Új hozzászólás Aktív témák
-
#51
 Balala2007
tag
Petykemano
#26
Balala2007
tag
Petykemano
#26
Balala2007
tag
válasz
 Petykemano
#26
üzenetére
Petykemano
#26
üzenetére
vmikor lesz elvileg AVX512 is
Az AVX512 implementálására az AMD-nek eddig se szandeka, se ereje nem volt, aki ilyesmit akart, azt a GPU fele terelte.AVX512 úgy jön, hogy 4x128-os feldolgozó, vagy 4x256
AVX512-nek a horizontalis muveletek gazdagsaga miatt csak nativan van ertelme. Probald meg pl. a VPERMI2W-t hatekonyan implementalni enelkul…A Zen->Zen2 valtas leginkabb a K8->K10-re emlekeztet. Ugyan tobb, de nem nagyon mas.
AIDA64.com
-
#52
 Petykemano
veterán
joysefke
#48
Petykemano
veterán
joysefke
#48
Petykemano
veterán
Még a bulldozer idejében voltak viták arról, hogy az SMT vagy a CMT megközelítés hatékonyabb-e. Jellemzően mindkettő 2 szál kezelésére alkalmas felépítésű. A CMT ugye arról szól, hogy a 2 szálat feldolgozó rész viszonylag kevés erőforráson osztozik, eléggé szét van választva. Cserébe a szálakat feldolgozó részek/oldalak háborítatlanul tudnak működni, nem versengnek egymással, és egyszerű felépítésűek, ezért tud pörgös és energiahatékony (khm-khm) lenni.
Az SMT abból indul ki, hogy egy széles (sok feldolgozót tartalmazó) magra indít két szálat. Itt a megosztott erőforrás vastag, a szálak versengnek egymással a processzor erőforrásainak használatáért.
(Elég részletes leírás itt)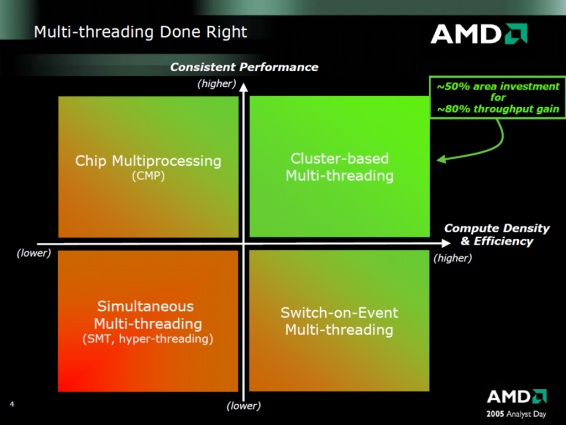
Az érvelés mindig valami olyasmi volt, hogy az SMT többlet-szilikon igénye 5% lehet, a yield pedig 20-30%
(Azoknál a programoknál, amelyeknél nem számít az egyszáles teljesítmény, mert valójában 1db 100%-os (potenciál) szál helyett a 2db az erőforrásokért versengő 60-65%-os (a ST potenciálhoz képest) szál fut)A CMT pedig mintegy 50% helyigény mellett 80%-os teljesítménytöbbletet adott 1 szál helyett 2 futtatásával.
Most itt nekünk az persze a CMT és az SMT kérdése már rég nem érdekes, csak az, hogy az SMT implementálása 5%-os többlettel jár.
Ez azt jelenti, hogy a szálkezeléshez dedikált részegységek csupán mintegy 5%-át tehetik ki lapkának, illetve SMT implementálása esetén ~10%. Tehát az SMT4-hez további 10% lehet szükséges.
Az SMT letiltását (ami ugyebár a szilikon 5%-ának elpazarlását jelenti) eddig is megtették Az AMD oldalán most ugyan nem gyakori, de az intel mostanában előszeretettel él vele. Az AMD nem sajnálta a szilikont a zeppelinből sem, amikor olyan részeket pakolt bele, amelyeket csak a szervereknél, illetve theadrippereknél használtak, AM4 tokozásnál nem.
