-

IT café
A legtöbb kérdésre (igen, talán arra is amit éppen feltenni készülsz) már jó eséllyel megtalálható a válasz valahol a topikban. Mielőtt írnál, lapozz vagy tekerj kicsit visszább, és/vagy használd bátran a keresőt a kérdésed kulcsszavaival!

Új hozzászólás Aktív témák
-

Abu85
HÁZIGAZDA
AGS, de az inkább egy szervizkönyvtár, amiben van egy DX11/12-re használható shader intrinsics kiterjesztés. Szinte mindegyik DX12-es játék használja valamire. De ott van pár DX11-es játékban is, mint az új Mass Effect vagy az új Resident Evil. Leginkább a Doom, a Battlefield 1 és a Deus Ex: MD használja. Később egyébként erre nem lesz szükség, mert DX12-re jön a shader model 6.0 wave intrinsics, és a Vulkan is lassan kezdi beépíteni ezeket szabványos formában.
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
Amire lejárt az NDA arról már van hír/cikk. A Vega májusban lesz ténylegesen bejelentve. Még február elején írtam májusról, vagy lehet, hogy korábban, de azt írtam, hogy a Prey mellé jön. Ez lesz az AMD-Bethesda együttműködésének legelső próbája. Később jön majd a Quake Champions, ami szintén ezzel a fejlesztési stratégiával készül. Szó van meg egy be nem jelentett Bethesda játékról is, ami valami űrhajós RPG-izé lesz, és ebbe az AMD a Bethesda egyedi megrendelésére tervez már effekteket. Tulajdonképpen a fő célja a Bethesdának ezzel a módszerrel, hogy az AMD legyen az R&D részlegük.
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
válasz
 TTomax
#26816
üzenetére
TTomax
#26816
üzenetére
Egyszerű. Eddig API-tól függően a kernel driver vagy az alkalmazás döntött arról, hogy a rendszermemóriából mi kerüljön a VRAM-ba. Az adatok ide-oda helyezgetése egy szoftveres rétegen múlt. A Vega esetében erről a hardver dönt, a drivernek vagy a programnak csak azt kell megmondania, hogy hol az adat a rendszermemóriában.
Ezt baromira nem könnyű implementálni. Az NV is csak a GP100-ba rakott hasonló vezérlőt, de az is igen korlátozott képességű, ezért működik csak a CUDA-val.
Az AMD-nek annyiban egyszerűbb az ilyen rendszerek tervezésénél a dolga, hogy náluk van egy modern processzorok tervezésével foglalkozó részleg is, így számos olyan mérnököt tudnak az RTG részleghez helyezni, akiknek a CPU-s virtuális memóriáról rengeteg tapasztalatuk van. Az NV-nek csak ez hiányzik, mert a cégnek a CPU-s problémákkal nem igazán kell foglalkoznia. De ettől a GP100-on látszik, hogy nincsenek ők sem messze egy ilyen rendszertől.[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
válasz
TTomax
#26819
üzenetére
Természetesen. És pont ez az egyik probléma, amiért felmerült régebben, hogy menedzselje ezt a hardver. Tudniillik, ha a x GB VRAM-nak a fele haszontalan információ, akkor jóval hamarabb kell a rendszermemóriához nyúlni, hiszen x GB-ból csak x/2 a hasznos, vagyis a VRAM hamarabb elfogy. Na most x GB HBC-nél a hatásfok majdnem 100%, tehát tényleg annyi memória hasznosítható, ami van a GPU mellett, vagyis jóval később következik be egy olyan szituáció, hogy elfogy a tár és megfelelő előkészület nélkül hirtelen a rendszermemóriához kell fordulni.
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
válasz
 Bélaaaa
#26821
üzenetére
Bélaaaa
#26821
üzenetére
Két részre kell bontani ezt. A régebbi DX11 és idősebb, valamint az OpenGL API-k esetén az okozza a problémát, hogy drága a VRAM-ban törölni. Egyszerűen, ha egy nem használt allokációt töröl a driver, akkor az akkor terhelést ró a CPU-ra, hogy tuti akadni fog a program. Ezért bármennyire is haszontalan a régen betöltött adat, azt nem törlik, csak akkor, ha már végleg nincs más lehetőség. Emiatt a régi API-ra épülő programokban jellemzően a VRAM-ba töltött adatok fele, vagy rosszabb esetben a háromnegyede csak a helyet viszi, mert törölni túl drága.
