Új hozzászólás Aktív témák
-
#34295
 lezso6
HÁZIGAZDA
cskamacska
#34293
lezso6
HÁZIGAZDA
cskamacska
#34293
válasz
 cskamacska
#34293
üzenetére
cskamacska
#34293
üzenetére
Ez egy hamis dilemma, értelemszerűen NV-t érdemes venni, ha annak jobb a ár / teljesítmény mutatója. De attól még mocsokNV.
A RIOS rendkívül felhasználóbarát, csak megválogatja a barátait.
-
A RIOS rendkívül felhasználóbarát, csak megválogatja a barátait.
-
-
#34387
lezso6
HÁZIGAZDA
zovifapp111
#34383
válasz
 zovifapp111
#34383
üzenetére
zovifapp111
#34383
üzenetére
Lexikális tudáshoz nem kell agy. Csak hatalmas segg. Abunak inkább komoly forrásai vannak, egy jóféle integrált bullshit metere meg egyedi rálátása a témára.
A RIOS rendkívül felhasználóbarát, csak megválogatja a barátait.
-
válasz
 Puma K
#34404
üzenetére
Puma K
#34404
üzenetére
Persze, meg lehet oldani, hogy az ember ne legyen átverve, de hát nem rólunk van szó. Hanem azokról, akik GT 1030-at akarnak venni, mert látták a tesztet vagy szomszéd ajánlotta, stb. Na most az ilyennél megvan az esélye, hogy felezett sebességű VGA-t vesz, hisz utóbbinak is ugyanaz a neve. Etikailag nagyon nincs rendben, hogy ekkora teljesítménykülönbséggel ugyanaz a neve két terméknek.
A RIOS rendkívül felhasználóbarát, csak megválogatja a barátait.
-
-
#34688
lezso6
HÁZIGAZDA
Petykemano
#34687
válasz
 Petykemano
#34687
üzenetére
Petykemano
#34687
üzenetére
A RPM kimaradt. Azaz a 2x FP16/INT16 és 4x INT8.
A RIOS rendkívül felhasználóbarát, csak megválogatja a barátait.
-
válasz
 #45185024
#34936
üzenetére
#45185024
#34936
üzenetére
RTCore + Tensor miatt nagyobbak az SM-ek. Elvileg ugye a TU104 és TU106 között csak 12 SM-nyi különbség van (36 vs 48). Tehát 12 SM mérete durván 100mm², ami pont egy GPC, 8.33 mm² egy Turing SM.
Nézzük a Pascal-t. A GP104 és GP106 viszonyával jól lehet számolni, hiszen utóbbiban 0.5x SM és 0.75 ROP van. Ebből lehet írni két egyenletet, hogy durván mekkora egy Pascal SM illetve ROP:
200 mm² = 10 SM + 48 ROP
314 mm² = 20 SM + 64 ROPAz első duplájából vonjuk ki a másodikat, így ez lesz:
86 mm² = 32 ROP
Ennek dupláját ha levonjuk a másodikból, akkor pedig kijön, hogy:
142 mm² = 20 SM
Azaz egy SM 7.1mm². De ugye egy Turing SM-ben 64, míg egy Pascal SM-ben 128 shader van, így:
1 SM = 3.55 mm²
Tehát a Turing esetén egy SM több mint felét az RTCore meg a Tensor foglalja el, s akkor még nem számoltam gyártástechnológiákkal meg az egyéb fix egységekkel.
Igazából hülyeség ez a számolgatás, mert rohadtul nem pontos, de én legalább jól szórakoztam.
 De azért ellenőrizzünk:
De azért ellenőrizzünk:Turingnál ha 100mm² egy GPC, akkor kiszámolható, hogy 64 ROP 12 nm-en az 145 mm². Ugyanez (eltekintve az arch különségekrtől) 16 nm-en 172 mm², tehát 17%-kal kisebb az új gyártástechnológia. Na persze.