Szóval én ezt a 10% többletet nem látom olyan nagy veszteségnek, ami miatt külön kéne választani a szerver és konzumer piacra tervezett lapkákat. Még csak letiltani sem feltétlenül kell, annyit kellene csupán csinálni, hogy AM4 alaplapok esetén a default az SMT2, de bátrak adott esetben átállíthatják 3-ra, vagy 4-re.Ha valahogy ügyesen csinálják, akkor esetleg még azt is megoldják az alábbi képen zölddel jelölt statikusan partícionált erőforrásokat a BIOS beállítás alapján partícionálják, vagyis 4 helyett 3 vagy 2 vagy 1 szált engedélyezése esetén a a 3, 2, vagy 1 szálnak azokból is több/nagyobb áll rendelkezésre. Így dekstop (SMT2) még Single Thread szempontjából még kevesebb az elvesztegetett erőforrás a "letiltás" miatt

Ami miatt ez az egész SMT4 számomra sokkal nagyobb kérdés, az az, hogy szerintem a Zen jelenlegi feldolgozóira nézve egy harmadik és egy negyedik szál már nagyon kicsi yieldet hozna.
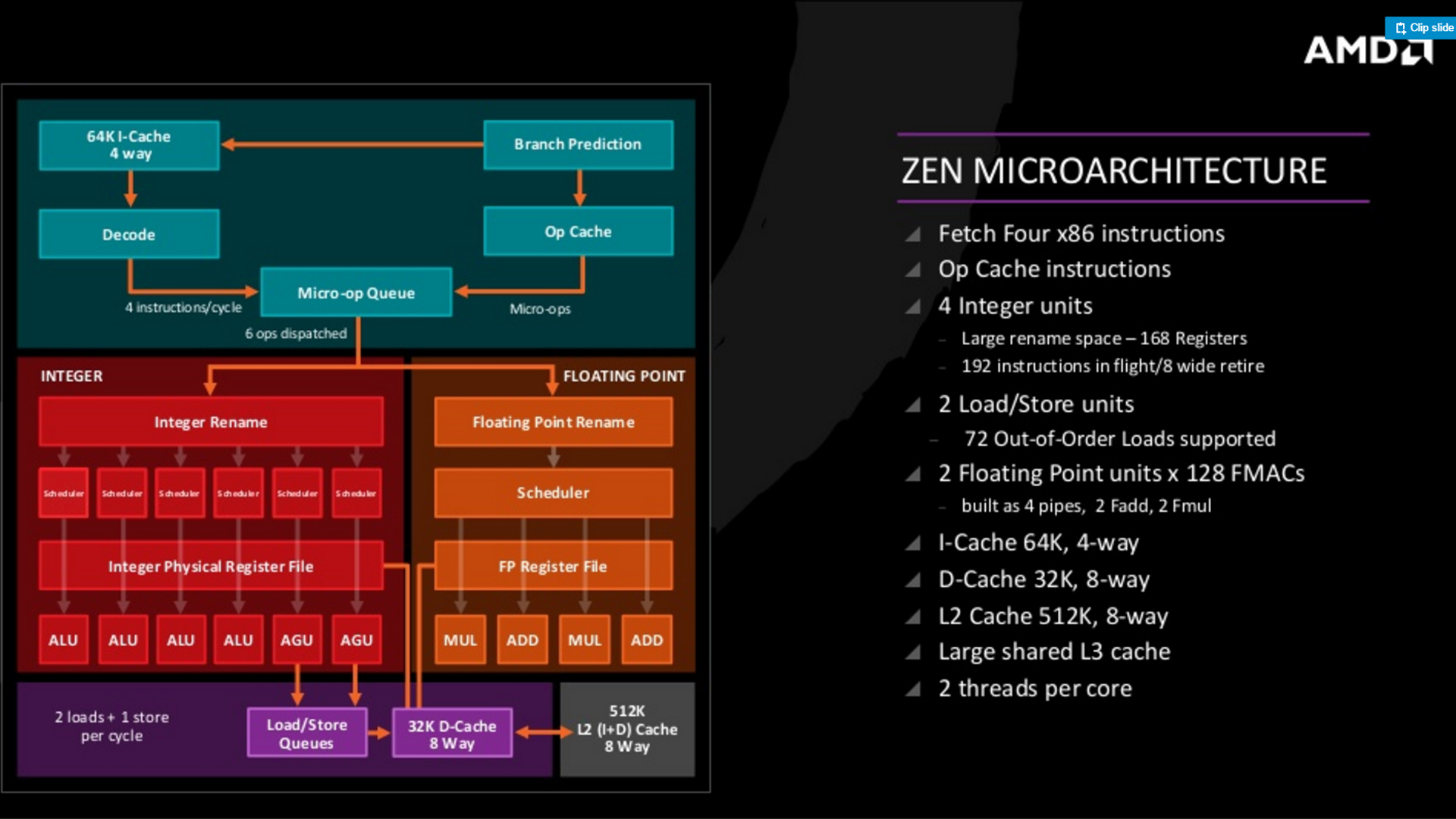
Itt van az integer pipeline-ban 4 ALU és 2 AGU, és van FPU: 2x128bites FMAC 4 pipe: 2 add és 2 MUL
Van egy ilyen is: "Dispatch is capable of sending up to 6 µOP to Integer EX and an additional 4 µOP to the Floating Point (FP) EX. Zen can dispatch to both at the same time (i.e. for a maximum of 10 µOP per cycle)." (src)És a zen esetén így hoz az SMT 40-50% többletet. Ami azt jelenti, hogy természetesen a zen backendje erősebb, szélesebb, mint a frontend - a frontend 1 szálon nem tudja maximálisan kihasználni a backend kapacitásait.
