- Letartóztatták a bitcoin-Jézust
- Adobe Lightroom topic
- Amazon Prime Video
- Az iPadOS-re írt appokra is díjat vet ki az Apple
- Telekom otthoni szolgáltatások (TV, internet, telefon)
- Sokat fogyaszt az AI, egyre több az adatközpont, kell az atomenergia
- Hálózatokról alaposan
- Kínai cégek segítik ezentúl a Teslát, a Renault-t, a Hyundait és a Toyotát
- Adobe Illustrator kérdések
- DIGI internet
Új hozzászólás Aktív témák
-

axioma
veterán
Na de a _vizsgalatnal_ legyen a teljes, az if feltetelnel, es ha ures, akkor a teljes (azaz semmi, ide lehet hogy irhatnal siman ""-t), egyebkent meg a 0. karakter plusz a 2 szamjegy, de ez a sor vegen van leirva...
Ez sztem csak regexp szint, csak a string = betuk listaja, aminek ures eseten nincs nulladik eleme miatt mondom hogy python elvvel megmondom. A 2.7 regebbi de nem egyszerubb, csak mas van beepitve es kicsit mashogy kell irni pl. print-et, de amugy en azzal szoktam dolgozni versenyeken.Varj, kezdjuk elolrol. Most jottem ra, hogy az indexben csak a sorszam van...
A series mezoben benne van ami a sorozat, vagy oda fogod tenni?
Miert nem{series:ifnotempty({series},{series[0],series_index:0>2s})
(zarojelek lehet hogy mashogy kellenek, nem egyertelmu mi az osszefuzes es hogy kell itt a feltetelt a tobbitol elkuloniteni)[ Szerkesztve ]
-

snowdog
veterán
Ezt már kitárgyaltuk. [link]
series[0]nem lehet benne, mert elsők között ezt az értéket próbálja megállapítani, de ha a sorozat mező üres, akkor hibaüzenettel elszáll.Arra is figyeljetek, hogy ez nem tiszta python. A Calibre készítője előre deklarált parancsokat, aminek az alapja python. Viszont a saját parancsainak saját szintaktikája van, ami nem biztos hogy pontosan egyezik a python-éval. Ez okozhat némi zavart. Célszerű ezt az oldalt tanulmányozni. [link]
[ Szerkesztve ]
-
snowdog
veterán
válasz
 snowdog
#1653
üzenetére
snowdog
#1653
üzenetére
Sajnos a legutóbbi verzió sem úgy működik, ahogy szeretném. Kitöröl olyan karaktereket is, amiket nem kellene, és hasonlók. Ezért aztán leegyszerűsítettem az egészet, veszem a sorozat név első két betűjét, és mögé teszem a sorozatszámot. Ennyi, ez most nekem jónak tűnik.
Az 1. oszlop azonosítója rsor1, a másodiké rsor.
1. oszlop sablon:{series:re((A|Az)\s+,)||}
2. oszlop sablon:{#rsor1:.2}{series_index:0>2}Ennek eredménye pl. a Rakéta Regényújság 5. szám (csak a teszt miatt tettem be, de a korábbi sablonnál többek között ezzel volt probléma) most így néz ki: Ra05
A korábbi verzióban az 1. sablon a Rakéta Regényújság-ból valamiért RakétRegényújág-ot csinált, akár mit is csináltam. Mivel összefűzte az első két szót, így már használhatatlan volt.
Elképzelhető hogy később még az 1. oszlop sablont módosítani kell, majd ha látom milyen sorozatnevek lesznek. Mondjuk ha több sorozatnév is úgy kezdődik, hogy "Egy" és valami, akkor a sablonba a kizárandók közé majd beteszem az "Egy" szót is. És így tovább...
[ Szerkesztve ]
-
axioma
veterán
válasz
snowdog
#1654
üzenetére
A Rakéta regényújságból szerintem az 'a ' azert tunik el, mert nincs a regexp-ben semmi, ami a szo (string) elejen kezdodonek deklaralna a nevelot.
Az 'új' után az s eltunese furcsabb, arra nincs tippem.Szerk. tegyel be egy kalapot a zarojel ele:
{series:re(^(A|Az)\s+,)||}, akkor nem vonja ossze.[ Szerkesztve ]
-
snowdog
veterán
Ez valóban megoldotta a problémát, de jelentkezik egy újabb. A három oszlopsablont egymás alá másoltam, és "|" jellel választottam el őket, a jobb láthatóság kedvéért. De az eredmény a lényeg.