[ Szerkesztve ]
A RIOS rendkívül felhasználóbarát, csak megválogatja a barátait.
-
Ez izgi annak tudatában, hogy a Turingot állítólag a Samsung 10 nm-es node-jára tervezték, csak az nem jött össze. Ez megmagyarázza, hogy miért ilyen nagyok a chipek illetve miért nem lép akkorát a Turing.
További adalék, hogy ugye a GP107 és GP108 az tényleg a Samsungnál készült, szóval ezek szerint a teszt már megvolt kis chipekkel.
[ Szerkesztve ]
A RIOS rendkívül felhasználóbarát, csak megválogatja a barátait.
-
Hm, HD SRAM-ot nézve wikichip alapján így lenne:
14/16nm 10nm 7nm
Intel 0.0499 µm² 0.0312 µm² -
Glofo 0.0810 µm² -0.0269 µm²
TSMC 0.074 µm² 0.042 µm² 0.027 µm²
Samsung 0.064 µm² 0.040 µm² 0.026 µm²Persze tudom, a HD SRAM nem valami pontos.
Ha a Samsung 8 nm az halfnode, akkor gondolom a 10 nm-hez nagyon hasonló. Ahogy a TSMC 16 vs 12 nm. Tehát ha az NV megy a Samsunghoz, akkor gyártástechnológiai hátrányba kerül.
[ Szerkesztve ]
A RIOS rendkívül felhasználóbarát, csak megválogatja a barátait.
-
#35063
lezso6
HÁZIGAZDA
Petykemano
#35060
válasz
Petykemano
#35060
üzenetére
Write only módban vagy?
Itt megírta: [link]Végül megjelenik egy úgynevezett mesh shading is, ami valójában a vertex és a hull shadert váltja le a task shaderrel, míg a mesh shader a domain és a geometry shader lépcsőket helyettesíti. Gyakorlatilag egy új futószalagról van szó. Nem lehet elmenni amellett szó nélkül, hogy eléggé sok a hasonlóság az AMD Vega architektúrában bemutatott primitive shadinggel, ahol ugye a vertex és a hull shader lépcsőket a surface shader váltja, míg a primitive shader a domain és a geometry shader helyére kerül, illetve a leírások alapján is hasonlóra képesek az említett futószalaglépcsők, vagyis próbálják a geometria kivágását, illetve ezek kezelését hatékonyabbá tenni.
[ Szerkesztve ]
A RIOS rendkívül felhasználóbarát, csak megválogatja a barátait.
-
válasz
#45997568
#35064
üzenetére
Milyen AMD-s vagy te, hogy nem értesz hozzá?
Bár legalább érdeklődsz. Az NV-sek általában csak egy sört kérnek. ![;]](//cdn.rios.hu/dl/s/v1.gif)
Amúgy röviden kb:
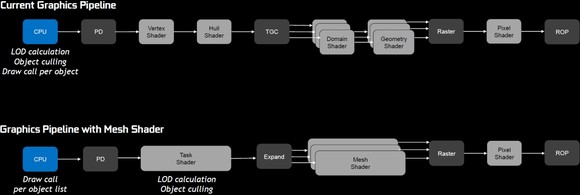
Ez fent ugye a futószalag, csak hát nem ábrázolja valami jól, de a primitive shader látszik, hogy mit vált ki.
Ez jobb, a lényeg rajta van, igaz, vegyesen angol-német-magyar, de talán érthető:
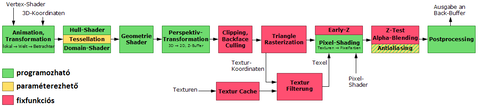
[ Szerkesztve ]
A RIOS rendkívül felhasználóbarát, csak megválogatja a barátait.
-
#35072
lezso6
HÁZIGAZDA
Petykemano
#35071
válasz
Petykemano
#35071
üzenetére
