Új hozzászólás Aktív témák
-

frescho
addikt
Az 1modul=1.5 mag kicsit poen volt, nem kell erte harapni. Ha megnezed a hozzaszolasaimat, akkor tobbszor leirtam, hogy inkabb hivom 3 modulosnak, mert a 6 magot tulzonak talalom. 3 magnal meg joval erosebb es nem is igaz, hogy 3 magos. Szerintem maradjunk a modulnal.
A bull mag nem teljes erteku, de marketingkent eladhato. A bull modul/mag felepites legjobb esetben sem eri el az AMD altal deklaralt 80%-os teljesitmeny novekedest. A legtobb, amit mertem -41.55% lassulas 1 mag/modulnal, ami atszamolva 1.71 gyorsulast jelent. Tisztan integer terhelesnek a kernel forditas tekintheto, ahol ennel kisebb a kulonbseg (1.49). Tehat ha elmeletben ket kulon magkent is mukdik, a gyakorlatban nem kepes hozni az elvart/beigert gyorsulast.
Szerintem nincs igazan nagy problema a magokkal es fikent nem a flexFP-vel, de a frontend nem tudja etetni oket. Erre utal az is, hogy a steam rollernel a decodereket duplazzak, novelik az L1 cache-t.
[ Szerkesztve ]
https://frescho.hu
-
frescho
addikt
Az emberek tobbsegenek tok mindegy, lehet benne 2 mag vagy 32, csak repesszen a legujabb agyonlolek 13. Ha a felepitest nezed, akkor sem igaz a ket mag, ugyanis fontos reszek kozosek, azok nem dedikaltk. A regiszterek es a vegrehajtok igen, de a frontend miatt nem mondanam nyugodt szivvel, hogy ket mag. A flexFP viszont zsenialis huzas szerintem. Erdekes, de a steam rollernel visszalepnek a teoriaban a kulon-kulon dekoderrel, tranzisztorokat pocsekolnak, hogy a jobban kihasznaljak a ket "majdnem" magot.
Teljesitmeny szempontjabol nem hozza a 80%-ot. Talan lehet talalni egy vagy ket programot, ahol igen, de atlagban talan a felet ha fel tudja mutatni. Ebben termeszetesen benne van a programok multithread tamogatasanak hianya is reszben, de az is, hogy szuk keresztmetszet van a modul felepiteseben.
Azt hiszem nem kell magyaraznod, hogy mi a modulok mogotti elmeleti megfontolas. Szimplan nem skalazhato a regi felepites es a sok szal fele indultak el. Az altalanos CPU-nal is , de a masszivan parhuzamosithato, GPU-ra tolhato szamitasoknal fokent. Az otlet tenyleg jo, csak a kivitelezessel, illetve a szoftver oldallal vannak gondok jelenleg:
- Magasabb a fogyasztas, alacsonyabb az orajel, nem igazan energia hatekony (APU-nal, ha kihasznaljuk a GpGPU-t, akkor ez mar nem igaz.)
- A modulokban a kozos reszeknel bottlenecket vezettek be (Reszben kivasaljak a steamrollerrel)
- A programok jelentos resze meg mindig keves, de gyors magot igenyel (A jatekfejlesztok tamogatasa egy fntos teruletet valtoztat meg ilyen teren.)
- A GpGPU meg mindig csak kamaszodik (De mar kamaszodik )
)https://frescho.hu
-
frescho
addikt
Pont ezert irtam, hogy az FP szerintem zsenialis. A frontend viszont jelen esetben szuk keresztmetszet. Erre jo pelda a kernel forditas, ahol nem fogsz FP utasitasokat talalni, max csak elvetve, tehat marad a fronted, a memoria es a diszk alrendszer, mint szuk keresztmetszet.
A memoriat es a merevlemezt kilonem, mert a modulok szamaval aranyosan skalazodik, de a mag/modullal nem. Lehet meg a cache is, ami eleg 3 maghoz, de hathoz mar nem, de 2 modullal is hasonlo eredmenyre jutottam, sot egyel sem sokkal jobb az arany.