Ugyebár azt szeretném, hogy az első két szó első-első betűje jelenjen meg. Akkor a Regényújság "R" betűjét miért hagyja ki?
-
axioma
veterán
válasz
snowdog
#1656
üzenetére
Hat ezt at kene gondolnom, mert mi van ha csak egy van?
Amugy nem ugy lenne a jobb (regexp-ben tuti egyszerubb), hogy minden nagybetubol az elso 2?
Amit leirtal ott azert csak 1 van benne, mert a \1-et raktad csak bele (elso regexp-beli megtalalas), nem vagyok nagy regexp spiler, de valahogy a masodik szo elso betujet is le kene valasztani mint keresesi eredmenyt, es hivatkozni ra mint \2.
Talan igy mar menne:re(([^\s])[^\s]*\([\s]([^\s])|$\),\1\2)
De bezavarhat, ha a vegejel bekerul a kesz stringbe, azt nem tudom hogy arra mit csinalna... (a +-t direkt csereltem *-ra, egybetus is lehessen a szo, nem csak min.2, pl. Mr. X)
(Ebben az elotte backslash zarojel eseten nem szamolodik megtalalasinak dologban nem vagyok biztos)[ Szerkesztve ]
-
snowdog
veterán
Amugy nem ugy lenne a jobb (regexp-ben tuti egyszerubb), hogy minden nagybetubol az elso 2?
Nem, mert a sorozatnévben többnyire csak az első betű nagybetű, kivéve a név is van benne. Vegyük például a "Jéghegyek népe" sorozatot. Itt az általam kívánt rövidítés a "JN" lenne, amiből csak az egyik nagybetűs.
Egyébként meg az általad írtaknak némileg ellentmond az, hogy ha ugyan ezeket a sablonokat használom, de a "Rakéta Regényújság 2015" helyett (aminél nem jól működik az első sablon) például a "Jókai Mór Az gyűjtemény"-t használom (szándékosan állítottam be ilyen cifrát, hogy lássam mit szűr ki), meg jól működik.
Eredmény JM01, ahogy kell.
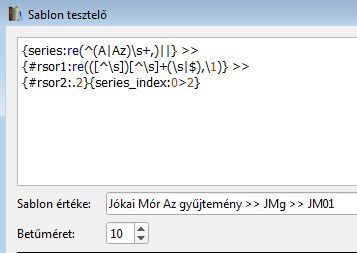
[ Szerkesztve ]
-
snowdog
veterán
Ezzel a képlettel sem jó.
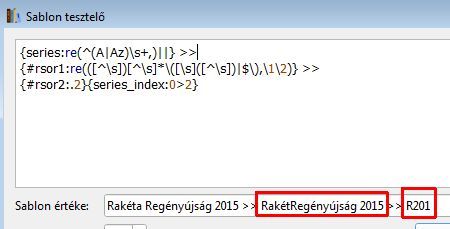
A régi képlettel pl. a "Jéghegyek népe" is működik, csak a Rakéta Regényújságtól valamiért megfekszik .Itt csak annyi a bibi, hogy a második betűt is nagybetűre kellene varázsolni, de feltételezem az már menne (még nem próbáltam).
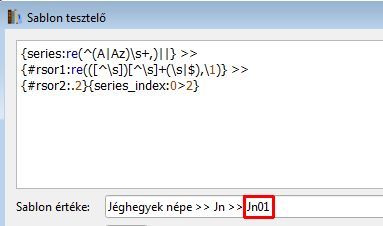
[ Szerkesztve ]
-
-
axioma
veterán
válasz
snowdog
#1660
üzenetére
Nem ;-)
A lenyeg, h a cim elejerol akarod kivenni a nevelot, de megis kiveszi a raketa vegerol. Ezert lesz a ket 'betu' az R es a 2.
Szoval az a javitas igy nem jo, ha elotte mar szokozzel osszefuzted, akkor a ^ helyett \s kell oda. Marmint az elso sorban.[ Szerkesztve ]
-
axioma
veterán
válasz
snowdog
#1664
üzenetére
Jo, de most irdd bele a 2. sorba azt, amit en irtam a \( -eket is tartalmazot. Akkor mar RR01 lesz.
Bocs, most latom, igy is a 2-t rakta bele masodikkent, akkor meg mindig az A/Az kiszedes a gond. Ott nem tudsz kozteset kiiratni, hogy igy is kitorli-e a szo vegi "a "-t?[ Szerkesztve ]
-
axioma
veterán
Rajottem!!!!
Az a baj, hogy azzal hogy "vagy van egy nem szokoz vagy vege jel", azzal a masodik szot is az elsoben felismered. Es ha 5 szobol allna akkor a tieddel kiszedne az 1., 3., 5. kezdobetuket.
Akkor tenyleg tedd be az enyemet, de az is addig jo, amig nincs 3-nal tobb szo benne. Szoval javitva:re(([^\s])[^\s]*\([\s]([^\s]).*|$\),\1\2)
ez elvileg megeszi a masodik kijelolt utan az osszes tobbi karaktert, igy pont az elso es 2. kezdobetu kene maradjon (az A/Az viszont jo kerdes, mert igy azt kiveszi ha pl. az a masodik szo, azt szeretned vagy csak a cim elejerol, es ha masodik az A/Az akkor mar ne, bar case-sensitive miatt nagybetuvel csak nem irja senki...)
Vagy meg egyszerubben:re(([^\s])[^\s]*,\1)ez elvben kiszed minden kezdobetut, es utana tudsz kulon 2 beture roviditeni, de nem kell egy randasagot atlatni.[ Szerkesztve ]
-
axioma
veterán
válasz
snowdog
#1668
üzenetére
Otthon van, de ott se tudom hova irjatok ezt be.
Masreszt kene az, hogy min futtatod, mert pl. ez nem tudom mibol keletkezett amit eredmenykent irtal oda.
Akkor az egyszerusitett megsem jo... pedig azt hittem hogy soxor csereli, attol jott be az R2 az elozoben.
Utolsokent tedd mar be legy szives a hosszabbikomat, aztan ha az sem, akkor majd hetvegen (ma megyek nagyfonokhoz reportra, epp azt talalgattuk, hogy kirugni akar vagy mit Nem, nem lennek attol se meglepodve meg kiborulva sem, csak fura az hogy atnyul 2 masik fonokon).
Nem, nem lennek attol se meglepodve meg kiborulva sem, csak fura az hogy atnyul 2 masik fonokon). -
snowdog
veterán
Így sem jó.
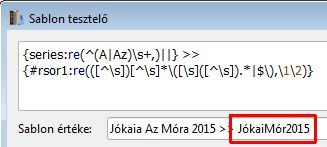
Korábban képekkel illusztrálva részletesen leírtam hogyan kell létrehozni saját oszlopokat, azokat hogyan kell definiálni, és hogyan kell használni a képeken látható sablon tesztelőt.
Köszönöm a munkádat! Most tartok egy kis szünetet. Találtam egy regex tesztelő, oktató programot, eljátszogatok vele egy kicsit.