Valamelyik új játékban használák a primitive shadert, csak most nem jut eszembe melyikben. De ugye a primitive shader "okoskivágását" szabványosan is meg lehet oldani nagyjából, legalábbis Abu írta, hogy compute shaderrel is megcsinálható (s ezt is használják már valahol), de gondolom nem annyira hatékony, hisz a compute shader az a futószalagon kívül van. Cserébe bármire használható, s a compute shader futhat async compute-ként, a grafikus futószalag mellett párhuzamosan.
[ Szerkesztve ]
A RIOS rendkívül felhasználóbarát, csak megválogatja a barátait.
-
Én csak azt nem értem, hogy a Maxwell mivel nyerte azt az 50% pluszt, amennyivel azóta előrébb vannak lapkaszinten. A GK110-ig perf / area terén fej-fej mellett volt a két gyártó, sőt az AMD sokszor jobb volt (sweet spot időszak), lásd GK110 (561 mm²) vs Hawaii (438 mm²). Aztán jött a Maxwell, és a GK110-nál jobb teljesítmény megvolt a GM204-gyel 398 mm²-ből, ráadásul röhejesen magas perf / watt aránnyal. S a Pascal erre még rátett egy lapáttal.
Ami szerintem biztos:
- a GCN valamilyen skálázhatósági limitbe ütközött, lásd Tonga vs Fiji illetve Vega.
- gyárilag szénné vannak húzva a GCN-ek, hogy hozzanak egy konkurens kártyát. Pl a Polaris a GTX 970-hez, a Vega 64 a GTX 1080-hoz van igazítva. Csak egy picit alacsonyabb órajellel máris sokkal jobb a perf / watt, ezt több teszt is igazolja, illetve a Vega 56 is.Ami lehetséges ok a fentiekre:
- Gbors vesszőparipája: a ROP szám kevés, lásd Vega 56, ami a Vega 64-hez képest nem 20%-ot lassul, hanem ennek kb felét.
- a Glofo 14 nm GPU-ra jóval szarabb a TSMC 16 nm-hez képest, lehet a TSMC 7 nm-rrel helyrejön a fogyasztás.[ Szerkesztve ]
A RIOS rendkívül felhasználóbarát, csak megválogatja a barátait.
-
válasz
#45997568
#35076
üzenetére
Remélhetőleg. A Tonga-Polaris meg a Fury-Vega esetén 20-25% órajelnövekedést sikerült generálni. Míg a Maxwell-Pascal esetén 50-60% is összejött. Persze lehet utóbbi egyszerűen csak architektúrális optimalizáció, de nem hiszem. Esetleg lehet nem is a GloFo szar, hanem egyszerűen nem optimalizálták az új processzre se a Polarist se a Vegát. De ezt kétlem, volt rá idejük, főleg a Vegánál.
A RIOS rendkívül felhasználóbarát, csak megválogatja a barátait.
-
válasz
 Locutus
#35081
üzenetére
Locutus
#35081
üzenetére
Jó lett ez a puding. Legalábbis 4K-ban. FP32 jóslatok ezek voltak (IPC nélkül):
2070 = 1070 + ~12-16%
2080 = 1080 + ~8-14%
2080 Ti = 1080 Ti + ~10-19%Valóság meg...
1080p:
2080 = 1080 + ~31%
2080 Ti = 1080 Ti + ~23%1440p:
2080 = 1080 + ~37%
2080 Ti = 1080 Ti + ~33%2160p:
2080 = 1080 + ~44%
2080 Ti = 1080 Ti + ~39%Megérte áttervezni az SM-eket, kaptunk 20-30% "IPC" meg 10-15% perf / watt javulást, a 4K-t nézve.