Tehat 1 K10 mag vs. 1 Bull modulra gondolsz? Igen, ott van amiben hozza, de ez nem tisztan a modulos felepites erdeme, eleg sok uj utasitas es mas optimalizacio is benne van a kepben. Ma mar nem, de holnap osszevetem az X3-mat, az FX-6100 ket beallitasaval. Mondjuk nem lesz korrekt, mert Athlon 440, de a semminel jobb, hogy mennyit jelent az ujabb proci optimalizacioja, utasitaskeszlete es mennyit a modulos felepites.
Gondolom a A8-4555Mre gondolsz. GPU-ban igen jo, hazon belul nagy elorelepes. A gond az, hogy hazon kivuli CPU-bol inkabb egy i7-3667U-t szeretnek a gepemben latni. Egyelore nincs szuksegem GPU-ra, a regi GMA is megteszi RHEL ala.
https://frescho.hu
-

KAMELOT
titán
Igen a legtöbb szoftver még mindig 1-2 magot használ. Főleg a programokat kéne optimalizálni, hogy a procikban rejlő erő ki legyen használva. Ugye ez a része eléggé elmaradott. Hiába van brutál procid ha a program a régi dolgokat tudja cska használni.
E5200-al a winrar ugyan olyan gyorsan csomagol szét mint i5-3450-el.
Max játékokban érezhető, hogy az erős proci tudja hajtani a jó VGA-t. Meg tervező progiknál adobe corel autocad stb. ott érezhető a több magos proci ereje. Ugye ezeket a progikat 20-ből 1 ember használja többi meg net office mail game.V1200 - 18CORE - SUPRIMX
-
frescho
addikt
Amit magnak nevez az AMD, az valojaban nem erdemli meg a mag nevet.
Nem csak az ujtasitas keszlet fejlodott. Egy modul nem teljes erteku ket mag, legalabbis nem a klasszikus ertelemben. Leginkabb sziamiikerhez hasonloak, akiknek a szerveik nagy resze kozos, bar az agyuk nem. A 80%-os teljesitmeny ugrashoz mindjart megcsinalom a grafikont, de addig Oliverda cikkere hivatkoznek. O is 50%-ot tudott kimutatni X4-hez, de azt is csak a 8350-el az elozo generaciohoz kepest. Sajnos nalla nincs 1 core-modul eredmeny, pedig korrektebb lenne, mint az Athlon X3 elleni merkozes. Szoval a hivatkozott 80%-ot nem latom igazoltnak.
A Consumer piacra gyuras nem rossz strategia, csak kell melle a megfelelo szoftveres korites. Az is jon, csak lassan. Hasonloan az Apple sem a legcsucsabb hardverre, hanem a user experienc-re gyur, csak ott a sajat fejlesztesu OS megadja a pluszt.
En forditva kozelitenem meg, de teljesen egyetertek. Az AMD mas teruleten nyujt nagyot, mint az Intel. Amire hasznalod, ahhoz valassz processzort, APU-t, tabletet vagy SFF PC-t...
https://frescho.hu
-
frescho
addikt
Nem, az athlon 1 mag + HT. A bull pedig 1 modul, amiben ket nem teljes mag van osszenovesztve. Egy maghoz tartozik prefetch, dekodr, regizterek, FPU es minden mas. Ennek egy resze a bullnal kozos.
A bull sem tud szetvalni, mert a modulban levo masik mag terhelese csokkenti a masik magon futo program sebesseget a kozos reszek miatt. Az elmeleti skalazodas ertelmetlen, mert a gyakorlatban nem tudja felmutatni, max egy ket program eseteben.