-
snowdog
veterán
válasz
snowdog
#1670
üzenetére
Megszületett a jó megoldás. Igaz hogy még eggyel több "vak" oszlop kellett hozzá, de ez már lényegtelen, úgy sem látszik. A részleteket olyan sokszor kitárgyaltuk már, hogy azokba most nem megyek bele, csak a végeredményt teszem ide. A sorozat nevet átalakítja csupa nagybetűssé, kiszedi az "a, az, és, :, - betűket, és a számokat, majd veszi a szavak első betűjét, ebből jelenítem meg az első kettőt. Ezen lehet változtatni, ha valaki kevesebbet, vagy többet szeretne (utolsó sor).
Ha csak egy szóból áll a sorozatnév, akkor annak csak az első betűje jelenik meg. Még gondolkodom rajta, hogy ilyenkor ennek az egy szónak sz első két betűjét vegye. De ez már a jövő.
{series:uppercase()}
{#rsor1:re((A|AZ|ÉS|:|-|[0-9].*)\s+|[0-9]|[-], )||}
{#rsor2:re(([^\s])[^\s]+(\s|$), \1)}
{#rsor3:re((\s),)}
{#rsor4:shorten(2,,0)}{series_index:0>2}
[ Szerkesztve ]
-

Phülöp
addikt
válasz
snowdog
#1671
üzenetére

már csak azt nem tudom, hogy ezeket hová kell beírni
én még ott tartottam, hogy létrehoztunk új oszlopo(ka)t, aztán a metaadat kapcsolatok résznél a forrássablon eredményét betettük a céloszlopba (cím)A Bretagne-félsziget meredek ormai alatt Otthont találnak kóbor csikóhalak. /Mesterem
-
snowdog
veterán
zseko itt szépen leírta hogyan kell a saját oszlopokat beállítani. [link]
Annyi saját oszlopot kell definiálni, ahány sort az előbb betettem. Minden saját oszlophoz a sablon részbe kell ezeket bemásolni (legalsó mező). Minden saját oszlopba egy sort, másképpen nem is lehet. Láthatóvá csak a legutolsót kell tenni, hiszen abban van az eredmény. Ezért neveztem a többit "vak" oszlopnak. Ha igény lesz rá, akkor a saját fórumomba készítek egy lépésről-lépésre útmutatót, képekkel. Ezt a fórumot ezzel nem terhelném.
A sablon tesztelővel nem kell foglalkozni, azt csak azért tettem be, hogy akit érdekel nyomon tudja követni hogyan alakult ki a végeredmény.
[ Szerkesztve ]
-
Phülöp
addikt
válasz
snowdog
#1673
üzenetére
így már tiszta, köszönöm
azon csúszott el a dolog, hogy a leírásodban nem szerepelt a "Plugboard expression", amivel az eredeti "cím" oszlop tartalmát írtuk felül a kezdeti próbálkozások során
[ Szerkesztve ]
A Bretagne-félsziget meredek ormai alatt Otthont találnak kóbor csikóhalak. /Mesterem
-
snowdog
veterán
Annyit még hozzátennék, hogy ezzel még csak a Calibre egyik oszlopában tettük láthatóvá a rövidített sorozatnevet. Ahhoz hogy ez a Kindle olvasón is megjelenjen, ki kell tölteni a "Metadat kapcsolatok" megfelelő mezőit (úgy emlékszem korábban erről már volt szó). A programsorok közül az utolsó sort kell beírni a "Forrássablon" mezőbe.
u.i. megkerestem, szintén zseko írt róla. [link]
[ Szerkesztve ]
-
snowdog
veterán
Kicsit csiszoltam rajta, most már az egyszavas sorozatnevekből is egy kétbetűs rövidítést állít elő. És ismét eggyel kevesebb saját oszlop kell hozzá, vagyis összesen négy (szemben az előző öttel). Így a saját oszlopnevek sorrendben: rsor1, rsor2, rsor3, rsor
Ebből megjeleníteni csak az utolsót, az "rsor"-t kell (a többi elől ki kell, vagy ki lehet venni a pipát. Ezt kell a "Metadat kapcsolatok"-nál megadni.Ez most annyiban más mint az előző, hogy nem a szavak első két betűjét veszi, hanem a szavak első és utolsó betűjét. De ez szerintem lényegtelen, mert csak arra van szükség, hogy a sorozatokat megtudjuk egymástól különböztetni. Nekem legalábbis mindegy, hogy ezt melyik két betű jeleníti meg. Akinek így nem jó, az természetesen csiszolgathatja tovább.
{series:uppercase()}
{#rsor1:re((A|AZ|ÉS|:|-|[0-9].*)\s+|[0-9]|[-], )||}
{#rsor2:re((\s),)}
{#rsor3:shorten(1,,1)}{series_index:0>2}
A kép csak a feldolgozás menetét illusztrálja, a tartalma másra nem jó!
G.F.
Az oszlop típus minden oszlopnál ugyan az mint eddig (Más oszlopból előállított oszlop), de figyelj az oszlopnevekre! Ha továbbra is problémád van vele, akkor javasolom a képen látható "Sablon tesztelő" használatát, ami könnyen rávezethet a hibára.[ Szerkesztve ]
-
-
snowdog
veterán
Mert a regex-el így tudtam egyszerűen megoldani. Mint írtam, ha valaki mást szeretne, az csiszolgassa tovább a regex-et.
Az utolsó előtti változat azt teszi amit szeretnél (JM). [link] Csak ott az egyszavas sorozatnévnél van egy kis bibi.
Elég sok időt eltöltöttem vele, egyenlőre nem kívánok vele többet foglalkozni.
[ Szerkesztve ]
-
#1686
 Bosco01
tag
hampidampi
#1682
Bosco01
tag
hampidampi
#1682
Bosco01
tag
válasz
 hampidampi
#1682
üzenetére
hampidampi
#1682
üzenetére
Köszönöm Neked is és Snowdognak is!