 Egy fél CSODA azért sikerült az NV-nek. .
Egy fél CSODA azért sikerült az NV-nek. .[ Szerkesztve ]
A RIOS rendkívül felhasználóbarát, csak megválogatja a barátait.
-
válasz
#45997568
#35085
üzenetére
Jó, hát az árat nem érdemes kommentálni.
Engem a technika érdekel.Egy csomó játék bejelentettek, főleg DLSS-re. Arra kíváncsi leszek, hogy mennyi sebességvesztés jön ezzel. Ugye a mostani tesztekben a lapka fele pihen kb, szóval széjjel-boostolhatja magát. Viszont ha valami már Tensort vagy még RT-magot is használ, akkor valószínűleg jön brutál "throttling".
A RIOS rendkívül felhasználóbarát, csak megválogatja a barátait.
-
válasz
 komi77
#35126
üzenetére
komi77
#35126
üzenetére
Nem csak a nyers számítási teljesítmény számít. A Vega 64 teraflops-ban kb annyit tud, mint az 1080 Ti. Ennél 15-20%-kal tud többet a 2080 Ti. Aztán mégis jóval gyorsabb, mint 20%. A fixfunkciós egységek miatt ilyen gyors, lásd még a Kepler vs Maxwell.
A RIOS rendkívül felhasználóbarát, csak megválogatja a barátait.
-
válasz
komi77
#35134
üzenetére
Valószínűleg nincs lóvé R&D-re. Én úgy látom, hogy az NV a Maxwell-nél talált valamit, ami az AMD-nél nincs, s azóta ezt görgeti tovább. S azóta meg ugy az NV nagyon titkolódzik, s meg is van az oka rá. Maxwell előtt volt rendes verseny, azóta viszont az AMD 1.5x akkora lapkával hozza azt, amit az NV. Ez pedig egy kategóriányi különbség.
Hogy mi lesz, fogalmam sincs. Az idén érkező Vega 20-ra leszek nagyon kíváncsi, habár csak profi piacra jön, a 7 nm, dupla memória sávszél és egyebek talán hoznak valamit a konyhára. A Navi meg még homály. Szóval csak a szokásos, "majdakövetkező" reménykedés van.
[ Szerkesztve ]
A RIOS rendkívül felhasználóbarát, csak megválogatja a barátait.
-
válasz
 FLATRONW
#35139
üzenetére
FLATRONW
#35139
üzenetére
A GK110-re azért mondta Abu, hogy nem jön belőle GeForce, mert eredetileg compute-ra készült. A végül azért jött mégis, mert Jensen e-pénisze eltörpült a 7970 árnyékában. Ezért lehoztak egy nagy GPU-t. De pl a GK210-ből már nem jött GeForce.
A RIOS rendkívül felhasználóbarát, csak megválogatja a barátait.
-
-
válasz
FLATRONW
#35143
üzenetére
A 290X az a második e-penis sorvasztó kártya volt.
Aztán jött a Maxwell.A HD 7970-et az elején picivel elverte a GTX 680, de aztán az idő haladtával a HD 7970 a driverek fejlődésével utolérte, s a GHz Edition pedig megadta a kegyelemdöfést. Kényszerből hozni kellett a GK110-et a GTX 780 személyében vágott VGA-ként, a 680-t meg átnevezték 770-re.
Jó kis verseny volt, hiányzik.