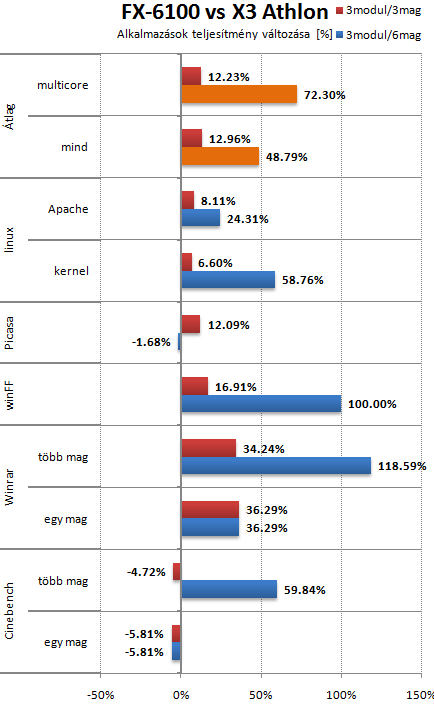
Athlon X3 440-hez hasonlit az alabbi grafikon, ami nem eppen acelos az X3-mak kozott. Egy korrekt X3 Phenommal 10-15%-al csokkentene az FX elonyet. A LinX es Vantage eredmenyeket kivettem, az applikaciok erdekesebbek. A multicore eredmenyeket nezve csak 72% az FX elonye, amibol 12-ot az uj cache, utasitaskeszlet stb. hozott. Ha ezt levonod, akkor mar csak 60% a modulos felepitesbol szarmazo elony, bar ez igy szammagia. Ertelmesebb nem csak a multithread atlagot nezni. Igy az elonye cca. 49%. Szoval nem latom az elmeleti 80% elonyt, csak a winFF (uj utasitaskeszletet ki tudja hasznalni, szinte megtaltosodik tole) es a WinZip hozza majdnem ezt.
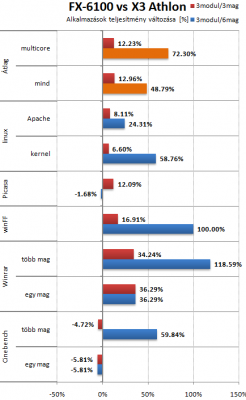
Meg lehet probalni merni. Ha ez vakteszteket jelent, akkor ugy. Audiofil cuccok jelentos reszenel sem merhetoek, csak hallhatoak a valtoztatasok. Nem rossz az irany, de akkor lesz igaz az, hogy megvan a sw korites, ha a programok jelentos resze kihasznalja majd a GPU-t peldaul megjelenitesre, filterekre, arcfelismeresre, hang/vido ki-be kodolasra. A win 8 hatalmas lepes ebben az iranyba.
https://frescho.hu
-
frescho
addikt
Ami itt igazan faj, az a prefetch es leginkabb a dekoder. A steam rollerben nem veletlenul fogjak duplazni. Az jo kerdes, hogy mit hivunk egy magnak, de anno a tobb integer feldolgozo beepitesenel sem kezdtek elnevezni a processorokat, hanem elneveztek szuperskalarnak. Az elvet az AMD kiterjesztette, ezert hajlok leginkabb arra, hogy inkabb modulokrol beszeljek, mint magokrol, tehat az FX-6 az 3 modulos. 1 modul egy "szuper-szuper skalar" cimet is kaphatna, vagy CMT modulnak is lehetne hivni. A CMT-vel bevezetett modulon beluli magok kozotti fugges miatt viszont nem hivnam magnak azt, amit az AMD magnak hiv.
Mar irtam, hogy nem a FlexFP a gond szerintem, hanem a dekoder reszleg, ami nem tudja megfelelo sebesseggel kihordani az ujabb tal rizst a konyhabol a ket gyerekenek, hogy a te hasonlatod vigyem tovabb.
"Ha az integer feladatokat nézed, akkor a Bulldozer modul kapott egy extra integer clustert, vagyis logikus, hogy két integer clusterrel jöhet 80% plusz." Erre reagaltam, hogy ez elmeleti 80%. A szamitasaiknak a fele erheto el a gyakorlatban atlagolva. Valamiert az az erzesem van folyamatosan, hogy az AMD a jovonek probal tervezni, de valamiert a jelenben nem tudja ugy eladni a termekeit, ahogy kellene.
https://frescho.hu
-

P.H.
senior tag
Ezt már többször olvastam tőled, hogy a "úgy tervezték a FlexFP-t, hogy szétváljon, ha nem AVX kódot kap.". Nem, nem így tervezték; nem, nem válik szét, sőt 'össze sem kapcsolódik', ha AVX kódot futtat.