Ezen - a frontenden - a zen2 nyilvánvalóan javít:
Ha majd méri valaki a zen2 SMT hatékonyságát, akkor derülhet ki, hogy a zenben az SMT 50%-os yieldje mennyire pörgette ki a backendet a limitig.
Ha a zen2 a frontend javításával továbbra is 50% körüli SMT yieldet ér el, akkor a backendben még van lóerő.
Igazából ha SMT4-gyel mondjuk még 25% throughputot el lehet érni, az már lehet, hogy megéri (+25% throughput +10% szilikon árán)
az IBM power8 esetén a yield SMT2-ről SMT4-re 50% volt, így a 4 szálas throughput majdnem két és félszerese volt az 1 szálasnak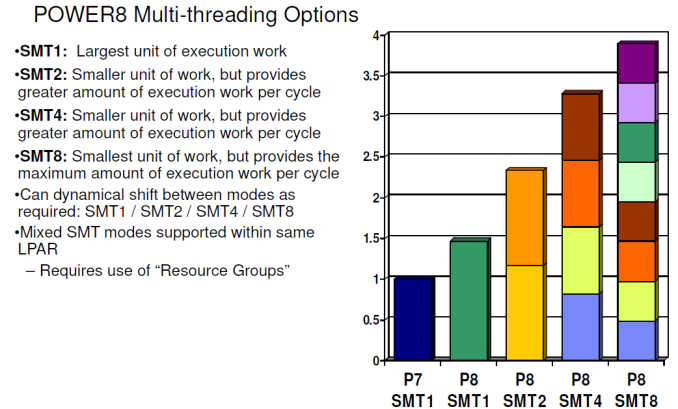
Persze az igazsághoz hozzátartozik, hogy a power szerver architektúra, ott kvázi megengedhető, hogy az egyszálas teljesítményt kicsit lazábban kezeljék és az IBM processzoraiban ez így is történik, ahogy azt az egyik kolléga linkelte is a cikkben, hogy az SMT4 humbug.
Tehát én jelenleg inkább meglepődnék, ha a zen jelenlegi backendjére ráengednék az SMT4-et. Ehelyett arra számítok - abban bízok -, hogy szélesítik az architektúrát. Egyrészt 4 ALU helyett mondjuk 5, vagy 2 AGU helyett 3, vagy 4 ALU, 4 AGLU (lásd piledriver) és az FPU oldaláról pedig azt várnám, hogy a 256bit, majd az 512 bit vektorutasítások végrehajtására úgy készítsék föl, hogy azokban 2, illetve 4 128bites utasítást - akár ha azok különböző szálakból jönnek is - végre lehessen hajtani egy ciklus alatt.
Így a backend megint fölénybe kerülne, de desktop vonalon ha az SMT4-nek, nem feltétlenül, de SMT3-nak is lehetne értelme, amíg a frontend felzárkózik.
Találgatunk, aztán majd úgyis kiderül..
-
#53
Petykemano
veterán
Balala2007
#50
Petykemano
veterán
válasz
 Balala2007
#50
üzenetére
Balala2007
#50
üzenetére
Én ugyan ennyire nem értek hozzá, de hasonló backend kapacitás-korlátokra gondoltam én is, ami számomra kérdésessé teszi a harmadik, negyedik szál yieldjét.