DX12/Vulkan alatt az alkalmazás törölheti a nem használt allokációt, és ez szerencsére olcsó, noha nem ingyenes, de tényleg elég kevés prociidővel megoldható. Gyakorlatilag a törlés már nem jár akadással, persze így is ésszel szabad csinálni. Itt a gondot az okozza, hogy nagyon nehéz jó menedzsmentet kialakítani specifikus, architektúrákhoz szabott optimalizálásokkal. Ezért sajnos az explicit API-k alatt előfordul, hogy egy csomó olyan adat kerül betöltésre, amiknek semmi haszna. Ezt hívják a VRAM szemetelésének. Itt a programok nagyon eltérnek. Például a Rise of the Tomb Raider elég rossz, mert 1-2 GB szemetet is betölt a fontos adatok mellé. A Sniper Elite 4 viszont nagyon jó, alig mérhető a betöltött szemét mennyisége, mindössze 100-200 MB körül van egy hosszabb játék után. Tehát alapvetően az explicit API-ban lehet alkotni, de nem mindenki tud. És ilyen formában az emberi tényező problémává válik.[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
válasz
TTomax
#26823
üzenetére
Ezt már megmutatták, hogy hogyan működik a gyakorlatban. 2 GB-ra korlátozták a Vegát, és a Deus Ex Mankind Divided DX11-es módjában lefuttatták a tesztet VRAM és HBC módban is. A HBC kétszer jobb fps-t ért el minimum mérésben. Tehát 2 GB elég volt egy olyan játéknak, amit igazából 4 GB-ra terveztek. Az AMD hivatalosan elismerte, hogy a hatásfok 100%-os. [link]
Ez egyébként távolról sem varázslat. Semmi olyan dolog nincs benne, amire fel kellene kapni a fejünket. Maximum azoknak számít komoly dolognak, akik abban a hitben élnek, hogy a VGA-n található x GB memóriát a mai programok valóban kihasználják és nem csak a felét-negyedét sikerül befogni. De ez a tény régóta ismert, tehát az, hogy egy hardveres megoldás képes a memória 100%-át hasznosítani nem lehet túlságosan megdöbbentő. Főleg azután, hogy ismerünk ilyen átállási folyamatot a CPU oldaláról, amikor szintén hasonló hatékonysági előrelépés történt.
Egy hosszú folyamatnak pedig egyáltalán nem része ez. Maga a rendszer a háttérben működik, lényegében a driver modellek alatt, tehát tulajdonképpen szükségtelen rá bármiféle optimalizálás. Egyszerűen a régi API-kban eleve a driver kezeli ezt, vagyis nagyon jól át tudja adni a munkát a hardvernek, míg az új explicit API-kban a program kezeli a menedzsmentet, és legrosszabb esetben is csak egy függvényt kell meghívni a programkódban, ami a driverben eleve megtalálható, és ez minden elintéz automatikusan.
Ami a hosszabb folyamatnak a része azok a tartalomkreálási lehetőségek. Mivel a HBC működése sokkal hatékonyabb, így esetleg kétszer vagy négyszer részletesebb textúrákkal is szállíthatóvá válik a PC-s port, mint amivel eredetileg számolt a fejlesztő. Na ez már egy tényleges munkával járó folyamat, de opcionálisan hasznosítható ez a lehetőség is. Valószínűleg erre az AMD majd köt külön szerződéseket a kiválasztott fejlesztőkkel, hogy pár játékban használják ki. De ez nem lesz általános, nem fog minden program ilyen lehetőségeket kapni, hiszen itt már egy olyan beállításról van szó, amit sima VRAM módban működő VGA-val esélyed sem lesz bekapcsolni, vagyis az egész munka eredményét csak a Vega tudja hasznosítani. Ehhez nyilván az AMD-nek ki kell nyitnia a pénztárcáját, hogy részben finanszírozzák a jobb minőségű textúrák elkészültét, de lényegében ilyen okból kötöttek szerződést a Bethesdával, hogy az R&D-t összevonják, és költség szintjén megosszák.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
válasz
 #85552128
#26829
üzenetére
#85552128
#26829
üzenetére
Ez egy hardveres technológia. Minden játék alatt ugyanúgy fog működni, mert nem a programkód, hanem a hardver vezérli, ráadásul minden játék alatt csont ugyanúgy. Ha a technológia rossz, akkor minden játék alatt rosszul fog működni, mert a szoftver ezt nem tudja befolyásolni.
De egyébként maga a probléma az implementáció szempontjából az, hogy a GPU-nak a virtuális memóriakezelését be tudják olvasztani a CPU-nak a virtuális memóriakezelésébe, mert a GPU később jött, és nem is igazán hasonlít egy CPU-ra. Viszont az implementációnak ez az egyetlen egy nehézsége, mondjuk ez elég nagy nehézség persze. Ugyanakkor, ha a mappelést megoldják, akkor hibázni nem tud a rendszer, végtére is egy már évtizedek óta működő szoftveres ökoszisztémára ültetik rá.
Szerk.: A Fury X-ben nem volt HBC. Nem tudom, hogy miképp jött ez ide. Ott arról volt szó, hogy a 980 Ti-t verni fogja, és azt magabiztosan teszi már.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
-
Abu85
HÁZIGAZDA
válasz
#85552128
#26834
üzenetére
Referencia Fury X ellen referencia 980 Ti nem jó? Vagy a 980 Ti-t tényleg agyon kell tuningolni, hogy a Fury X-et megverje? Ez hízelgő a Fury X-nek.

A Deus Ex: Mankind Divided és a BF1 AMD-s cím, a Resident Evil és a GoW NV-s, míg a Sniper Elite 4 független. Ez eléggé egyenlőnek tűnik. Persze gondoltam, hogy valami gond lesz a mérésekkel. Jöhetnek az "alternatív tények"!