-
Phülöp
addikt
válasz
snowdog
#1681
üzenetére
nálam valami árulás van, nemmegyanemmegy:
calibre, version 3.18.0
HIBA: Ismeretlen hiba történt: <b>InvalidPlugin</b>:The plugin in u'C:\\Users\\Iguana\\Calibre Portable\\Calibre Settings\\plugins\\DeDRM_tools_6.5.5.zip' is invalid. It does not contain a top-level __init__.py fileugyanez az eggyel régebbi verzióval is
[ Szerkesztve ]
A Bretagne-félsziget meredek ormai alatt Otthont találnak kóbor csikóhalak. /Mesterem
-

moma
őstag
köszi hampidampi az ideirányítást!
Sziasztok kicsit off lesz, de talán itt van legjobb helyen, mert úgy érzem a calibre központi helyen lehet a megoldásban.
Szeretnék kialakítani egy jó struktúrát olvasáshoz. Az lenne a szempont, hogy amit elkezdek olvasni telefonon és szöveg kiemelek benne jegyzeteket rakok bele, azt tudjam folytatni asztali gépen is. És a jegyzeteket könnyen kiszedni aztán ha szükséges szöveges fileba. És ezt minél kevésbé file formátum függően(esetleg webes cikkekhez is). Van hasonlóra kialakult módszere, alkalmazásai valakinek? Szeretnék venni egy ebook olvasót is és akkor azon is olvasni, szöveget kiemelni, jegyzetelni. De először meg kéne értenem a lehetőségeimet egyáltalán a fileokkal szerintem és ha értem az igényeimet hozzá egy olvasót majd.
Először használtam telefonon a moon+ readert, de annak nincs asztali verziója. Meg nem is értettem meg egészen a jegyzet kezelést, hogy azt hogy lehetne áthozni egyszerűen asztalira.
Aztán most próbálkozom a xodo nevű appal, de ez csak pdf.
Meg amit észrevettem, hogy pdf-et nem túl jó olvasni asztali gépen, mert túl hosszúak nekem a sorok. Szóval lehet mindenképp ott indul a dolog, hogy a pdfet alakítani kellene olvasás előtt valami rugalmasabb formátumba. epub talán? vagy valami webes fileformátum lenne a jó. pl firefoxban szeretem a reader viewt pl de ott nem lehet szöveget kiemelni, meg jegyzetelni egyszerűen bele.
Ha nem is tudtok megoldást, de ha van akit érdekel ez a téma, akkor lehetne együtt gondolkodni.
we all deserve a bit of luck.
-
snowdog
veterán
Nekem ebből az útmutatóból az jön le, hogy ki kell csomagolni. A te hibaüzeneted meg a csomagolt fájlra hivatkozik. Csak tippelek, mert én nem telepítettem.
Installing the DeDRM plugin for calibre
Download the latest tools package, and unzip it.
(On Windows, right-click and “Extract All…”; After extracting all, rename the tools_vX.X.X.zip file to tools_zipped_vX.X.X.zip to prevent later confusion)
Run calibre. From the Preferences menu select “Change calibre behavior”.
(Do not click “Get plugins to enhance calibre”, that option is reserved for ‘official’ calibre plugins.)
Click on Plugins (under “Advanced”) — it looks like a jigsaw puzzle piece.
Click on the large “Load plugin from file” button
Navigate to the tools folder unzipped in step 2
Open the “DeDRM_calibre_plugin” folder