Ezt az 1load+1store képességet egyébként nem lehet javítani? Amikor a zen1 kiadásra került, a zen2 lényegében készen volt, már akkor nekifoghatott az A team a zen3-nak, ez két év. Ha tényleg az SMT4 a cél, és akkor ezen a tényezőn 2 év alatt csak tudnak valamit faragni, nem?
Talán ha a piledriverből átemelnék az aglukat, és 4 alu + 2 agu helyett 2 alu + 4aglu lenne benne, a load/store kéoesség is bővülne. De mondom, ehhez nem értek.
Az AVX512-vel kapcsolatban persze az a szóbeszéd, hogy ha már vektor, arra ott vannak a CU-k, és hogy offloadolni kellene. De amíg ehhez szoftveres támogatás kell, addig veszett fejsze nyele. Ezt egyébként chiphelles pletyka hintette el.
Mit gondolsz az infinity.fabricon keresztül meg lehet oldani, hogy avx512 utasítást valójában ne az fpu, hanem egy igp.hajtson végre?Találgatunk, aztán majd úgyis kiderül..
-

arn
félisten
Ezzel a megkozelitessel egy problema van, hogy nem veszi figyelembe a programok skalazodasat, es azt feltetelezi, hogy minden jol skalazhato. A kov evekben pedig az egyik legnagyobb problema epp az lesz, hogyan tudjak hwes modon megoldani az aktualis pillanatban a teljesitmeny maximalizalasat - tehat ha vmi keves szalat igenyel, de magas orajelet, vagy sok szalat - mindegyiket biztositani kell, amugy szinte minden feladatra lesz optimalis processzorkonfiguracio, de egyik sem lesz “leggyorsabb” minden szempontbol. Az lesz a befuto, aki ezt a feladatot a legjobban oldja meg.
[ Szerkesztve ]
facebook.com/mylittleretrocomputerworld | youtube.com/mylittleretrocomputerworld | instagram.com/mylittleretrocomputerworld
-

Lacc
aktív tag
Na, akkor megdobják az AVX támogatást is (Nem hinném, hogy anélkül lehetne bármit is kezdeni az Intel fölénnyel a HPC piacon)? Ez a jelenleg elérhető AVX256 a Zen+-hoz egy katasztrófa (ez a 2x128bit-es felállás...) én csak 3 HPC-s alkalmazást használok, de egyiksem ismerte fel a Zen+-ban lévő AVX támogatást. Enélkül, meg sokkal lassabban muzsikál az AMD.
-
Az avx fel nem ismerése nem az amd-n múlik sajnos...
Az alkalmazás fejlesztőinek kéne újabb fordítót használni, vagy/és programban engedélyezni az adott cpu esetén is az avxet.
AVX2 utasítások ugyan lassabban (mivel fele olyan széles, így 2 részben), de letudnak futni AMD-ken is... de mi értelme is lett volna erősebbet berakni ha ezt se veszik figyelembe 2 év után se.. hacsak nem azért nem veszi figyelembe a szoftver készítője mert "lassú" ... de inkább az architektúra részesedése lehet az ok, és a gyártók "intelt supportálunk, használjon azt" felfogása...The human head cannot turn 360 degrees... || Ryzen 7 5700X; RX580 8G; 64GB; 2TB + 240GB + 2TB || Samsung Galaxy Z Flip 5
-

devast
addikt
Ez totál offtopik itt, de amíg az amd-nek nincs értékelhető piaci részesedése az adott szektorban, addig nem fogják az adott szektor szoftverkészítői hobbiból támogatni az ő hardverüket. Ilyen esetben igenis az amd-nek kell menni, és kilincselni a sw készítőknél, és adott esetben akár fizetni is ezért.
-
Lacc
aktív tag
Kettőn áll a vásár, nem egy Github-os issue van, ahol leírják, pont azért nem támogatják, mert a HPC piacon nagyon kishányadot birtokol az AMD, illetve a performance amit nyújt nem indokolja azt, hogy átváltsanak az Inteltől.