[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
válasz
 SaGaIn
#26836
üzenetére
SaGaIn
#26836
üzenetére
Én csak az utóbbi fél év legjobban optimalizált öt PC-s játékát válogattam ki. Ügyelve arra, hogy két AMD-s, két NV-s és egy független cím is legyen benne.
Ja értem. Tehát felejtsük el ezeket a méréseket és álmodjuk meg a nem mért eredményt.

[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
válasz
#85552128
#26838
üzenetére
Tehát továbbra sem tartod fairnek a referenciát a referenciával összehasonlítani? Ezt nem értem, de gondolom ezért vagyok hiteltelen.
Szerintem ez a vita nem vezet sehova. A fenti linkekből vagy a Google-ből mindenki eldönti azt, amit akar és kész.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
válasz
TTomax
#26840
üzenetére
Mindegyik játék benyel annyi VRAM-ot, ami van a VGA-n. Ez manapság a meghajtók működésének alapja. Addig pakolják az adatot, amíg van hely. Ha 16 GB VRAM-os kártyák lennének, akkor azt is feltöltenék.
Számok azért nincsenek, mert nem akarták megmutatni, hogy mire képes a Vega számszerűen.
Demózhattak volna, de a hardver mindegyik program alatt pont ugyanúgy működik.
30 fps-sel került fel a Youtube-ra a videó. Persze, hogy ettől darabosnak nézhet ki.
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
válasz
 depzoo
#26861
üzenetére
depzoo
#26861
üzenetére
Mert folyamatosan csökkennek a VGA-k eladásai, tehát ugyanazt a bevételt kevesebb termékeladásból kell produkálni. Ezt csak úgy lehet elérni, ha drágábban adod a VGA-t. Ha ez sok, akkor vannak egy VGA áráért konzolok, amelyek nem igényelnek hardverfejlesztést.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
#26865
Abu85
HÁZIGAZDA
Petykemano
#26863
Abu85
HÁZIGAZDA
válasz
 Petykemano
#26863
üzenetére
Petykemano
#26863
üzenetére
Ha megnézed az éves szintű változásokat, akkor mindenkinek csökken az eladott darabszám. Néha van egy-egy jobb negyedév, de a hosszabb távú tendencia egyértelműen csökkenő, és ez már évek óta így van.
Ezen amúgy az Intelnek az MCM terve sem fog segíteni, mert a PCI Express interfészt fel fogja használni a proci mellé rakott GPU. Szóval az megint egy nagy zuhanás lehet, bár kérdés, hogy hova sorolják be ezeket az MCM-eket.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
-
Abu85
HÁZIGAZDA
válasz
 solfilo
#26914
üzenetére
solfilo
#26914
üzenetére
Ez az összehasonlítás azért nem jó, mert a Vega tud draw-streamet, tud packed mathot, tehát például a draw-stream annyira sokat is tud segíteni, hogy a feleannyi sávszélből sem érzi magát sávszélhiányosnak a rendszer. A packed math pedig effektíve duplájára emeli a számítási teljesítményét, tehát ilyen kódban 14 CU áll a 22 CU-nak megfelelő 11 NCU ellen. A GCN1/2 most kezd igazából kiöregedni, most jönnek azok a lehetőségek az API-ba, amelyek beépültek(-nek) a GCN3/4/5-be és ezekben pusztán szoftveresen rengeteg teljesítmény van.
GCN3/4 egyébként sokkal hatékonyabban fog küzdeni a GCN5 ellen, mert többet tud maga az ISA. De egyértelműen jóval többet fog érni egy GCN3/4 CU, mint egy GCN1/2 CU, egy NCU pedig sokkal többet tud.[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
-
Abu85
HÁZIGAZDA
válasz
 távcsőves
#26926
üzenetére
távcsőves
#26926
üzenetére
A shader intrinsics sem káros, ha szabványos. Mert már kezd átmenni szabványba, lásd SPIR-V kiterjesztések és shader model 6.0. A packed math pedig már szabvány, csak ironikus módon a hardver hiányzott hozzá. Illetve technikailag a double-rate hardver is megvolt a Pascal architektúrával, csak az NV letiltotta a fícsőrt. Nyilván arra gondolhattak, hogy egy Pascal Refresht el tudnak adni csupán ennek a funkciónak a bekapcsolásával, amiért még hardvert sem kell módosítani, mert benne van a lapkában, csak inaktív.
[link] - itt leírtam, hogy ezzel a packed math funkcióval hogy érdemes gyorsulást számolni.
