A Google sok vitát kiváltó könyvdigitalizálási programja a feladat nagyságát és a hihetetlenül gyorsan szaporodó adatbázist tekintve nyilvánvalóan egy sajátos technológia kialakítását követelte meg, s ez így is történt: a hatékony megvalósításhoz a Google kidolgozott egy eljárást annak érdekében, hogy a dokumentumokat gyorsan, ugyanakkor kiváló minőségben tudják digitalizálni. Ezt a megoldást szabadalmaztatták is, s a védettséget tavaly márciusban kapták meg rá, ahogy erről akkoriban be is számoltak a szaklapok. Ám a részletekről alig derült ki valami, s ezért érdekes a scitedaily.com friss cikke, melyben arról számolnak be, hogy a Tokiói Egyetem kutatói kidolgoztak egy szkennelési eljárást, mely nagyon közel áll a Google által alkalmazotthoz. Ahogy a lap írja, azt nem tudni, hogy a Nakasima, Vatanabe, Komuro és Isikava által kifejlesztett megoldás született-e meg előbb, vagy az amerikaiaké, de az valószínűsíthető, hogy a két módszer alig tér el, s mivel a japánok technológiája nyilvános, így az érdeklődők megismerhetik az ipari méretű, jó minőségű digitalizálás kulisszatitkait.
Hogy az összevetés megalapozottságát bizonyítsák, a scitedaily.com munkatársai közlik a két technológia alapelveinek szabványleírását, s ebből kiderül, hogy szinte teljesen azonos módon gondolkodtak Tokióban és Kaliforniában.
Ezek az új technológiák már nem a szkennelés alapelveivel foglalkoznak, hiszen azok már rég ismertek (egy kézenfekvő bizonyíték erre a Mátyás király Corvináit digitalizáló projekt, melynek eredményeképp ezek a roppant nagy értéket hordozó könyvek már elérhetőek az interneten keresztül is), a megoldandó probléma az volt, hogy miképpen lehet nagyon jó minőségű digitális képeket készíteni papíroldalakról nagyon gyorsan. Aki már végzett ilyen jellegű munkát, az pontosan tudja, hogy három komoly problémával kell szembenézni egy könyv digitalizálásakor. A legtöbb kereskedelmi forgalomban kapható, úgynevezett face-down szkennernél a beolvasandó oldalt rá kell fektetni egy üveglapra, hogy a beolvasó láthassa. Ennek következtében:
- ha jó képet akarunk, nyomást kell gyakorolnunk a könyv gerincére, hogy a lehető legtökéletesebben feküdjön fel az üveglapra, s bár ezt tökéletesen sosem sikerül, minden ilyen fizikai hatás rongálja a fűzött/kötött könyv állagát (éppen ezért gyűlöli sok könyvtáros a digitalizálást, s az egy példányban létező dokumentumok esetében – amelyeket olykor olvasáskor teljesen kinyitni is tilt a szabályzat – nem is engedélyezik)
- a munkafolyamat igen lassú, hiszen a kinyitom-felfektetem-beolvasom-felveszem-lapozok-visszarakom fázisok végrehajtása a végtelen unalom mellett borzasztó időigényes is
- az első pontban említettek miatt a képek minősége mindig egyenetlen, mivel a nem tökéletes felfekvés következtében az oldalak szélei, közepe, illetve a hajtás melletti rész más-más távolságban van a leolvasótól (épp emiatt alkalmazták/alkalmazzák azt a könyvtáros szemmel nézve barbár módszert időnként, hogy ha több példány is van egy adott dokumentumból, akkor egyet „beáldoznak”, s a kötést szétvágva lapokra szedik szét, így ez a probléma nem jelentkezik a szkennelésnél)
E komoly gondok megoldására fejlesztették ki az úgynevezett face-up szkennereket, melyeknél a könyv normális állapotban fekszik egy sík felületen, és a kinyitott oldalakat felülről fényképezi le egy kamera. Ezzel a megoldással a fentebb említett első két problémát ki lehet küszöbölni, ám a harmadikat még nem, mivel az ívelt oldalak egyes részei itt is más-más távolságban vannak beolvasótól, lencsétől. E technológiákat úgy lehet tökéletesíteni – s mind a Google, mind a japánok innovációjának ez a tartalma –, hogy valamiképp korrigálják a torzításokat.
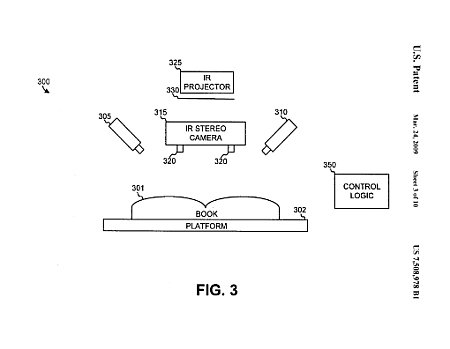
Ezt úgy sikerül elérniük, hogy a szkenneléshez több helyről világítják meg az oldalakat, s a felvételeket sem egy kamera készíti. A Google szabadalmi leírásában látható, hogy két nagy sebességű kamera dolgozik, az egyik a nyitott könyv jobb oldali, a másik a bal oldali lapját fényképezi. Amint elkészül a felvétel, egy projektorral megtámogatott sztereoszkopikus infravörös kamera is készít egy képet a két oldalról, mégpedig úgy, hogy a projektor egy labirintushoz hasonló mintát vetít ki az oldalakra, mely alapján egy erre a célra rendszeresített számítógép (control logic) kiszámítja a lapok görbületét, s ez alapján lehet korrigálni a végső képet. Ez az eljárás már nem bonyolult: megépítik az oldal 3D-s modelljét, majd ezt „visszalaposítják”.

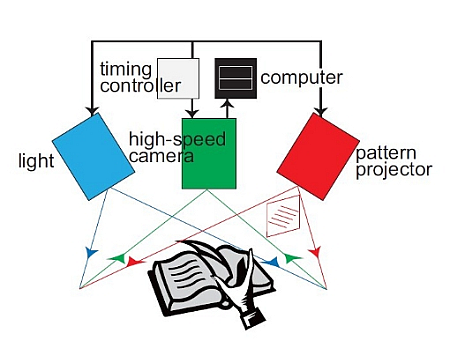
A japán megoldás is hasonló elveken alapszik, ám ők csak egyetlen kamerával dolgoznak, ez a kamera végzi el mindazt a munkát, amit a Google módszerénél három eszköz.
A Google emellett levédetett még egy digitalizálási eljárást, s erre november közepén meg is kapták a szabadalmat, mely az emberi hibákat igyekszik kiküszöbölni a szkennelés során. A legtöbb hiba ugyanis abból adódik, hogy a lapozgatás még e fejlett digitalizálási módszereknél is végtelenül unalmas emberi feladat, és a monotóniából következően előfordulhat, hogy például egyszerre két oldalt lapoznak a munkatársak, vagy bennfelejtik a kezüket, ujjukat exponáláskor. Ezért kifejlesztettek egy ellenőrző rendszert, mely a szkennelést hangjelzésekkel követi, s tévedés esetén hangjelzéssel figyelmeztet. Igaz, egyre inkább terjedőben van a lapozás robotizálása, bizonyos esetekben a Google is használ már ilyen technológiát, de ez még kiforratlan, mert még a legjobbak is lassabbak, mint az ember, s a lapokkal sem bánnak olyan kíméletesen, ahogyan az emberi kéz képes.