Select the DeDRM_plugin.zip file in that folder
Click on the “Add” (sometimes “Open”) button.
Click on the “Yes” button in the “Are you sure?” warning dialog that appears. A “Success” dialog will appear, saying that the plug-in has been installed. Click on “OK”.Megvan, itt található amire szükséged van:
DeDRM_tools_6.5.5 plugin.zip\DeDRM_calibre_plugin\DeDRM_plugin.zip[ Szerkesztve ]
-
snowdog
veterán
Ma egy érdekes dolgot vettem észre. A Calibre könyvtárakban ahol a könyv címe több szóból áll, az első és a második szó között mindenhol két space karakter van. Mind a könyvtár, mind a fájl nevében. A mellékelt képen látni, hogy azért kivételek is vannak.
Nem hiszem hogy felhasználói beavatkozás okozná, hiszen ebbe a felhasználó nem tud beleszólni. A metaadatoknál természetesen mindenhol csak egy szóköz van.
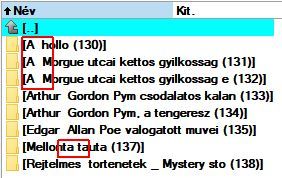
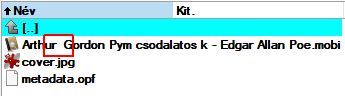
-
snowdog
veterán
válasz
snowdog
#1693
üzenetére
Próba képen kimentettem egy ilyen könyvet a HDD-re, és a mentett fájlnévben is dupla szóköz van az első két szó között. Tehát a Calibre nem csak a saját belső használatakor alkalmazza a dupla szóközt. Ha úgy lett volna, akkor már nem is izgatna a dolog. Így viszont zavaró.
[ Szerkesztve ]
-
#1696
 hampidampi
senior tag
snowdog
#1694
hampidampi
senior tag
snowdog
#1694
hampidampi
senior tag
válasz
snowdog
#1694
üzenetére
Bővebben: Gondolom használod a moly.hu-s plugint. Ez ugyanis onnan jön, nem a Calibre sara.
Nézd meg magad is. Menj fel a moly.hu-n egy ilyen dupla szóközös címre, jelöld ki a címet, illeszd be wordbe és kapcsol be a speciális karakterek megjelenítését. A sima szóköztő jobbra lesz egy nulla széles szóköz is (Zero With Space, unicode: 200B).
Vagy menj a Calibre-ben a cím mezőben és kezdj el mozogni a kurzorral, és észreveszed, hogy két szó közt kétszer kell nyomni a gombot. -
#1697
snowdog
veterán
hampidampi
#1695
snowdog
veterán
válasz
hampidampi
#1695
üzenetére
Igazad van, csak első ránézésre a metaadatoknál nem vettem észre, ott egynek látszott. Ha kitörlöm a láthatatlan szóközt, akkor rendben van.
Van arra valamilyen bevált módszer, hogy ne egyesével kelljen javítgatnom a címeket? Vagy kezdjek el kísérletezgetni vele?
-
#1699
snowdog
veterán
hampidampi
#1698
snowdog
veterán
válasz
hampidampi
#1698
üzenetére
Köszönöm az iránymutatást, ezzel is sokat segítettél. Akkor kezdődik a kísérletezés.
Ha megvan a megoldás, közzé teszem.
-
#1700
snowdog
veterán
hampidampi
#1698
snowdog
veterán
válasz
hampidampi
#1698
üzenetére
Elsőnek reguláris kifejezéssel próbálkoztam. Így ki tudom szűrni a nem karakter jelet.
A példában a "A francia nő" címben az f betű előtt van a ZWJ, és csak azt cserélem csillag karakterre, hogy lássam hol bújt meg. Innentől kezdve már csak egy csere metódust kell alkalmaznom.



