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
válasz
 füles_
#26933
üzenetére
füles_
#26933
üzenetére
Nem lesz ráírva a dobozra a VGA-n található memória. Két opció van terítéken. Vagy a memória-sávszélesség lesz ráírva a HBC leírásával, vagy egy effektív érték, ami azt jelzi, hogy az a memória, ami rákerült mennyinek számít a régi pazarló modellel (a 4 GB így 12 GB-nak számít átlagban, míg a 8 GB 24 GB-nak). Utóbbi mellett vannak a gyártók, mert ilyen effektív értékekkel már játszik például a memóriapiac is. A 8 GHz-nek írt GDDR5 a valóságban 2 GHz, de mégis 8 GHz van ráírva.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
válasz
#85552128
#26935
üzenetére
A bírságok könnyen elkerülhetők, mert csak meg kell magyarázni, hogy miért írtad azt rá. Az ipar évek óta csinál ilyen effektív értékekre alapuló közlést, aminek a valósághoz igazából semmi köze, de valamilyen rejtett újítás miatt mégis közelebb áll az effektív vagy kamuérték a gyakorlati valósághoz.
Játékfüggő, hogy mennyi a haszontalan. Jellemzően a legjobban optimalizált játékokban a tartalom fele, míg a rosszul optimalizáltakban a tartalom 75%-a. Innen jönne szerintem a 66%, mert a legjobb és a legrosszabb eseteket átlagolnák. De szerintem ez egy rossz irány lenne, mert így pont a HBCC lényege veszne el, és csak egy hatékonyabb VRAM-nak lenne leírva. Pedig a HBCC igazi előnye az, hogy több TB-os kódolatlan textúraadatot is képes úgy kezelni egy 8 GB-os HBC-vel, hogy nem kell hozzá TB-nyi rendszermemória. Erre készül egy ezt bemutató demó. Szóval én eléggé ellenzem ezt az effektív VRAM-os, szorzásos, agyonegyszerűsített magyarázatot.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
válasz
#85552128
#26938
üzenetére
A HBCC pont itt jelent a mai hardverekhez képest orbitális előnyt, mert amíg a mai hardvereknél az allokáció törlése igen drága mulatság, akár jelentős többletterheléssel is jár, addig a hardveres menedzsment ingyen dolgozik. Mivel ma az akadások jelentős része abból keletkezik, hogy a VRAM-ban töröl egy allokációt a szoftver, így a HBCC azoknak kifejezetten ajánlott, akik ettől a falra másznak, mert hardveres menedzsmenttel az allokációk törlésének nincs többletterhelése.
A driverben vannak jó ötletek, de az annyit csinál, hogy leszed egy 512 MB-os részt a VRAM-ról, és ott a szoftveres menedzsment többletterhelés nélkül törölhet. Ez addig hasznos, amíg ebben az 512 MB-os részen belül lehet tartani az adatmenedzsmentet, de manapság ezt nem lehet normálisan megoldani.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
-
Abu85
HÁZIGAZDA
Nem feltétlenül kell egy sor sem. Épp most került el, hogy GDC-n volt róla szó, hogy a mostani DX12/Vulkan címek nem tartalmaznak nagyon extrém stratégiát a memóriamenedzsmentre. Szóval a legújabb tesztek szerint még módosítani sem kell a legtöbb explicit API-s alkalmazást, hanem a driver meg tudja oldani maga a hardveres menedzsmentre vonatkozó rendszer aktiválását. Elvileg az AotS és a Deus Ex Mankind Divided igényel csak egy sornyi módosítást. A többi programnál sikerült megoldani az out of box működést, akármilyen API-val.
Van egyébként egy meghajtó, ami VRAM-hoz hasonlóan kezeli a HBC-t, valószínűleg azt is odaadják majd tesztelésre, hogy ellenőrizni lehessen a gyakorlatban mit tud az új rendszer. Ugyanakkor publikus release szinten csak HBCC-t kezelő driver lesz, tehát a hagyományos VRAM modellhez szükséges menedzsment hiányzik majd belőle.[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
válasz
 Ren Hoek
#26965
üzenetére
Ren Hoek
#26965
üzenetére
Teljesen mindegy igazából az API. Az adatok megjelölése a lényeg. DX11 alatt ez nagyon könnyű, mert a drivernek teljes uralma van efelett, tehát DX11 alatt tökéletesen tud működni a HBC. DX12/Vulkan alatt lehetnek problémák, de a jelenlegi adatok szerint a mai felhozatalból csak három játék érintett, és azokban már benne is van a HBCC támogatása, még akkor is, ha hardver nincs még rá.
A lényeg az, hogy ha egy program DX6-11/OpenGL API-t használ, akkor a HBCC automatikusan aktiválódik. DX12/Vulkan alatt akkor, ha az adott rendszer streaming modellje a rendszermemóriára épít, mert ekkor automatikusan ki van jelölve a rendszermemóriának egy allokált területe, ahonnan a manuális menedzsment betöltheti az adatokat. Nyilván ebből a kijelölésből a hardveres menedzsment is tud dolgozni. Akkor van gond, ha valami nagyon speciálisat csinál a manuális menedzsment DX12/Vulkan alatt, ilyenkor a programba kell egy sor, ami a HBCC-nek kijelöli az adatokat.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
válasz
Ren Hoek
#26970
üzenetére
Jelenleg három játékba kell beírni azt az egy sort utólag, és ezeket már be is írták.
