Új hozzászólás Aktív témák
-

#00137984
törölt tag
GPGPU alkalmazásokhoz eddig is volt OpenCL 2.0 AMD APP, amit viszont OpenCL 1.2-nek azonositott és használt az a néhány program.
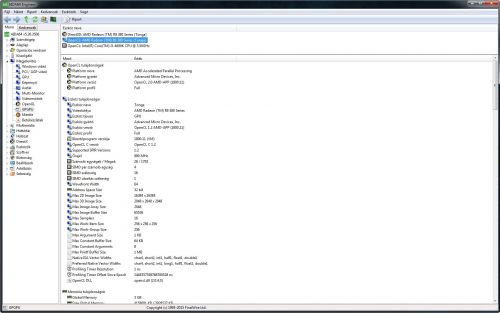 Majd nálam jobban hozzáértők megmondják, miért nem elég egy féle közösen elfogadott OpenCL és AMD videókártya mellé egyáltalán szükség van-e másikat feltenni a gépre.
Majd nálam jobban hozzáértők megmondják, miért nem elég egy féle közösen elfogadott OpenCL és AMD videókártya mellé egyáltalán szükség van-e másikat feltenni a gépre.[ Szerkesztve ]
-

Fiery
veterán
Az OpenCL platform (ami az APP hataskore) 2.0 verziot tamogat, de az eszkoz (R9 380 ebben az esetben) csupan OpenCL 1.2-t. Amit az AIDA64 mutat, az teljesen normalis, nem latok hibat. Ha a gepben nem Intel CPU lenne, hanem Kaveri/Godavari/Carrizo APU, akkor annak az iGPU eszkozere mar OpenCL 2.0-t mutatna az AIDA64 (is).
[ Szerkesztve ]
-

DRB
senior tag
Jaja, a 380X-re meg 2.0-t írnak a Sapphire oldalán, a két kártyán ugyan az a Tonga GPU van(mostani nevén Antigua), igaz a 380-ban néhány shader le van tiltva, de nézhetjük a 290X vs. 390X-et is, az egyikre 1.2, a másikra 2.0-t írnak, pedig itt még annyi eltérés sincs mint 380X/380-nál.
(#5) Fiery: Vajon a 290Xre miért mutat 1.2.őt az aida64?
[ Szerkesztve ]
-
Fiery
veterán
Az OpenCL 2.0 lenyege, ertelme, letjogosultsaga szinte teljesen kimerul az SVM-ben. Akarhogy is csurjuk-csavarjuk a dolgot, egy dGPU ertelmes keretek kozott nem fog SVM-et tamogatni, tehat nem lehet OpenCL 2.0 kapcsan sem beszelni semmilyen dGPU-rol. Ha pedig innen nezzuk a dolgot, akkor teljesen mindegy, melyik gyarto ill. melyik weboldal mit allit egy adott dGPU-rol. Egyebkent ennyi erovel a Mantle-be is bele lehetne kotni