[ Szerkesztve ]
A RIOS rendkívül felhasználóbarát, csak megválogatja a barátait.
-
válasz
 proci985
#35146
üzenetére
proci985
#35146
üzenetére
Ja, csak a GM204 alig kért enni, mert ultramobilra készült. Meg ott a GM200, amihez a Fury X ugyan közel van (főleg magasabb felbontáson), de nem igazán hatékony. A Maxwell hatékonysága meg azóta is megvan az NV-nél, AMD-nél erre nincs válasz, ez a gond.
De visszanézve a teszteket, nincs is akkor perf / watt különbség a GCN és a Maxwell között, mint amire emlékeztem. Viszont a 14 nm-es Radeonok elég bénák. Gyanús nekem ez a GloFo.
A RIOS rendkívül felhasználóbarát, csak megválogatja a barátait.
-
válasz
FLATRONW
#35147
üzenetére
Jaj, itt van 720p meg 900p is, ami kb hagyjuk kategória. 1080p és 1440p az relevánsabb. Kb hangyafinngal, de a 7970 GHz gyorsabb. Nekünk (vagy csak nekem?
) nem, de az NV számára ez is nagyon számít.Az adok kapok valahogy így volt:
2012 március: GTX 680 (GK104, 294 mm²)
2012 június: 7970 GE (Tahiti, 352 mm²)2012 november: Tesla K20 (GK110, 561 mm²)
2013 február: GTX Titan (drágáért ~92% GK110)
2013 május: GTX 780 (olcsóbban ~70% GK110)2013 október: 290X (Hawaii, 438 mm²)
2013 november: 780 Ti (drágáért 100% GK110)A GK110-ben van +87.5% számoló, ami a méretén látszik is, de ez nem fér bele 300 watt TDP-be, szóval jóval alacsonyabb órajeleken kell üzemelnie. Így 35-50% sikerült 1080-1440p felbontásokon. Ami amúgy jó, csak hát chipméret terén ez kurvára nem hatékony. Végül a Maxwell ezt megcsinálta, ráadásul vicc fogyasztással.
[ Szerkesztve ]
A RIOS rendkívül felhasználóbarát, csak megválogatja a barátait.
-
Éppen elég volt, vagy épp nem. Lényeg, hogy a 7970 GHz és GTX 770 az szinte teljesen megegyező teljesítményt produkálnak játékokban. Ez pedig Jensen e-péniszének nem jó.
A GK100 kuka volt, a GK110-et pedi meg kellett várni míg elkészül, nem lehetett csak úgy előhúzni zsebből. Amint a 290X jött, hiába csak pár %-kal hugyozta körbe a Titant-t, egyből elővették 780 Ti-t.Nyilván.
A RIOS rendkívül felhasználóbarát, csak megválogatja a barátait.
-
válasz
 Raymond
#35158
üzenetére
Raymond
#35158
üzenetére
Wikiről gyűjtöttem a dátumokat, fejből én sem tudom.
A 770 nem véletlenül maradt ki, mert e-penis versenyt néztem. A Maxwell meg evidens, onnantól nem volt verseny.A GK104 vs Tahiti versenyben a Tahiti mindig picit gyorsabb volt. Pont annyira, hogy az NV úgy pozícionálja a következő kártyát, hogy éppen gyorsabb legyen.
A 290 nemhogy a 770-nél, hanem a 780-nál is gyorsabb volt, itt valamit elírtál vagy elnéztél. A 290X meg titánverő volt (mondjuk nem sokkal
), nem véletlenül hozták gyorsan a 780 Ti-t.[ Szerkesztve ]
A RIOS rendkívül felhasználóbarát, csak megválogatja a barátait.
-
válasz
Raymond
#35163
üzenetére
Titánverő. 5%, nem sok, de az NV-nek ugye ez már fáj.
Pont annyira pánikoltak be, hogy előrehozták / elővették a 780 Ti-t, ami fizikailag ugyanaz, mint a Titan, csak nem vágott, így egyszerű volt előkapni. Ha nem lett volna minimálisan gyorsabb a 290X, akkor nem hozták volna a 780 Ti-t, mert nagyon drága GPU, főleg ha teljesértékű. Vagy legalábbis nem ekkor. Szerintem.[ Szerkesztve ]
A RIOS rendkívül felhasználóbarát, csak megválogatja a barátait.
-
Lesz. De ugye addigra meg az AMD is előrébb lesz. Úgyhogy lehet nem változik semmi, a mondandóm lényege az, hogy nincs itt semmilyen hardveres csoda. Itt le van írva, hogy milyen az új Forza.
Ugye csodáról beszélhetnénk, ha a Vega mellet a Turing is elhúzna a Pascaltól, de a helyzet sajnos nem ez.
[ Szerkesztve ]
A RIOS rendkívül felhasználóbarát, csak megválogatja a barátait.


 Itt nincs sör.
Itt nincs sör.  Ahhoz le kell menni a helyi Információ-Exchange & Nyugdíjcseppfolyosító Ügyosztályra.
Ahhoz le kell menni a helyi Információ-Exchange & Nyugdíjcseppfolyosító Ügyosztályra.





![;]](http://cdn.rios.hu/dl/s/v1.gif)













 Egy fél CSODA azért sikerült az NV-nek.
Egy fél CSODA azért sikerült az NV-nek. 







Új hozzászólás Aktív témák
A topikban az OFF és minden egyéb, nem a témához kapcsolódó hozzászólás gyártása TILOS!
Megbízhatatlan oldalakat ahol nem mérnek (pl gamegpu) ne linkeljetek.

Állásajánlatok

Cég: Ozeki Kft
Város: Debrecen

Cég: Ozeki Kft
Város: Debrecen