A jövőben azért érdemes erre az egy sorra építeni, mert ez csak egy copy-paste a Vegára vonatkozóan, míg ha ezt nem írják be, akkor hetekig tartó optimalizálásra van szükség a fejlesztő oldaláról, ami mondjuk specifikusan a Vegára akár száz sort is jelenthet. Ehelyett jóval célszerűbb az automatikus menedzsmentet választani. Ez az irány egyszerűen sokkal olcsóbb. Nem mellesleg nagyon jó viszonyítási pont is, hiszen a fejlesztők a Vega hatékonyságán látni fogják, hogy a saját manuális kódjuk mennyire van lemaradva a többi hardveren, és ezt az adatot felhasználva tudnak rajta fejleszteni.
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
-
-
Abu85
HÁZIGAZDA
válasz
 Valdez
#27199
üzenetére
Valdez
#27199
üzenetére
Az csak megdobná a kártya árát úgy 150 dollárral. A GDDR5X jelenleg drágább, mint a HBM2. Az a probléma vele, hogy hiába ugyanaz a karakterisztikája, mint a GDDR5-nek, senki más nem gyártja, így a Micron annyit kér érte, amennyit akar. És sajnos annyit is kérnek érte, hogy már ne érje meg újként bevetni, mert a HBM2 is olcsóbb lett nála. Jelen formában ugyanakkora kapacitású GDDR5X lapka ~tízszer drágább, mint a GDDR5-ös társ.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
válasz
 -Solt-
#27253
üzenetére
-Solt-
#27253
üzenetére
Igen. A VGA-piacon voltak radikális változások, amelyek megkezdtek egy új GPU-s korszakot.
Az első generáció szimplán volt a grafikus chip, amikor még a proci számolta a geometriát és a megvilágítást. Azután a második generáció volt a T&L bevezetése, vagyis a GPU megteremtése (GeForce 256-tól). A harmadik generáció a programozhatóság biztosítása, vagyis a shaderek bevetése (GeForce 3-tól), míg a negyedik generáció a unified shader modell (GeForce 8-tól), vagyis az általános programozhatóság korszaka, és ebben vagyunk még most is. Az ötödik generáció a Vegával jön, ami a bevezeti a "general purpose memory paging" modellt.
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
#27268
Abu85
HÁZIGAZDA
szmörlock007
#27267
Abu85
HÁZIGAZDA
válasz
 szmörlock007
#27267
üzenetére
szmörlock007
#27267
üzenetére
Elvileg be. Ennek az előzetes verziója már a GP100-ban is ott van, de csak a CUDA-ra működik.
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
válasz
#85552128
#27384
üzenetére
Igen, csak az nem architektúrára vonatkozó generáció, hanem konkrétan termékgeneráció. Ilyen formában az egész egy lényegtelen tényező, mivel annyi termékgenerációt lehet csinálni, amennyire a piac vevő lehet. Ez leginkább egy döntés kérdése, nem pedig a fejlesztésé.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
válasz
 dergander
#27390
üzenetére
dergander
#27390
üzenetére
Közel sem lesz ez success. Csak még nem ütköztél a változásokba bele. Attól, hogy ugyanannyi shader van benne, még nem ugyanaz a lapka. Új a memóriavezérlő, és új az UVD. Emellett több utasítás büntetőciklusa is csökkent. Amint meghív egy új dolgot a rendszer, azonnal problémád lesz belőle, mert arra számít a mikrokód, hogy a kártyádon Polaris 20 van, nem pedig Polaris 10 GPU. Még talán a büntetőciklusok redukálását túléli, de a hiányzó fixfunkciós blokkokét és vezérlőkét nem.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
válasz
#85552128
#27422
üzenetére
Miért ne indult volna el? Nem a GPU-t tervezték át a nulláról, hanem raktak bele pár extra áramkört. A korábbi mikrokódot pedig kiegészítették ezeknek az extra áramköröknek a kezelésével. De a mikrokód 99%-a lényegében ugyanaz, ahogy a lapka 99%-a is. Akkor lesz gond, ha hozzányúl ahhoz az 1%-hoz.
Nyilván a tuning az új kalibrációjú AVFS miatt szintén gond lehet, hiszen a Polaris 10 nem tartalmaz LDO-t.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
válasz
#85552128
#27424
üzenetére
Micsodát? Ott van világosan, hogy van egy köztes órajelszint a memóriánál. Emiatt nem max órajelre kapcsol a memória, hanem a max órajel felére. Ehhez memóriavezérlőre vonatkozó változtatás kell, mivel az eddigi vezérlő csak két állapotot kezelt. A harmadik állapotnak tehát kell egy extra slot a hardverbe.
A fixfunkciós blokkok az UVD-be a Bristol Ridge APU-ból kerültek át. Ezeket az AMD kihagyta régebben a dGPU-knál, mert nem tartották fontosnak, viszont a shaderek post-process számításnál sokat fogyasztottak. Emiatt az új Polaris GPU-k megkapták a Bristol Ridge APU-knak ezt a hardverelemét. Nyilván nem az Isten döntött úgy, hogy mostantól keveset fog fogyasztani a hardver multimédiában.