[ Szerkesztve ]
-

con_di_B
tag
Device-side kernel launch? Annak elvi szinten pont, hogy dGPU-n van tobb ertelme, ha tenylegesen gyorsabb mint a host-side kernel launch.
Az SVM-hez meg a kotelezoen tamogatott szint az lenyegeben nem szigorubb, mint amit eddig is lehetett tudni egy normalis map/unmap implementacioval cimforditas mellett, nem?
[ Szerkesztve ]
-
con_di_B
tag
Peldaul igy: CL_MEM_USE_PERSISTENT_MEM_AMD.
Sosem hasznaltam, de ha jol ertettem, ezt tudja azt, hogy a buffer mindig ugyanoda pinnelodik.
Ha jol ertem, ha ezt tudod, plusz meg annyit megcsinalsz, hogy a kernel launch automatikusan szinkron esemeny legyen, akkor gyakorlatilag kesz van a coarse grained SVM implementaciod. Nem teljesited betu szerint, hogy ugyanazt a virtualis pointert hasznalja a ket eszkoz, de osszesen egyszer tortenik cimforditas, a host oldalon nyugodtan rogzitheted a mutatoidat, ervenyesek fognak maradni, az meg, hogy a GPU valojaban mivel cimez az inkabb filozofiai problema. Ezen kivul az is problema, hogy rohadt sok pinned memory-t fogsz lefoglalni host oldalon, es jo esellyel ki is fogysz belole, dehat nem is azt mondtam, h ez egy jo megoldas, csak azt, hogy meg lehet csinalni.
De javitsd ki ha tevedek, mert az uj 2.0-s feature-oket sajnos meg nem volt alkalmam kiprobalni a gyakorlatban, szoval lehet olyan scenario, amit ez nem fed le.
A Fine grained SVM az nyilvan tok eselytelen, de az amugy is csak egy APU/SoC szeru allaton lehet erdekes, ennek megfeleloen, az eleve opcionalis feature.
[ Szerkesztve ]
-
Fiery
veterán
Nem azt mondtam, hogy OpenCL 2.0 = SVM, hanem hogy az az egesznek az apropoja, az indokolta a major verzio ugrast kapasbol. Vannak mas ujdonsagok is, amiket tamogathat egy dGPU is. Es nyilvan az SVM bizonyos funkcioit tamogatni lehet dGPU-val is, mint ahogy az nVIDIA oldalan, a CUDA-ban is van megosztott memoria, de a legtobb esetben ez inkabb csak potcselekves, mint valoban hasznos feature. Ha ezzel egy adott dGPU meg tud felelni az OpenCL 2.0-nak (amihez valoban nem kell SVM, rosszul emlekeztem, lasd lentebb), az tok jo, de en me'g nem lattam olyan AMD dGPU-t, ami SVM-et tamogatna, ill. ami a device kapcsan OpenCL 2.0 verziot riportolna magarol. Es egyik sem tamogatja a cl_amd_svm egyedi OpenCL kiterjesztest sem. Nyilvan meg lehetne oldani, takolassal meg trukkozessel egy dGPU kapcsan is az SVM tamogatast, de ez SZVSZ inkabb egy felesleges marketing huzas lenne, mint valoban hasznos feature. Kulonosen mivel ha valakinek pont az SVM-re van igenye, akkor remek SVM-képes APU-t vasarolhat mar most is (pl. Carrizo).
Szerk.: Sz'al utananeztem, es elvileg ezek a kiterjesztesek szuksegesek az OpenCL 2.0-hoz:
cl_khr_3d_image_writes
cl_khr_byte_addressable_store
cl_khr_depth_images
cl_khr_global_int32_base_atomics
cl_khr_global_int32_extended_atomics
cl_khr_image2d_from_buffer
cl_khr_local_int32_base_atomics
cl_khr_local_int32_extended_atomicsEzek kozul a cl_khr_depth_images-et nem tamogatja az R9 380 (Antigua), a tobbit tamogatja.
-
DRB
senior tag
Úgy nézem a 290X(ergo a 390X) is ezeket támogatja, kivéve a cl_khr_depth_images-t. Gondolom driver kérdése az egész, bár esküt most így erre nem tennék.
 Mondjuk azt azért hozzátenném, hogy mindez az aida szerint, de hát az aida szerint a hardveres dx támogatás is csak 11.1, egy másik fülön meg már 11.2, valóságban meg tudjuk, hogy 12. Ne értsd félre, mindezektől függetlenül az aida egy remek kis progi, talán a műfajában a legjobb, de azért nem tökéletes, persze ilyen nincs is
Mondjuk azt azért hozzátenném, hogy mindez az aida szerint, de hát az aida szerint a hardveres dx támogatás is csak 11.1, egy másik fülön meg már 11.2, valóságban meg tudjuk, hogy 12. Ne értsd félre, mindezektől függetlenül az aida egy remek kis progi, talán a műfajában a legjobb, de azért nem tökéletes, persze ilyen nincs is ”Kulonosen mivel ha valakinek pont az SVM-re van igenye, akkor remek SVM-képes APU-t vasarolhat mar most is (pl. Carrizo).„
Ez lehet, de Carizzo igpu-ja köszönőviszonyban sincs, teljesítményben értem, mondjuk egy 390X-hez.Hadd kérdezzem már meg, te szándékosan írsz ékezet nélkül? Rohadt idegesítő.
![;]](//cdn.rios.hu/dl/s/v1.gif)
[ Szerkesztve ]
-
Fiery
veterán
Kerlek, ne keverd a DirectX-et az OpenCL-lel. Az egyik egy nagy rakas sz*r, legalabbis diagnosztikai szempontbol, a masik (OpenCL) meg egy joval konnyebben behatarolhato es sokkal megbizhatobban hasznalhato API. Amit az AIDA64 az OpenCL-rol mond, azt nyugodtan veheted keszpenznek -- de ha gondolod, tudod ellenorizni mas szoftverrel az infok pontossagat. Mar ha talalsz erre megfelelo szoftvert
"Ez lehet, de Carizzo igpu-ja köszönőviszonyban sincs, teljesítményben értem, mondjuk egy 390X-hez."
Kiveve, ha olyan feladatot kell GPU-val gyorsitani, amit az SVM segitsegevel gyorsabban vagy egyszerubben tudsz megoldani. Vannak olyan feladatok, amiknel oriasi kihivas a nem-SVM alapu GPGPU implementacio, pl. lancolt listak vagy bonyolult strukturak miatt. Az adatok ide-oda masolasa a device memory es a host memory kozott sem mindig trivialis, nem beszelve a nagy overheadrol. Meg van tehat a maga letjogosultsaga a relative lassu, de SVM-képes GPU-knak is; es persze hamarosan talan eljon az a nap is, amikor a "best of both worlds" APU-t is megkapjuk.
"Hadd kérdezzem már meg, te szándékosan írsz ékezet nélkül? Rohadt idegesítő."
En csak angol kiosztasu billentyuzetet hasznalok, mivel programozokent ezzel sokkal konnyebben tudok dolgozni. A napom nagy reszeben angolul beszelek ill. irok-olvasok, emiatt szoba sem johet a magyar billentyuzet. Es igen, tudom, hogy at lehet kapcsolni magyar kiosztasra, es tudom, hogy mekkora rohadek magyar vagyok, hogy nem hasznalok ekezetet, de igazsag szerint egyszerubb lenne nekem angolul irogatni a magyar forumokba is, tehat vedd ugy, hogy mar azzal, hogy ekezet nelkul irok magyarul is megeroltetem magam a nyajas olvasokozonsegre valo tekintettel

