- Crypto Trade
- Vodafone otthoni szolgáltatások (TV, internet, telefon)
- WLAN, WiFi, vezeték nélküli hálózat
- QNAP hálózati adattárolók (NAS)
- Vírusirtó topic
- Elveheti az USA a Chrome-ot a Google-től
- AliExpress tapasztalatok
- Sweet.tv - internetes TV
- DIGI kábel TV
- Szövetségi felügyelet alá helyeznék a Google-t
Új hozzászólás Aktív témák
-

S_x96x_S
addikt
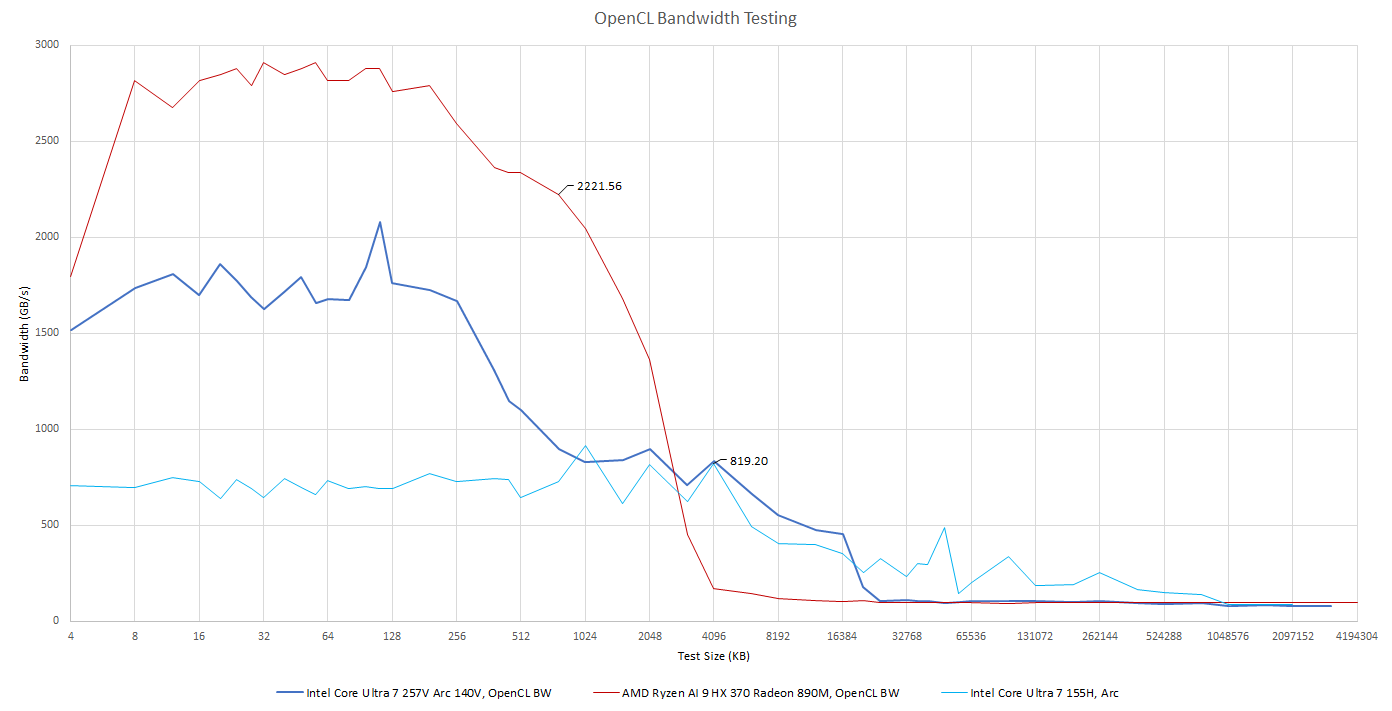
> Csak a képeket nézve a Strix Point a Lunar Lake-hez képest
> nagyon rosszul áll cache-ben minden szintena cache a latency alacsony tartása miatt van;
és az alapján már teljesen más következtetésre lehet jutni.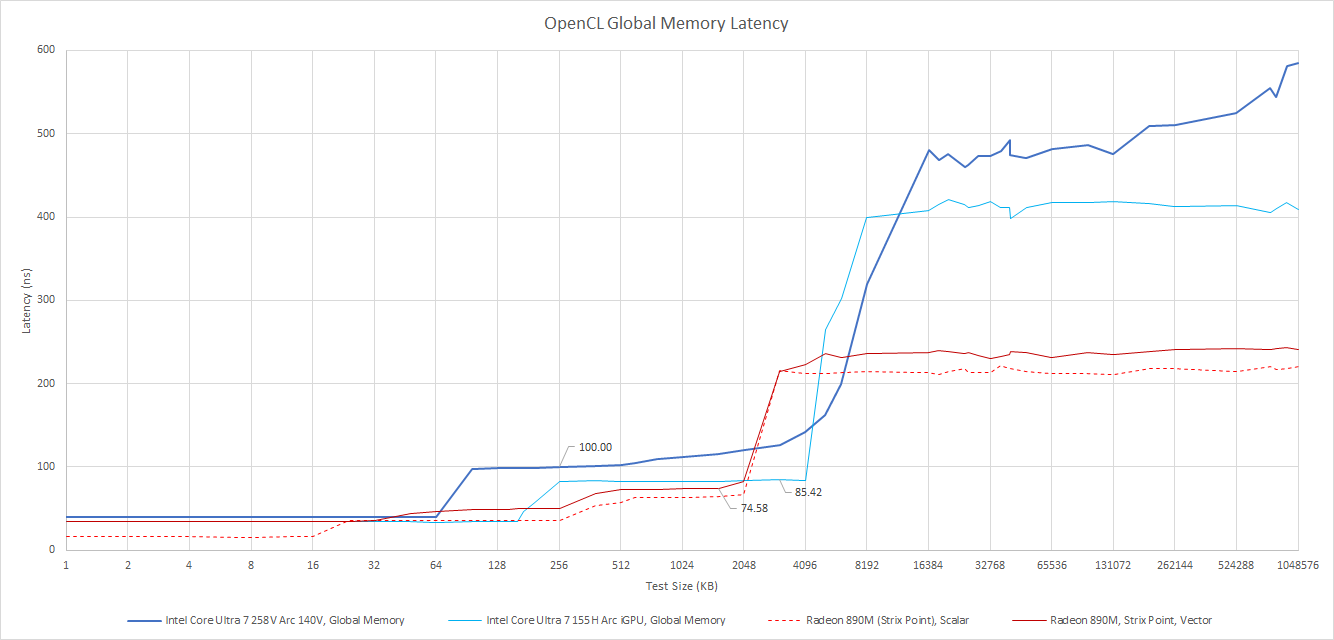
"Outside the Xe Core, Lunar Lake doubles L2 cache capacity to 8 MB. That’s the biggest L2 cache I’ve seen in a laptop iGPU so far. However, latency has substantially increased over Meteor Lake’s 4 MB L2. Lunar Lake also sees a weird uptick in latency well before the test approaches L2 cache capacity. It’s not address translation latency because testing with a 4 KB stride didn’t show a latency jump until 64 MB, implying a single thread has enough TLB capacity on hand to cover 64 MB."
"AMD’s Strix Point has a smaller but lower latency L2 cache. Even though the L2 is smaller, Strix Point has a lower latency penalty for accessing DRAM. On Lunar Lake and Meteor Lake, a GPU-side DRAM access has over 400 ns of latency. Strix Point’s iGPU can get data from DRAM in under 250 ns. Lunar Lake has a 8 MB memory side cache placed in front of the memory controller, but I can’t clearly measure its performance characteristics."
( via https://chipsandcheese.com/p/lunar-lakes-igpu-debut-of-intels )
[ Szerkesztve ]
Mottó: "A verseny jó!"
-