Új hozzászólás Aktív témák
- Politika
- E-roller topik
- Milyen egeret válasszak?
- Letartóztatták a bitcoin-Jézust
- Témázgatunk, témázgatunk!? ... avagy mutasd az Android homescreened!
- Kerékpárosok, bringások ide!
- A Play Áruházban is fellelhető a legjobb Samsung segédalkalmazás
- D1Rect: Nagy "hülyétkapokazapróktól" topik
- Építő/felújító topik
- Samsung Galaxy S24 - nos, Exynos
- További aktív témák...

- Corsair Obsidian 500D Mid-Tower Üvegajtós gépház
- Creative Sound BlasterX AE-5 Plus belső hangkártya - RGB led szalaggal
- Teljesen új Xiaomi Mi Robot Vacuum-Mop Essential robotposzívó eladó (bontatlan)
- Bomba ár! Lenovo E31-80 - i5-6200U I 8GB I 256GB SSD I 13,3" I HDMI I Cam I Win10 I Garancia!
- Bomba ár! Lenovo ThinkPad L530 - i5-3GEN I 8GB I 500GB I DVDRW I 15,6" HD I mDP I W10 I Garancia!
Állásajánlatok

Cég: Ozeki Kft.
Város: Debrecen

Cég: Promenade Publishing House Kft.
Város: Budapest