 Ha valakit ez idegesit, azzal nem tudok mit kezdeni, engem is sok minden idegesit, megsem teszem szova minden egyes embernel, hogy kiben mi idegel Pedig vannak koztuk prominens forumozok is
Ha valakit ez idegesit, azzal nem tudok mit kezdeni, engem is sok minden idegesit, megsem teszem szova minden egyes embernel, hogy kiben mi idegel Pedig vannak koztuk prominens forumozok is 
Peace
[ Szerkesztve ]
-
DRB
senior tag
Ha jól értem, akkor a DirectX-et nem jól detektálja valamiért az AIDA? Az OpenCL-re akad másik szoftver, az is 1.2-t ír egyébként.
Amúgy azért kérdeztem a 290X/390X-et, mert azt hittem támogatja az OpenCL 2.0-át(SVM-et, meg úgy egyébként az ezzel kapcsolatos dolgokat), úgy rémlik az AMD zagyvált erről valamit, de ezek szerint nem jól rémlik, vagy valamelyik FirePro-ra írták és ezzel keverem. De igazából mindegy, csak kíváncsi voltam, hogy az AIDA64 hibázik, vagy tényleg az AMD beszél ződségeket.Erről az iGPU sebességről meg felesleges szerintem vitázni, ha valamelyik emlegetett dGPU támogatná az SVM-et, akkor lenyelné keresztbe a Carizzo gpu-ját, még úgy is, hogy hozzászámoljuk a PCIe késleltetését. De amióta a prociban van a vezérlő, és nem az alaplapi chipsetben, azóta sokat csökkent késleltetés. Bár tény, hogy még így is sokkal lassabban éri(vagy érné) el a dGPU a rammot, mint egy mostani APU(iGPU + CPU).
Az ékezetekről sejtettem, hogy ezt fogod írni, mégis akad néha itt-ott egy „é”, talán „á” is, szóval valami nem stimmel.