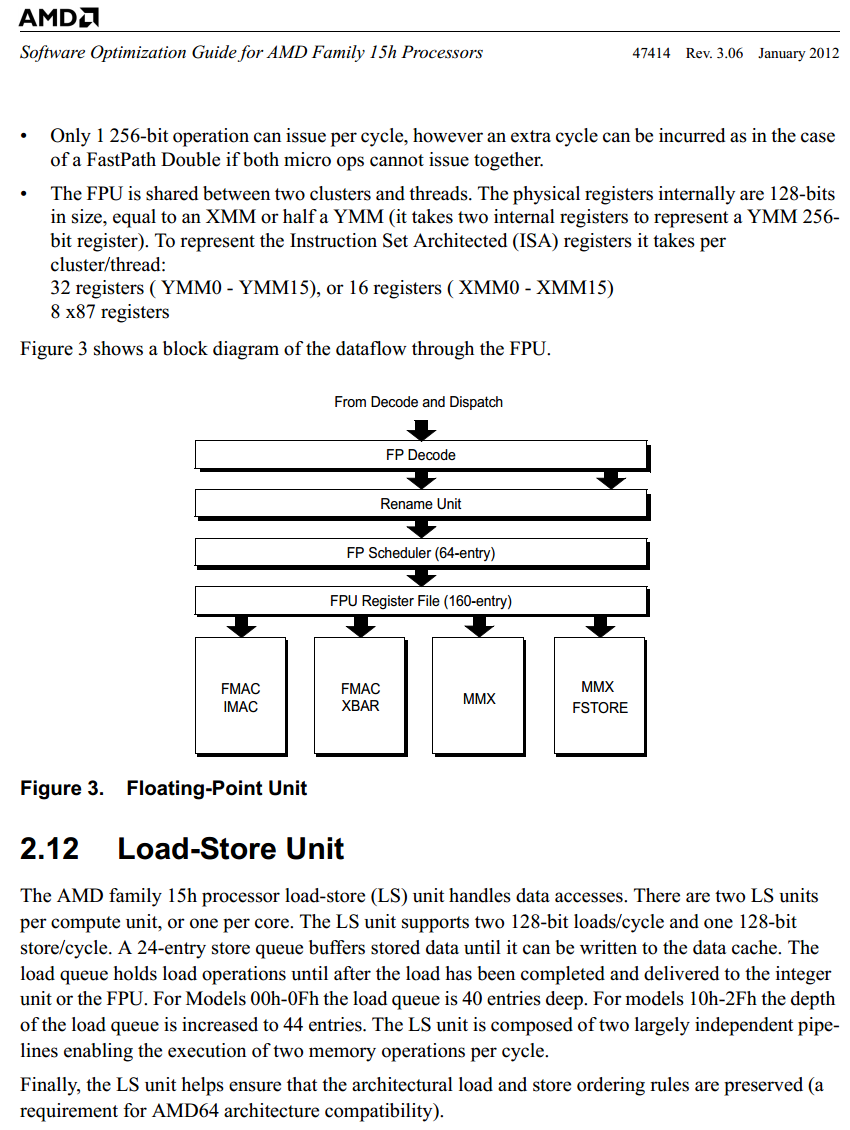
Ez a FlexFP sematikus rajza szerintük:

4 db 128 bites végrehajtó, közülük 2 dolgozik alapvetően egész számokon (MMX) és 2 lebegőpontos számokon (FMAC). Ezenkívül 3 bír speciális feladatkörrel, olyannal, amelyet semelyik másik nem tud ellátni, tehát szükségszerűen mindkét szálat ki kell szolgálják »egyszerre« (pl. csak az FSTORE tud memóriába írni, az XBAR adattípustól függetlenül vektorelemeket átrendezni, ...).
Továbbá egyrészt ott a "Only 1 256-bit operation can issue per cycle, however an extra cycle can be incurred as in the case of a FastPath Double if both micro ops cannot issue together." mondat, csakhogy szinte az összes AVX utasítás Fastpath Double, azaz 2 db - ebben az esetben 128 bites - micro op-ra fordul le.