Abu85
HÁZIGAZDA
A cache-t a dizájn igényeihez tervezik. Szóval ez nem olyan egzakt dolog, hogy ha az egyikben ennyi van, akkor a másikba is kell. Az Intel azért épít sokkal több cache-t a dizájnba, mert sokkal kevesebb wave-vel dolgoznak, így nekik sokkal ritkább, hogy át tudják lapolni a memóriaelérés késleltetését. Az AMD dizájnja sokkal jobban reagál ezekre a helyzetekre.
Alapvetően ezért van az is, hogy bizonyos játékokban nagyon szar az Xe2, míg bizonyos játékokban nagyon jó. Általában ott jó, ahol a játék shaderei úgy vannak megírva, hogy van alkalmazva némi optimalizálás a lokalitási elvre. (szerencsére a legtöbb AAA cím már ilyen, mert van némi haszna mindegyik dizájnon) Ha nincs, akkor ott nagyon rosszul viselkedik az Xe2, mert hasztalanná válik benne a sok cache.
Az AMD-féle RDNA3 másképp működik, sokkal kevésbé érzékeny arra, hogy milyen optimalizálást alkalmaz egy shader, inkább csak az számít neki, hogy jó legyen a regiszternyomás, és ha az jó, akkor igazából a sebesség is jó. Az Xe2 legalább négy-öt külön tényezőre érzékeny még, és ha az egyik nem jó, akkor a sebesség sem lesz jó.Ez majd az Xe4-ben fog megváltozni, mert az már sokkal inkább hasonlítani fog azokhoz a GPU-dizájnokhoz, ahogyan tervez az AMD és az NVIDIA. Ezáltal nem kell sokkal nagyobb lapkaterületet használni egy adott teljesítményszint eléréséhez, ami az Intelnek egy elég nagy baja jelenleg, mert ki kell tömni a dizájnt cache-sel, hogy működjön, és akkor is csak akkor működik, ha a program erre van optimalizálva.
Pontosan ez volt például a gond a Starfield esetében. Annyira specifikusan csak a regiszternyomásra optimalizáltak, hogy az Arc sebességét máig nem tudták összerakni.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.



Új hozzászólás Aktív témák
A topikban az OFF és minden egyéb, nem a témához kapcsolódó hozzászólás gyártása TILOS!
Megbízhatatlan oldalakat ahol nem mérnek (pl gamegpu) ne linkeljetek.

Állásajánlatok

Cég: PCMENTOR SZERVIZ KFT.
Város: Budapest