Megértem a szoftverfejlesztőket, mert 5%-os piaci részedesért - ez csak bedobott szám, volt ahol 8%-ot olvastam, volt ahol 1.7%-ot ugyanarra az évre statisztikában - nem igazán erőtlettik meg magukat, főleg ha open-source, az az alig van pénz mögötte, akkor minek foglalkozom ezzel a szabadidejében.AVX nálam lefut, ha Floating számítás van, ha meg Integer számítást akkor jaj veszékel, de valahol láttam - Reddit-en postot azthiszem - hogy az Intel Integer számításban kiüti az AMD-t, Floating-ban meg fordítva megy a KO kiosztása. a HPC meg olyan terület, ahol egy-egy szimuláció, számítás több órán keresztül zajlik.
Drukkolok az AMD Rome-nak, ha bejönne, akkor több AMD CPU-t vásárolna a Microsoft (Azure-hoz) és az Amazon (AWS)-hez, ez azért egész sokat számít.
Ryzen TR 29xx sorozat nagyon jól sikerült, a TR 19xx az nem, a Szerver applikációkban (Apache, JS) a második generációs TR-nél láttam eredményeket, hogy képes volt lenyomni a konkurenciát, az első generációnál nekem kiábrándító volt az eredmény. -
#61
 joysefke
veterán
Petykemano
#52
joysefke
veterán
Petykemano
#52
válasz
Petykemano
#52
üzenetére
Köszi az infót!
-
#62
 Cathulhu
addikt
Petykemano
#52
Cathulhu
addikt
Petykemano
#52
Cathulhu
addikt
válasz
Petykemano
#52
üzenetére
Nem lehet, hogy azért kell az SMT4 mert éhezni fognak a magok? Jön ugye a közös memória elérés és a nagyobb cache, így szerintem könnyebb lesz olyan szálat találni, ami tud dolgozni, amíg a többi I/O-ra vár. Nyilván szerver környezetben lesz ennek haszna, desktopon max az oprendszert gyorsítja, a GTAt nem.
Mások: HPC szegmensben nem az MKL a baj? Ahol van rá mód, ott OpenBLAS-t és Lapackot célszerű használni. MKL Intel procin marha gyors, de nem intelen sajnos néha még az SSEt se választja ki.
Az AMDnek az OpenBLASt kellene nagyon fejlesztenie, és meggyőzni a cégeket a supportról. A Matlab is csak mostanában állt át MKLra, szóval nem lenne lehetetlenség. De amíg ezek nem történnek meg, addig nem sok keresni valója van sajnos az AMDnek arra.Ashy Slashy, hatchet and saw, Takes your head and skins you raw, Ashy Slashy, heaven and hell, Cuts out your tongue so you can't yell
-
#63
 JColee
őstag
Petykemano
#52
JColee
őstag
Petykemano
#52
JColee
őstag
válasz
Petykemano
#52
üzenetére
Ne szilikonozzunk pls

Magyarul a szilícium, a szilikon egészen más.
Nem kötekedni akarok, jókat írsz, de ez szúrja a szememet.
-
#65
 awexco
őstag
Petykemano
#52
awexco
őstag
Petykemano
#52
awexco
őstag
válasz
Petykemano
#52
üzenetére
Elvileg a zen 2 ben lesznek ilyen irányú bővítések ami az smt4 hez is kelleni fognak nem ?
I5-6600K + rx5700xt + LG 24GM77
-
#66
Petykemano
veterán
awexco
#65
Petykemano
veterán
Én úgy tudom, a frontendet csiszolják (ST IPC) és a vektoros feldolgozást bővítik 128bitról 256-ra (annak minden velejárójával együtt - és ez persze nem jelenti azt, hogy eddig ne tudott volna 256bitet, de most már kétszer annyit tud egy órajelciklus alatt.)
Ezek nem tudom mennyiben járulnak hozzá az SMT4 implementálásához, implementálhatóságához.
[ Szerkesztve ]
Találgatunk, aztán majd úgyis kiderül..


























Új hozzászólás Aktív témák

ph Itt sincs a második generációs EPYC, de már harmadik generációs fejlesztés előkészítése zajlik.
- Másik bíróhoz került az Apple és az USA nagy pere
- Samsung Galaxy S24 Ultra - ha működik, ne változtass!
- Gyúrósok ide!
- Hálózati / IP kamera
- iPhone topik
- Futás, futópályák
- Politika
- Samsung Galaxy S21 és S21+ - húszra akartak lapot húzni
- gban: Ingyen kellene, de tegnapra
- Építő/felújító topik
- További aktív témák...