Az LDO pedig a Summit Ridge-ből került át, ez az AVFS-nek egy kiegészítése. Arra jó, hogy kiterjessze a beállítható órajeltartományt. Ebből szedtek extra órajeleket, és ezt sem az Isten adta oda nekik.Azzal nem tudok mit kezdeni, hogy más nem magyarázza meg a változást, hanem egyszerűen annyit írnak, hogy optimalizáció. Na most optimalizációból nem lehet az ötödére/tizedére csökkenteni a multimédiás fogyasztást. Ehhez csoda kellene, de csodák nincsenek, így kapott az APU-ból egy már eleve létező és működő hardvert rá.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
válasz
#85552128
#27428
üzenetére
Az AMD a forrás. Ennél hitelesebbet én sem tudok. De ha neked jobban tetszik, akkor csoda történt, és az AMD mérnökei ráolvasással érték el, hogy a rendszer a töredékét fogyassza multimédiában.
Ott van a három állapot, csak nem minden körülmény között vált köztes állapotra. Valamikor elég az idle is, és ilyenkor inkább arra vált (de például komolyabb HEVC tartalomnál köztes állapotra vált). De az biztos, hogy van egy idle, egy max órajel fele és egy max órajelre vonatkozó állapot. Ezt még az Anand is leírta. [link]
Attól az órajeleket meg kell szerezni. Az nem csak abból áll, hogy meghúzod, hanem abból, hogy annak stabilnak kell lennie mondjuk Indiában is. Ehhez már komolyabb munka kell, mert az itthon stabil 1350 MHz, nem biztos, hogy az lesz kurvára nagy páratartalom mellett és 50 fokos hőségben.
Csak szólok, hogy az AMD-nél a post-process shaderek kategorizálva vannak. Nem mindegyik kártya futtatja ugyanazt, de ezt már többször leírtam régebben. Ha nem ugyanaz a shader, akkor még ugyanazon a GPU-n is lényeges lehet a fogyasztáskülönbség.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
válasz
#85552128
#27432
üzenetére
A state-eket tárolni kell a hardverben. Nem az értéket, hanem magát az állapotot. Ha két slot van a hardverben, abba nem tudsz három állapotot rakni, ahogy két pohárba sem tudsz három pohárnyi vizet tölteni. De a víz mennyiségét megszabhatod ettől, akár menet közben is. Tehát a BIOS-ban is nyilván átírhatók az állapothoz tatozó értékek. De a hardverben kell a slot hozzájuk.
A multimonitor fogyasztásnál ugyanaz a helyzet, mint a multimédiánál. Vannak olyan konfigurációk, ahol elég az idle, és vannak olyanok, ahol elég a köztes állapot, de olyanok is, ahol kell a max órajel. Erre vonatkozóan, viszont van egy ismert bug, ami miatt az erősen gyári tuningos kártyákon a köztes állapot nem aktiválódik több kijelzővel. Ez javítás alatt van.
A forrás az AMD. Nem tudok ennél közelebbit. De ha jobban tetszik a ráolvasásos csoda, akkor gondold azt, hogy ez történt, nekem olyan mindegy.
A 470 és a 480-nál a számolt shaderek eltérők. Volt régebben a driverben paraméterezhetőség az egyes post-process effektekre. Na most az már nincs a meghajtóban, hanem az AMD szabja meg hardvertől függően az értékeket. Később ez vissza fog kerülni, mert sokan szeretnék átállítani az alapértelmezett minőséget, mert a csúszkák egy 470-en nem ugyanott állnak, mint egy 480-on, de ezt ma nem lehet módosítani.[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
válasz
dergander
#27444
üzenetére
Nem tipikusan a feszültség a problémád. Nem ugyanaz a lapka van a 480-on és az 580-on. A Polaris 20-nak a büntetőciklusai az egyes utasítások után mások, mint a Polaris 10-nek. Ezt valamennyire próbálhatod korrigálni a feszültséggel, de egyszerűen fizikailag más GPU-ra való mikrókódot használsz most. Ez állandó probléma lesz. Lehet azon a limited cuccon akármilyen válogatott GPU, ha az fizikailag nem ugyanaz, ami van az új sorozaton. A kis változások is jelentősek lehetnek a mikrokód szintjén, és ez már instabilitást okoz. Érdemes visszafrissíteni azt a mikrokódot, amit a régebbi Polaris 10-hez terveztek.
(#27448) Yutani: Ezt nem tudom, hogy honnan veszik, de ilyen egy szóval nem hangzott el. Arról volt szó, hogy elvihetik a Samsunghoz is a gyártást, de első körben a GloFo a bérgyártó (ez az AMD-nek fontos, mert a WSA miatt van egy minimum rendelési követelmény, és amíg azt nem teljesítik, addig nem mehetnek sehova). Olyan sincs, hogy 14 nm FinFET+. LPP van, és továbbra is azt használják. A genre vonatkozó jelölés csak arra vonatkozott, hogy a Polaris 20-nál ugye új lapkát terveztek, ezért más dense libeket is használhattak, mint a Polaris 10-nél. Ez nyitja meg egyébként a Samsunghoz való utat is, mert a Polaris 10 dense libjei nem kompatibilisek a Samsung gyártástechnológiájával. A Polaris 20, 21 és 12 esetében már mindkét bérgyártóval van kompatibilitás a tervezőkönyvtárak portolása szempontjából.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
válasz
dergander
#27451
üzenetére
De meddig? Ezek nem ugyanazok a lapkák. Amint egy olyan funkcióra kerül sor, ami nincs benne a régi hardverben rögtön megpusztul a munkamenet. Ezért hangsúlyozta ki az AMD, hogy ezek új lapkák a pletykákkal ellentétben. Nem egyezik meg 100%-ig a régi fejlesztésekkel.
