- Az USA nem akarja visszafogni Kína növekedését
- Mikrotik routerek
- Milyen routert?
- 1000 kilométert mehetnek az EV-k az új CATL-akkuval
- WLAN, WiFi, vezeték nélküli hálózat
- Mesterséges Intelligencia topik
- Kínai cégek segítik ezentúl a Teslát, a Renault-t, a Hyundait és a Toyotát
- Crypto Trade
- Alternatív kriptopénzek, altcoinok bányászata
- Synology NAS
Új hozzászólás Aktív témák
-

DraXoN
addikt
megválaszoltad a kérdést, a költségek az ok, mivel a zen elsődlegesen nem az asztali igényekhez készül, de az építőelemei azt tudják amit, így asztalra "lehozva" használható a bekerült tudás, vagy csak letiltható, de külön egységet tervezni sok pénz, amit amd akár máshova is eltudna költeni (pl. 3d stacking), így nem fog szerintem külön chippet tervezni asztalra. lesz egy kisebb IO és max 2 cpu chiplet.
az epic1 inkább "demo" jellegre sikeredett, kb az összes elérhető chippet a nagy cégek vásárolták fel, mint a fehér holló, lett a szerverek "konzumer" piacán. de asztali cpu-k esetén is néha egyik-másik modell nem elérhető, párszor már előfordult (főleg a 2600/2600x érintett).. egyszerűen úgy néz ki nincs elég gyártókapacitás teríteni a piacot.
nem véletlen, hogy mikor jön a zen2 se szűnik majd meg a korábbi cpuk gyártása, sokaknak elég az, és kicsit tehermentesítheti a zen2 sorokat.de a 12mag főlé menésnek most még lehet nincs értelme, anno pl. az FX cpu-k 8 szállja is erősen kihasználatlan volt, de manapság egyre inkább jól érzik magukat.. pár éve én is úgy gondoltam utóbbit lecserélem, de az új generációs játékmotorokkal kapott egy új lendületet ami simán kiszolgál egy középkategóriás vga-t (hogy utóbbi legyen a "limitáló"). Munkára meg mostanában messze jobb mint a kortárs intel cpu-k, azokat esetemben borzalmasan megfogja a specre patch (a munkám miatt sok IO művelet van a rendszeren, mert a munkakönyvtáram folyamatos szinkronban van egy távoli szerverrel, ezt nem szeretik az intel cpui mostanság...)
The human head cannot turn 360 degrees... || Ryzen 7 5700X; RX580 8G; 64GB; 2TB + 240GB + 2TB || Samsung Galaxy Z Flip 5
-
#52
 Petykemano
veterán
joysefke
#48
Petykemano
veterán
joysefke
#48
Petykemano
veterán
Még a bulldozer idejében voltak viták arról, hogy az SMT vagy a CMT megközelítés hatékonyabb-e. Jellemzően mindkettő 2 szál kezelésére alkalmas felépítésű. A CMT ugye arról szól, hogy a 2 szálat feldolgozó rész viszonylag kevés erőforráson osztozik, eléggé szét van választva. Cserébe a szálakat feldolgozó részek/oldalak háborítatlanul tudnak működni, nem versengnek egymással, és egyszerű felépítésűek, ezért tud pörgös és energiahatékony (khm-khm) lenni.
Az SMT abból indul ki, hogy egy széles (sok feldolgozót tartalmazó) magra indít két szálat. Itt a megosztott erőforrás vastag, a szálak versengnek egymással a processzor erőforrásainak használatáért.
(Elég részletes leírás itt)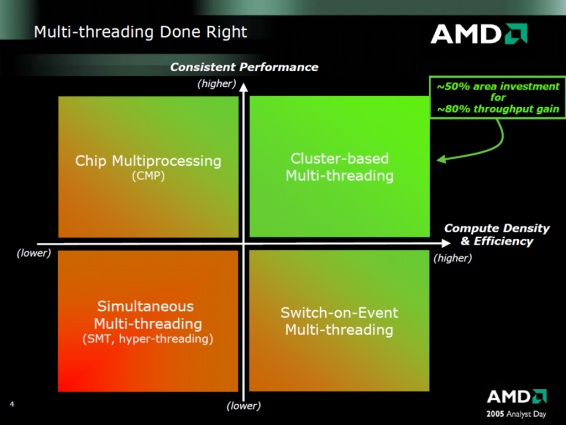
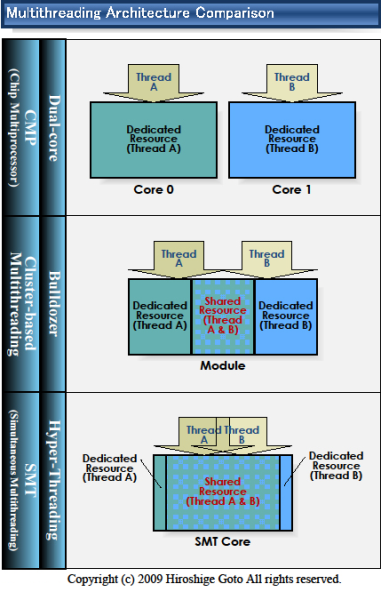
Az érvelés mindig valami olyasmi volt, hogy az SMT többlet-szilikon igénye 5% lehet, a yield pedig 20-30%
(Azoknál a programoknál, amelyeknél nem számít az egyszáles teljesítmény, mert valójában 1db 100%-os (potenciál) szál helyett a 2db az erőforrásokért versengő 60-65%-os (a ST potenciálhoz képest) szál fut)A CMT pedig mintegy 50% helyigény mellett 80%-os teljesítménytöbbletet adott 1 szál helyett 2 futtatásával.