Másrészt ha az egyik szál 128 bites (akár SSE-)műveletének szüksége van egy L2-ben (18-21 órajel), L3-ban vagy rendszermemóriában levő adatra, akkor a fél FlexFP ne működjön, hanem várja meg azt, vagy addig hajtsa végre teljes mellszélességgel a másik szál készen álló utasításait, amelyeknek nem kell várnia adatokra?A legegyszerűbb eset a leggyorsabb is egyben, ugyanaz az elv, mint a HT-nél, itt is órajelenként felváltva kapja meg az egységes FP-ütemező a 2 szál utasításait. Amely műveletek bemeneti értéke rendelkezésre áll, azokat végrehajtja (nem téve különbséget a thread-ek között); ha több ilyen van utasítás van, amely adott pillanatban készen áll a futtatásra, akkor a legrégebben bekerülteket indítja.
Átalában az AVX utasítások két 128 bites felének egyszerre érkezik meg a bemeneti adata (előző utasítástól vagy a memóriából, mivel magonként 2 AGU van a két 128 bites memóriaolvasásnak), de ha 2 AVX utasításnál (= 4 db 128 bites félnél) áll fenn ez egyszerre, mert mondjuk két különböző szálból valók (a 2 magban 4 AGU van), akkor egy-egy FMAC egymás után futtatja le az adott utasítás két felét, az egyenlőség elvét követve.
Ez minden ütemező működési elve, legyen szó akár egy egyszerű egyszálas OoO-ütemezőről is. Minden más elv csak lassítana rajta, vagy a statikus/dinamikus működési ("szétválik"/"összekapcsolódik") váltás feleslegesen növelné a tranzisztorigényt és eredménye se lenne; egyszerűen csak az FP-ütemező nem tesz különbséget a két szál között, csak egy adag 128 bites micro op-ot lát és kezeli őket.[ Szerkesztve ]
Arguing on the Internet is like running in the Special Olympics. Even if you win, you are still ... ˙˙˙ Real Eyes Realize Real Lies ˙˙˙
-
P.H.
senior tag
Nem csak érzed, valóban "flexibisebb" bizonyos tekintetben, de ez nagyrészt a szerkezetéből adódik: a GCN-végrehajtók int32/int64/float32/float64 adattípuson tudnak dolgozni (ebbe konvertálnak fel memóriaolvasáskor és ebből le íráskor, összekötve a vektoradatok átrendezésével; a byte- és 16 bites word-feldolgozás hiányzik ugyanúgy, mint az extended precision 80 bites FP; egy pixel nekik int32 típusú, az ezeken végzett műveletek egy része is csak int24) és a vektoradatokat már betöltéskor ill. kiíráskor is át tudják rendezni (ez nem gather-eset, az több memóriacímről olvas, ez pedig egyetlen folyamatos memóriaterületet, csak átrendezi a vektorelemeket). Ezért izmos memóriahozzáférési pipeline-okkal rendelkeznek, amikkel egy CPU nem. Azok más szempontból vannak kigyúrva: (a GCN in-order jellegével ellentétben) OoO végrehajtás mellett kezelik azokat ez eseteket, amikor ugyanarra a címre történik írás, mint ahonnan olvasás is (pl. store-to-load forwarding, memory disambiguation), ez GCN esetében nem bírna gyakorlati jelentőséggel.
Jobb lenne természetesen, ha nem lennének a végrehajtók specializálva, de ez mind-mind tranzisztorigényes feladat. Pont az AMD-nek van régi tapasztalata abban, hogy hogyan lehet olyan felépítést alkotni, amelyben minél több végrehajtó lát el azonos feladatkört (pl. az ütemezők 'rovására', egyszerűsítése érdekében, mint a K7/K8/K10 3 szinte azonos képességű ALU+AGU+ütemezője).
Példa: a Llano Store/Convert Unit-ja (a konvertálás is specializált az FMAC0-ra Bulldozer/Piledriver esetén), Store Align-je, vagy a Load/Store 1-2 Unit, majdnem akkora méretű, mint a az FPU műveletvégző egységei vagy a 64 KB-os L1D.
[ Szerkesztve ]
Arguing on the Internet is like running in the Special Olympics. Even if you win, you are still ... ˙˙˙ Real Eyes Realize Real Lies ˙˙˙


 )
)


Új hozzászólás Aktív témák

lo Közép teljesítményű FX 3 modullal, vagy akinek úgy tetszik 6 maggal. Mire elég?