(#27450) stratova: Lehet, hogy berakják mobilba, de ott a VEGA a fókusz. Sokkal kevesebb helyet igényel.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
válasz
füles_
#27473
üzenetére
A Xavier van 2018 végére írva. Az egy Volta SoC. Annak a fejlesztése tart a legelőrébb. A GPU-knál a GV100 áll a legjobban. Ezeknél azért fontos, hogy a bevezetésük jóval tovább tart egy GeForce sorozatba szánt megoldásnál.
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
A Preyhez lesz igazítva a Vega bemutatása, nem pedig pontosan Prey megjelenésének napján lesz kiadva. A kettő között nagy a különbség. Sokan ezt megértették, de van aki ezt nem érti meg, és szándékosan próbálja hozzákapcsolni a Vega 10-et egy dátumhoz. Miért reagáljak az ilyenekre, nem az én dolgom?
Leírtam egyébként nemrég, hogy május közepén lesz egy rendezvény, ahol aránylag sokat mondanak majd a Vega 10-ről. Aztán lehet, hogy lesz még több rendezvény is, de a tényleges start egy E3 előtti különálló rendezvényen lesz. Az már nem csak bemutató, hanem megjelenés. Azt nem tudom, hogy a Prey-nek a Vega verziója hogyan áll, mert a játékba kellenek nem szabványos kódok, hogy a Vega képességeinek egy részét ki tudja használni. Ezek biztos nem lesznek benne megjelenésre. Gondolom majd a június elejére patch-elik fel.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
A Preynek azért van szerepe, mert ez az első játék, ami az AMD és a Bethesda új szerződése szerint született meg. Egy csomó R&D-t az AMD csinált a Bethesda helyett. Ez az egyik kulcstényező, hogy a Bethesda kiszervezze az anyagilag drága PC-s optimalizálás egy részét. A Prey tartalmaz Ryzen optimalizálást, de ez lényegében kimerül a sok magra skálázásban, illetve tartalmaz AGS4 kódokat, mint a Doom. Ez a Bethesdanak nem ismeretlen. És a Vega esetében lesznek olyan képességek, amelyeket valahogy kihasznál, például a packed math és a primitive shader. Az előbbi lehetőség futni fog GCN3/4/5-ön, míg utóbbi csak a Vegához jó.
(#27543) Szaby59: És írtam is, hogy májusban lesz egy bemutató. Úgy lesz ahogy a Ryzennél. Lesz egy leleplezés, aztán küldik a boltoknak, és lesz egy tesztekre vonatkozó NDA, ami egyben a fizikai elérhetőség pillanata is. A lényege ennek ugyanaz, mint a Ryzen esetében. Amint megjelenik már meg is lehessen venni. Természetesen a bemutató után elő is rendelhető, ahogy a Ryzen is az volt.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
válasz
TTomax
#27548
üzenetére
Nem a lapkaméreten múlik ez. Régen azért voltak a felsőházba szánt GPU-k nagyobbak, mert olcsó volt a 40-55-65 nm-es node. Ma egy 14/16 nm-es FinFET node-on átlagosan háromszor drágább ugyanakkora GPU-t gyártani, mint egy 28 nm-es node-on. Ergo ami a 28 nm-en 500-600 mm2 volt, az 14/16 nm-en ideális esetben ki kell hozni 300 mm2 körüli kiterjedésből. Főleg a TSMC-nél, amely cégnél nagy a túljelentkezés és az viheti a gyártósort aki többet ajánl érte. Ez a modell azért kellemetlen, mert egy előre kialakított WSA-s típusú szerződésnél akár 70-90%-kal drágább waferárat is eredményez. A 7 nm még drágább lesz. Ott már nem hiszem, hogy lesznek egyáltalán 600 mm2 közeli GPU-k. Nem azért, mert nem lehet megcsinálni, hanem azért, mert nem tudnád megfizetni, hiszen megint kétszer drágább lesz legalább a waferár, és ezzel a gyártási költség.
Az AMD is csak azért tud relatíve alacsony árat szabni, mert előre lefoglalt wafermennyiségük van, amiért jóval kevesebbet fizetnek waferenként, mint amennyit a TSMC-nek kellene fizetniük. Ha a TSMC-nél gyártatnának, akkor jó 50%-kal drágább lenne a teljes paletta. Nem tudnának mit csinálni, mert a TSMC-nél a wafer sokkal drágább, mint a GloFónál.