Most itt nekünk az persze a CMT és az SMT kérdése már rég nem érdekes, csak az, hogy az SMT implementálása 5%-os többlettel jár.
Ez azt jelenti, hogy a szálkezeléshez dedikált részegységek csupán mintegy 5%-át tehetik ki lapkának, illetve SMT implementálása esetén ~10%. Tehát az SMT4-hez további 10% lehet szükséges.
Az SMT letiltását (ami ugyebár a szilikon 5%-ának elpazarlását jelenti) eddig is megtették Az AMD oldalán most ugyan nem gyakori, de az intel mostanában előszeretettel él vele. Az AMD nem sajnálta a szilikont a zeppelinből sem, amikor olyan részeket pakolt bele, amelyeket csak a szervereknél, illetve theadrippereknél használtak, AM4 tokozásnál nem.
Szóval én ezt a 10% többletet nem látom olyan nagy veszteségnek, ami miatt külön kéne választani a szerver és konzumer piacra tervezett lapkákat. Még csak letiltani sem feltétlenül kell, annyit kellene csupán csinálni, hogy AM4 alaplapok esetén a default az SMT2, de bátrak adott esetben átállíthatják 3-ra, vagy 4-re.Ha valahogy ügyesen csinálják, akkor esetleg még azt is megoldják az alábbi képen zölddel jelölt statikusan partícionált erőforrásokat a BIOS beállítás alapján partícionálják, vagyis 4 helyett 3 vagy 2 vagy 1 szált engedélyezése esetén a a 3, 2, vagy 1 szálnak azokból is több/nagyobb áll rendelkezésre. Így dekstop (SMT2) még Single Thread szempontjából még kevesebb az elvesztegetett erőforrás a "letiltás" miatt

Ami miatt ez az egész SMT4 számomra sokkal nagyobb kérdés, az az, hogy szerintem a Zen jelenlegi feldolgozóira nézve egy harmadik és egy negyedik szál már nagyon kicsi yieldet hozna.
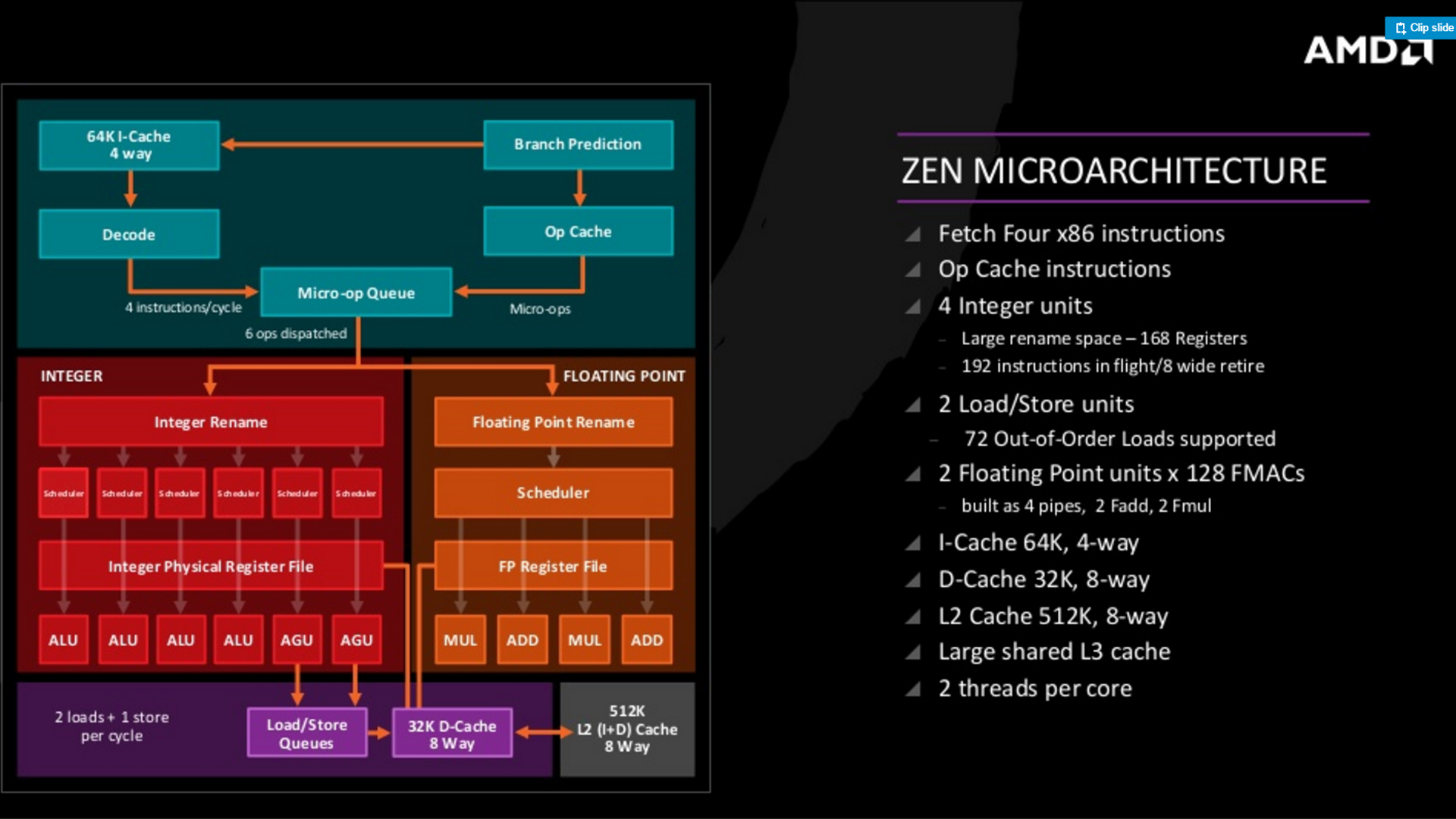
Itt van az integer pipeline-ban 4 ALU és 2 AGU, és van FPU: 2x128bites FMAC 4 pipe: 2 add és 2 MUL