 Van egy programozó haverom, még a suliból marad rajtam, na ő is mindig azt mondja amit te(gondolom ez valami Hi tech csajozós duma lehet), de ehhez képest magyar a billentyűje, sőt még az oprendszerben is magyar van beállítva(esetleg ha dolgozik akkor nem), csak ő direkt ékezet nélkül hirdeti az igét.
Van egy programozó haverom, még a suliból marad rajtam, na ő is mindig azt mondja amit te(gondolom ez valami Hi tech csajozós duma lehet), de ehhez képest magyar a billentyűje, sőt még az oprendszerben is magyar van beállítva(esetleg ha dolgozik akkor nem), csak ő direkt ékezet nélkül hirdeti az igét. Szerk: Közben megtaláltam egy részét annak amit lehet félreértetem: [link]
[ Szerkesztve ]
-
Fiery
veterán
A DirectX detektalasa egy nyakatekert tema. Kulon lehetne detektalni a DX10 elotti adaptereket, kulon a DX10+DX11 adaptereket, es megint kulon a DX12 adaptereket. Ehhez vagy 3 kulon oldal kellene az AIDA64-ben, ami kapasbol zavart keltene jo nehany felhasznalo fejeben -- pl. mert nem ugyanazok az adapterek szerepelnenek mindharom oldalon. Vagy ossze lehet oket vonni egy oldalra, de az kompromisszumos lesz. Ez utobbit csinalja most az AIDA64, kiveve, hogy a DX12 adapterek detektalasa me'g nem kerult implementalasra. Ezert nem mutat helyes DX12 hardver megfelelest a DirectX Video oldalon az AIDA64 jelenleg.
"Erről az iGPU sebességről meg felesleges szerintem vitázni, ha valamelyik emlegetett dGPU támogatná az SVM-et, akkor lenyelné keresztbe a Carizzo gpu-ját, még úgy is, hogy hozzászámoljuk a PCIe késleltetését."
Errol tenyleg nem erdemes vitatkozni, ugyanis nem igy van
Nyilvan lenne olyan konkret GPGPU feladat, ami egy SVM-képes dGPU eseteben nagyon jo sebesseggel futna, de kozben meg lehetne boven talalni olyan kodot is, ami megroppanna a PCIe kesleltetese miatt, es iGPU-n me'g mindig gyorsabban futna. Minden attol fugg, mennyit kell ide-oda turkalni a memoriaban, es egy-egy iras/olvasas alkalmaval mekkora adatokat kell mozgatni. Ha sokszor nyulkalsz ide-oda, ha a CPU es a GPU felvaltva dolgozik az adatokon, akkor egy SVM-es APU nagyon jol tud muzsikalni.Hidd el, nekem angol kiosztasu billentyuzetem van, es a Windowst es a mobil eszkozeimet is angol nyelven hasznalom. Akkor szoktam csak egy-egy ekezetes betut beszurni, ha ugy erzem, azzal egyertelmusithetek egy-egy szot. Az iget meg olyan ertelemben nem hirdetem, hogy mas is csinaljon ugy, ahogy en -- bar nemtom, erre a fajta ige hirdetesre gondoltal-e. Nekem mindegy, ki hogyan ir, el tudom olvasni a magyar szoveget ekezettel es anelkul is
Es a csajozas nalam mar nem jatszik, iden immar 15 eve De ha megis jatszana, akkor egesz biztosan nem IT temaval probalnek egy holgyet becserkeszni [ Szerkesztve ]
-
con_di_B
tag
"OpenCL maintains memory consistency in a coarse-grained fashion in regions of buffers. We
call this coarse-grained sharing. Many platforms such as those with integrated CPU-GPU
processors and ones using the SVM-related PCI-SIG IOMMU services can do better, and can
support sharing at a granularity smaller than a buffer. We call this fine-grained sharing. OpenCL
2.0 requires that the host and all OpenCL 2.0 devices support coarse-grained sharing at a
minimum." - OpenCL 2.0 Specification 5.6.1Szoval jah, az IOMMU csak egy pelda, hogy azzal pl lehet fine-grained-et csinalni. Viszont a coarse-grained meg kotelezo, ezert magyaraztam rola, hogy hogyan lehet rapatkolni IOMMU nelkuli, meg gyakorlatilag barmilyen hardverra. Csak ilyen szempontbol vizsgaltam a kerdest, maga a feature engem mindig is relative hidegen hagyott, es inkabb veszelyt latok benne, mert lehetove teszi a portolas "felgyorsitasat" legacy C/C++ kodokrol.
Az OpenCL 1.x az annyira kotott memoriamodellel jott ki, hogy igy is ugy is at kellett varialni az adatszerkezeteidet, hogy egyaltalan futtathato programot kapjal (amibol nem mellesleg az ezutan elert speed-up nem kis resze szarmazott), ezzel szemben ha rafogod, hogy te marpedig fine-grained APU-kat tamogatsz kizarolag, onnantol kezdve barmennyire kokany meglevo adatszerkezetet radobhatsz a GPU-ra a meglevo (90%, hogy mar eleve optimalizalatlan, trehany) kodbazisodbol, aztan meg majd lehet csodalkozni, hogy miert sokkal lassabb, mint CPU-n volt.
Aztan persze mondhatod, hogy ott van az az <1% az eseteknek, amikor valaki tenyleg valami ertelmes CPU-GPU ko-op funkciot irt, de mivel minimum ket kernel launchrol beszelunk, meg ket kulon device-rol, es a szinkronizacios primitivek meg nem lettek erosebbek a 2.x-ben sem, ezert a biztos mukodesert ugyanugy kenytelen leszel buffer-level szinkronizalni, ha van fine-grained support, ha nincs.
Ennel rosszabb mar csak az lesz, amikor jonnek a szemaforok meg a felteteles valtozok, hogy a multi-threaded sracok is ugy erezzek, hogy ertenek valamihez... (bocs-bocs-bocs
)[ Szerkesztve ]
-
DRB
senior tag
A billentyűzetes dolgot ne vedd zokon, csak ugratlak.
Természetes el tudom olvasni, megerőltetés nélkül, az ékezet nélküli magyar szöveget, főleg, ha egy értelmes ember írja. Egyébként csak az tűnt fel, hogy mindig így írod az „é”-t: e', de most van egy ilyen mondatod: ...akkor remek SVM-képes APU-t vasarolhat mar most is (pl. Carrizo)., ezt nem bemásoltad.„Es a csajozas nalam mar nem jatszik, iden immar 15 eve”
Ja az más, akkor ezért nem tudod mivel lehet hanyatt vágni egy 20 éves bringát, nem érti miről beszélsz, de az a lényeg hogy okosnak tűnj, manapság az IT téma tökéletesen megfelel erre a célra, ez a menő, sőt az sem baj ha te sem érted mit beszélsz, csak akkor nehogy egy IT spinét próbál oltogatni a dumával.Tényleg nem érdemes iGPU vs. dGPU-ról vitatkozni, mert nyilván úgy kell megírni a kódot, hogy ne kelljen sokszor hozzápiszkálnija a dGPU-nak a ram-hoz, kb. csak programozói hozzáállás kérdése.
[ Szerkesztve ]


