Valószínű az is, hogy 7 nm alá a GPU-k nem is mennek. Annyira drága lenne, hogy nincs értelme. Még a prociknál talán elmennek az 5 nm-ig, de ott is az a nyers határ. Tovább ott sincs a CMOS-sal.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
válasz
TTomax
#27551
üzenetére
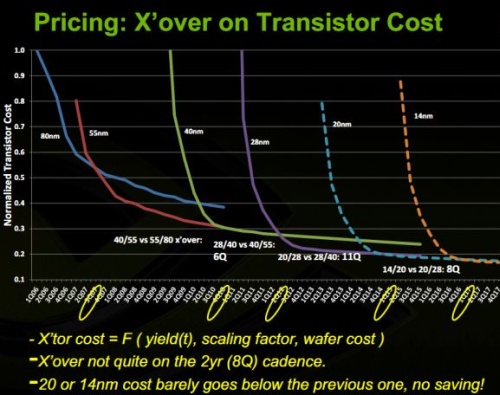
Itt egy nagyon jó kép az NV-től, amikor folyamatosan sivalkodtak a probléma miatt. Elég régi, de igen pontosan mutatta be a problémát, ami elő is állt.
Ezen láthatod, hogy régen minden egyes új node esetében csak az elején volt magasabb a normalizált tranzisztorköltség, amint elkezdték az adott node-ra a tömeggyártást meredeken lezuhant a waferár és ezzel a teljes gyártás költsége. Nem sokkal a tömeggyártás után az új node már a régi node alatt volt a normalizált tranzisztorköltségben. Na most 28 nm-en ennek vége lett. Iszonyatosan megnőtt az újabb node-ok fejlesztési költsége, és emiatt a waferárak az egekbe szöktek. Régen még kis előrelépést prognosztizáltak, de a valóságban az új node-ok normalizált tranzisztorköltsége sosem lett alacsonyabb, mint a 28 nm-es eljárásé.
Ez a gyakorlatban azt jelenti, hogy a TSMC-nél egy 16 nm-es lapka 3 milliárd tranzisztorral nagyjából ugyanannyi költségbe kerül, mint egy 28 nm-es lapka 3 milliárd tranzisztorral. Függetlenül attól, hogy a két node-nyi különbség a lapkák méretében erősen megmutatkozik. Tök mindegy tehát, hogy a lapka pici, a gyártás bedrágult, elég dulván. A költségérzékeny piacon azzal lehet spórolni, hogy megpróbálnak a megrendelők előzetes szerződést kötni a bérgyártóval, de a TSMC-nél akkora a túljelentkezés, hogy inkább versenyeztetnek, mint hogy előre, egy WSA keretében, fix áron kiadják a készülő gyártósorokat. Egyszerűen az viszi azokat, aki többet fizet értük, ezért drága nagyon a TSMC-nél a friss node-ra készült wafer. Egy GloFo vagy egy Samsung a WSA-ra vevő, mert az egy fix megrendelési tételt ad számukra, amire építhetnek. Ilyenkor a 14/16 nm olcsóbb lehet, mint a 28 nm-es node, de csak azért, mert a waferárat üzleti döntésként, kölcsönös előnyökkel levitte a két fél. Amúgy ugyanúgy drága lenne náluk is a node, csak ideiglenesen lemondanak a nyereség egy részéről, mert az a jövőben nagyobb nyereséget eredményezhet. Színtiszta üzleti döntés ez.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
válasz
TTomax
#27557
üzenetére
A waferárak jellemzően bérgyártóktól függnek. Az a baj, hogy például a GloFo és a Samsung a 14 nm-es FinFET wafert jóval olcsóbban adja, mint a TSMC a 16 nm-es FinFET node-ra. Emellett ugye ott az előzetes szerződés lehetősége, amely sokat faraghat a 300 mm-es waferárból. Például a GloFónak van ilyenje az AMD-vel a 14 nm-es node-ra. Tehát igen nagy eltérés lehet gyártási költségek tekintetében a megrendelőre nézve. Ezért jobb a normalizált adatsor, mert az az üzleti döntéseket nem veszi figyelembe.
Inkább a tranzisztorszámot nézd, mert arra vannak normalizált adatok. Tényleg nagyjából az a helyzet, hogy egy x tranzisztorból álló 28 nm-es GPU gyártása nagyjából ugyanannyiba kerül, mint egy x tranzisztorból álló 14/16 nm-es lapkáé. Hiába fér el sokkal több GPU a waferen, magának az újabb node-okhoz való wafernek ára sokkal drágább.
A problémán egyébként a 450 mm-es waferek bevezetése enyhít majd valamelyest.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.























Új hozzászólás Aktív témák
A topikban az OFF és minden egyéb, nem a témához kapcsolódó hozzászólás gyártása TILOS!
MIELŐTT LINKELNÉL VAGY KÉRDEZNÉL, MINDIG OLVASS KICSIT VISSZA!!
A topik témája:
Az AMD éppen érkező, vagy jövőbeni új grafikus processzorainak kivesézése, lehetőleg minél inkább szakmai keretek között maradva. Architektúra, esélylatolgatás, érdekességek, spekulációk, stb.