Van egy ilyen is: "Dispatch is capable of sending up to 6 µOP to Integer EX and an additional 4 µOP to the Floating Point (FP) EX. Zen can dispatch to both at the same time (i.e. for a maximum of 10 µOP per cycle)." (src)És a zen esetén így hoz az SMT 40-50% többletet. Ami azt jelenti, hogy természetesen a zen backendje erősebb, szélesebb, mint a frontend - a frontend 1 szálon nem tudja maximálisan kihasználni a backend kapacitásait.
Ezen - a frontenden - a zen2 nyilvánvalóan javít:
Ha majd méri valaki a zen2 SMT hatékonyságát, akkor derülhet ki, hogy a zenben az SMT 50%-os yieldje mennyire pörgette ki a backendet a limitig.
Ha a zen2 a frontend javításával továbbra is 50% körüli SMT yieldet ér el, akkor a backendben még van lóerő.
Igazából ha SMT4-gyel mondjuk még 25% throughputot el lehet érni, az már lehet, hogy megéri (+25% throughput +10% szilikon árán)
az IBM power8 esetén a yield SMT2-ről SMT4-re 50% volt, így a 4 szálas throughput majdnem két és félszerese volt az 1 szálasnak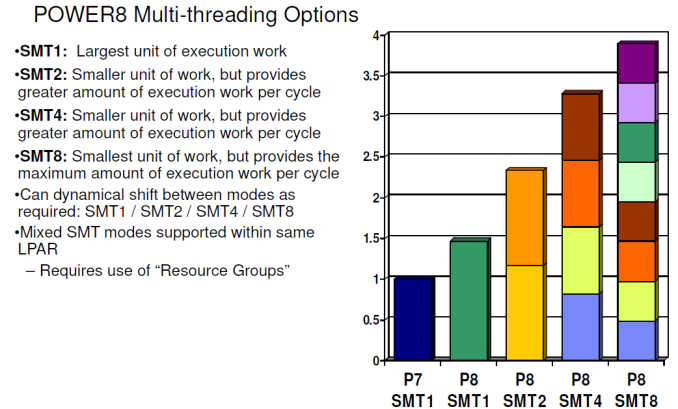
Persze az igazsághoz hozzátartozik, hogy a power szerver architektúra, ott kvázi megengedhető, hogy az egyszálas teljesítményt kicsit lazábban kezeljék és az IBM processzoraiban ez így is történik, ahogy azt az egyik kolléga linkelte is a cikkben, hogy az SMT4 humbug.
Tehát én jelenleg inkább meglepődnék, ha a zen jelenlegi backendjére ráengednék az SMT4-et. Ehelyett arra számítok - abban bízok -, hogy szélesítik az architektúrát. Egyrészt 4 ALU helyett mondjuk 5, vagy 2 AGU helyett 3, vagy 4 ALU, 4 AGLU (lásd piledriver) és az FPU oldaláról pedig azt várnám, hogy a 256bit, majd az 512 bit vektorutasítások végrehajtására úgy készítsék föl, hogy azokban 2, illetve 4 128bites utasítást - akár ha azok különböző szálakból jönnek is - végre lehessen hajtani egy ciklus alatt.
Így a backend megint fölénybe kerülne, de desktop vonalon ha az SMT4-nek, nem feltétlenül, de SMT3-nak is lehetne értelme, amíg a frontend felzárkózik.
Találgatunk, aztán majd úgyis kiderül..






Új hozzászólás Aktív témák

ph Itt sincs a második generációs EPYC, de már harmadik generációs fejlesztés előkészítése zajlik.