 Mondjuk azt azért hozzátenném, hogy mindez az aida szerint, de hát az aida szerint a hardveres dx támogatás is csak 11.1, egy másik fülön meg már 11.2, valóságban meg tudjuk, hogy 12. Ne értsd félre, mindezektől függetlenül az aida egy remek kis progi, talán a műfajában a legjobb, de azért nem tökéletes, persze ilyen nincs is
Mondjuk azt azért hozzátenném, hogy mindez az aida szerint, de hát az aida szerint a hardveres dx támogatás is csak 11.1, egy másik fülön meg már 11.2, valóságban meg tudjuk, hogy 12. Ne értsd félre, mindezektől függetlenül az aida egy remek kis progi, talán a műfajában a legjobb, de azért nem tökéletes, persze ilyen nincs is ![;]](http://cdn.rios.hu/dl/s/v1.gif)

 Ha valakit ez idegesit, azzal nem tudok mit kezdeni, engem is sok minden idegesit, megsem teszem szova minden egyes embernel, hogy kiben mi idegel
Ha valakit ez idegesit, azzal nem tudok mit kezdeni, engem is sok minden idegesit, megsem teszem szova minden egyes embernel, hogy kiben mi idegel 
 Van egy programozó haverom, még a suliból marad rajtam, na ő is mindig azt mondja amit te(gondolom ez valami Hi tech csajozós duma lehet), de ehhez képest magyar a billentyűje, sőt még az oprendszerben is magyar van beállítva(esetleg ha dolgozik akkor nem), csak ő direkt ékezet nélkül hirdeti az igét.
Van egy programozó haverom, még a suliból marad rajtam, na ő is mindig azt mondja amit te(gondolom ez valami Hi tech csajozós duma lehet), de ehhez képest magyar a billentyűje, sőt még az oprendszerben is magyar van beállítva(esetleg ha dolgozik akkor nem), csak ő direkt ékezet nélkül hirdeti az igét. Új hozzászólás Aktív témák

ph A vállalat az INDE kivezetésével visszaállít minden eredeti fejlesztőkörnyezetet.
- Anime filmek és sorozatok
- OFF TOPIC 44 - Te mondd, hogy offtopic, a te hangod mélyebb!
- Frissült a MediaTek középkategóriás ajánlata
- ASUS routerek
- WLAN, WiFi, vezeték nélküli hálózat
- Total Commander
- AMD K6-III, és minden ami RETRO - Oldschool tuning
- Amazon
- 3D nyomtatás
- Kínai, és egyéb olcsó órák topikja
- További aktív témák...
