedés, ahol az első réteghez vezető nyilak már nem fedik át egymást, hanem egyes neuronok egyes inputokat, esetleg a környékükről jövő inputokat veszik csak figyelembe, és azokból döntenek egy számot, amiket a következő rétegnek adnak inputnak, ahol szintén kialakul, hogy ott melyik réteg melyik inputját hogyan vegye figyelembe az adott döntés. A végén kialakul egy olyan döntési fa, aminél ha a kép felső részén lát vonalat, és alul pedig jobbról balra átlósan vagy lefelé folytatódik egy vonallal az egész, és a többi területen nincs, akkor viszonylag 1-hez közelítő végeredményt fog adni, ha ezek nem teljesülnek, akkor 0-hoz közelítőt.
Aztán ugyanezt létrehozod a többi számra is, és a végén lesz egy-egy hálód, amik egy-egy számról mondanak egy végeredményt, hogy szerintük mekkora valószínűséggel az:
Ez a legkisebb egység, egy Google szöveges képkeresésnél pl egyszerű, de jól szervezett lépcsőkben sok gyors döntéssel megy végig egy komolyabb lánc, ahol egy képről eldönti, hogy van-e rajta növény, vagy élőlény, ha élőlény van, akkor az emlős, kutyaféle, aztán labrador, vagy stb. Ezekre a lépésekre nagyon egyszerű kis betanított adathalmazok vannak, esetleg specializálva, hogy szemből, profilból, stb külön hálót küldjön rá. Jellemzően kicsi, pár kbyteos eltárolt súlyozási számokról van szó, amiket ezredmásodpercek alatt kiértékel egy mai gép. A sima kompakt fényképezőgépek mosolyfelismerő meg pislogásdetektáló funkciója, arc-fókusz, stb, az ilyen egyszerű nem számításigényes, előre kiszámolt és feltöltött dolgokra alapul.
A nehézség nem itt van, hanem abban, amit ezekből a kis egységekből építenek. Egy komplexebb rendszerben a kimenet felől is jön sok visszacsatolás, és lentebbről is minden azt a kimenetet használó egységtől, amit figyelembe véve módosíthat bizonyos súlyozásokat saját magán. Ezzel működés közben javítja a saját hatásfokát egyetlen példány, rengeteg ismétlődő ciklussal finomítva a működését. Ez a fajta tanulás figyelembe veszi a pozitív, negatív, és a semleges választ, és jó esetben saját rendszeren belülről is képes öngerjesztően kifejleszteni belső pozitív megerősítéseket. Ráadásul egy hálónak nem egy kimenete lehet, akárhány, ebből bármennyi visszacsatolva is, így önmagában megvalósíthat információáramlást és memóriát is.
Na ezek a visszacsatolási rendszerek, komplex tanító, megerősítő, és önmódosító algoritmusok együtt adnak ki egy komolyabb AI alapját.
Ilyen pl a Google féle AlphaGO:
[link]Itt pl azontúl, hogy hosszas számolgatás és kiértékelés után kialakítanak egy ideális méretet, csak annyi a betanító felelőssége, hogy a külső visszacsatolás következetes legyen, jól pontozzon.
És persze ezeket fürtbe rendezve önállósítva beszélhetünk mesterséges intelligenciáról. Ha egy réteg felismeri, hogy adott feladatra a saját legjobb megoldása nem kielégítő, de adott területre képes magát átméretezni (azaz létrehozni egy hasonló példányt de több/kevesebb réteggel, más struktúrával, pl több memóriaként visszacsatolható kimenet/bemenet párossal, majd betanítani a saját legjobb tudásának megfelelően, és kiváltani saját magát), az egy aktuális fejlettnek számító mesterséges intelligencia. Ilyenek fürtbe állítva, ha elég nagy számítási kapacitást kapnak, képesek új területeken működni és önálló megalapozott döntéseket hozni. Itt tartunk most, ennyire egyszerű logikai döntési fákra alapozunk üzleti döntéseket, meg képfeldolgozást, autóvezetést, mindenfélét.
Persze van némi matematikai fejlődés, de a két legfontosabb irány, hogy olcsón van alá számítási kapacitás, és jobban tudjuk már valós hétköznapi folyamatokba bekötni ezeket. Egy kicsit túl van misztifikálva, de ettől lehet drágán bevonzani befektetőket, meg nagyvállalatokat. A valódi haszna az, hogy automatizálhatunk egy csomó tényleg unalmas mindennapi ledarálható folyamatot, a másik meg, amire használják, hogy brute force megoldásokat gyártanak olyan dolgokra, amiket NAGYON át kéne gonodolni, és bíznak benne hogy elég sok tanulás után majd boldogul. Ez utóbbitól lehet kicsit tartani.


Új hozzászólás Aktív témák
- Van, amit nehéz lett megtalálni a Google keresőjével
- OLED TV topic
- Trollok komolyan
- NVIDIA GeForce RTX 4080 /4080S / 4090 (AD103 / 102)
- Milyen routert?
- Miskolc és környéke adok-veszek-beszélgetek
- Kedvenc zene a mai napra
- AMD K6-III, és minden ami RETRO - Oldschool tuning
- Skoda, VW, Audi, Seat topik
- Így építsd a billentyűzeted!
- További aktív témák...
