Tavaly már lefutott egy hullám a magyar informatikai sajtóban (a Techcrunch akkori ismertetője alapján) a pittsburghi Carnegie Mellon Egyetem kutatóinak projektjéről, amelynek a reCAPTCHA nevet adták.
E program két célt tűzött ki maga elé: egyrészt eszközt adjon a felhasználók számára, hogy kevesebb spamet kapjanak postafiókjukba, másrészt pedig (s ez a hangsúlyosabb) a hálózat és a felhasználók tömegei által segítsék a régi nyomtatványok, kéziratok digitalizálását. A magyar oldalakon is természetesen roppant különböző vélemények érkeztek ezzel kapcsolatban: megjelentek projektet lelkesen üdvözlők, a fanyalgók, a szakmai érvek alapján kétségeiket kifejezők, s a szakmainak látszó érvek alapján elutasítók is.
A reCAPTCHA csapata a napokban a Science oldalán számolt be arról, hogy programjuk igen sikeresnek bizonyult, és segítségével befejezték a The New York Times 1908-tól induló évfolyamainak teljes digitalizálását.
De mi is az a reCAPTCHA? Ez a sokak figyelmét felkeltő projekt még a magyar Spamwiki-ben is önálló szócikket kapott, s ha valaki lemaradt volna róla, annak összefoglalom a lényeget.

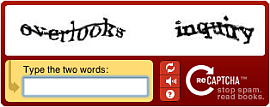
A CAPTCHA mindenki számára ismerős, még ha esetleg nem is ismeri ezt a rövidítést, hiszen szinte minden letöltőoldalon találkozunk vele: CAPTCHA-t töltünk ki, amikor arra kér bennünket a weboldal, hogy gépeljünk be egy karaktersorozatot (esetleg oldjunk meg egy szöveges feladatot), s csak helyes válasz után enged be. Ez az a biztonsági funkció, ami arra szolgál, hogy bizonyos szolgáltatások igénybevételénél a felhasználóról kiderítsék, hogy ember-e, vagy pedig egy szoftver, egy robot (maga a rövidítés is erre utal: Completely Automated Public Turing test to tell Computers and Humans Apart – teljesen automatikus, publikus Turing-teszt az emberek és a számítógépek megkülönböztetésére). A robotok ugyanis nem képesek felismerni a torzított karaktereket, így el lehet kerülni a tömeges behatolásokat, az automatikus spamterjesztést és így tovább.
A Carnegie Mellon kutatói úgy gondolták: amellett, hogy egy ilyen szolgáltatást elérhetővé tesznek, még egyéb feladatra is ki lehetne használni ezt a procedúrát. Arra a következtetésre jutottak, hogy ha naponta rengeteg ember kényszerül ezeknek a karaktereknek a begépelésére, akkor talán rájuk lehet tenni még egy apró plusz terhet: ne csak egy karaktersorozatot gépeljenek be, hanem kettőt, melyből az egyik egy szkennelt szöveg szoftveresen nem értelmezhető része.
Hogy ez mit jelent? A számítógépes világ előtt rögzített információk (bármilyen furcsán is hangozhat, volt ilyen…) átmentése, a nagy nyilvánosság számára elérhetővé tétele kulcsfontosságú kultúráink szempontjából. Ez a folyamat roppantul leegyszerűsítve általában úgy zajlik, hogy a papíron stb. rögzített szövegeket jobb-rosszabb szkennerekkel beolvassák, majd ezekre a képekre ráeresztenek valamilyen karakterfelismerő programot, hogy sokkal kisebb méretű, illetve kereshető, szöveges adatállományokat hozzanak létre.

A ma leggyakrabban használt optikai karakterfelismerő programok (Optical Character Recognition – OCR) egyre jobbak, ám nem képesek oly módon azonosítani a karaktereket, mint az emberek, ezért még a legkiválóbbak is sokat hibáznak, illetve nem tudnak megbirkózni a szokatlan karakterekkel, a behajtott lapokon található szöveggel, a piszkos papírral, hogy a kéziratokról már ne is beszéljünk.
A reCAPTCHA program kitalálói ezért úgy gondolták, hogy a szokásos egyszavas CAPTCHA mellé betesznek egy másik szót is, egy olyat, mellyel a digitalizálási munka során a karakterfelismerő program nem tudott megbirkózni. Ha a reCAPTCHA-t alkalmazó weboldalra érkezik egy felhasználó, akkor a szokásos boxban két szót lát: egy olyat, amelyet már megerősítetten biztos olvasattal láttak el, és egy olyat, amelynek még nem adták meg az elfogadott olvasatát. Ha a felhasználó sikeresen azonosítja a már ismert szót (ez a belépője az adott oldalra egyébként), akkor a szoftver feltételezi, hogy a másikat is helyesen olvasta el, s ezt az olvasatot elhelyezi egy adatbázisban. Így a felkínált bizonytalan olvasatú szavak helyes értelmezését statisztikai alapon határozzák meg. Az még nem világos a mai napig sem, hogy az e problémára teljesen érzéketlen felhasználókat hogyan teszik képessé a belépésre, ám a gyakorló példákat megszemlélve nagyon valószínűnek látszik az a feltételezés, hogy a belépésre jogosító szóképek valójában minimálisan eltorzított karakterek, nem pedig valódi, kérdéses olvasatú képek, tehát semmi olyan problémával nem kerül szembe a felhasználó, melyet nem tudna megoldani.
A projekt működtetői ezen kívül számtalan eszközt biztosítanak az érdeklődőknek: nyilvános API, egyszerűen generálható kódok a saját weblapba történő beillesztéshez, e-mail címek védelme (ez azt jelenti, hogy ha valaki a saját weboldalán jelenít meg e-mail címeket, akkor lehetősége van arra, hogy a látogató csak egy reCAPTCHA kitöltése után kapja meg a teljes címet) stb.
A szellemes kezdeményezés, úgy tűnik, széles körű támogatottságra talált (valószínűleg nem a grátiszban kínált biztonsági szolgáltatás miatt, hanem inkább amiatt a végtelenül tiszteletre méltó lelkesedés miatt, mely a Wikipediát is élteti), mivel a Science-ben közzétett jelentés szerint a rendszer jelenleg napi 4 millió választ regisztrál 40 ezer weboldalról, ami az egyik szervező szerint 1500 ember 24 órás munkájának felel meg: mint ha ennyi a munkás percenként 60 szót próbálna „megfejteni”. Az elmúlt egy év során körülbelül 440 millió szót azonosítottak, s ez hallatlan nagy segítség volt a The New York Times kereshető digitalizált változatának előállításához.







