A Google hivatalos blogjában tegnap Jesse Alpert és Nissan Hajaj, a vállalat szoftvertervezői bejelentették, hogy szerintük a weben ma már több mint 1 billió (1012) egyedi URL, webcím létezik. A hatalmas számtól megilletődött mérnökök megállapítják, hogy a korábbi adatokat figyelembe véve ez azt jelenti, hogy a web naponta több milliárd weblappal bővül. A Google indexelési technológiájára igen büszke szakemberek ezek után dicsekszenek egy kicsit, s elmondják, hogy bár nem indexelik az összes lapot, mivel közülük igen sok a hasonló, illetve haszontalan, valamint az olyan generált lapok, mint a „következő nap”, gyakorlatilag végtelenné teszik a weblapok számát, de ezzel együtt is a Google keresője képes a legtöbb információt nyújtani a felhasználóknak.
A bejelentést a szaksajtóban sokan erős szkepticizmussal fogadták, s megjegyezték, hogy ez nem más, mint a Google indexének dicshimnusza. A PC World például arra hívja fel a figyelmet, hogy mára már világos, hogy nincs értelme a „nekem van több indexelt lapom” háborúját folytatni, mivel a felhasználók döntő többsége a találati listából legtöbbször csak egy vagy két lapot látogat meg, ezért inkább a relevancia számít, vagyis nem szükséges 5000 találatot megadni, elegendő 10–20 valóban használható link, illetve még jobb, ha egy konkrét kérdésre konkrét válasz érkezik.
Az sokkal érdekesebb, hogy a Google keresőjének működéséről is beszámolnak röviden a mérnökök. Mint írják, a keresés olyan oldalakról indul el, melyek sok kapcsolattal rendelkeznek, majd az új oldalakon lévő linkeket követik, és így tovább. A begyűjtött linkek közül azután szelektálnak, eltávolítják a duplikátumokat. Ezek után jön az adatok feldolgozása a Google PageRank algoritmusával, mely a kapcsolatok alapján rangsorolja a weboldalakat. Ezt a munkát 1998-ban, amikor 26 millió egyedi weblapot számoltak, még néhány óra alatt elvégezték, s időnként frissítették. Ma már folyamatosan fut a program, s naponta többször elvégzik a matematikai elemzést. A blog írói a munka nagyságát érzékeltetve elmondják, hogy az egybillió lap által meghatározott „linktérkép” (link graph) ötvenezerszer nagyobb, mint az Egyesült Államok közlekedési hálózatának térképe.
PageRank kontra BrowseRank
A „számháború” mögött talán az áll, hogy a Google blogbejegyzésének születésével szinte egy időben jelent meg egy Microsoft-közlemény arról, hogy a vállalat kutatói egy szingapúri konferencián bejelentettek egy új fejlesztést, mely a PageRank vetélytársa lehet esetleg. A Microsoft fejlesztői kínai kutatók közreműködésével dolgozták ki a módszert, amely szerintük a kulcsszavas keresések találati hatékonyságát növelné meg.
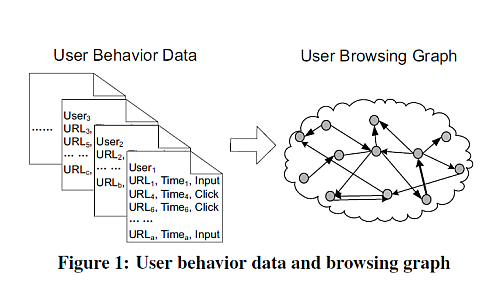
A közleményben a kutatók kifejtik, hogy a Google algoritmusa az alapján állapítja meg az adott oldal rangját, hogy hány és milyen rangú oldalról érkező link mutat rá. Az új eljárás, a BrowseRank fejlesztői szerint ez nem ad elég jó eredményt, mivel például a kifelé mutató linkek igen gyorsan változnak, újak jönnek, a régebbit törlik. Ők inkább a felhasználói viselkedést figyelnék: az oldalakra látogatók számát, illetve az egyes oldalakon eltöltött időt. Arra is hivatkoznak, hogy a Google módszerét egyrészt könnyű manipulálni, illetve fals eredményekhez is vezethet, mint például az Adobe.com esetében, mely igen magas ranggal rendelkezik, ám nem azért, mert sokan látogatnak el ide, hanem azért, mert rengeteg oldalon linkelik be az Adobe Reader vagy a Flash Player letöltési lehetőségét. Valójában például a MySpace vagy a Facebook nagyságrendekkel fontosabb, ha a látogatók számát és az ott töltött időt veszik figyelembe. A közleményben megemlítik, hogy ez a módszer ugyanakkor maximálisan tiszteletben tartja a felhasználók személyes adatait.
![]()
A Google erre a kutatásra reagálva többek között megemlítette, hogy legfontosabb technológiájuk messze nem olyan egyszerű, mint amilyennek a Microsoft fejlesztői beállítják, s a jogvédett PageRank által kapott adat csak egyike annak a körülbelül 200 jelnek, melyeket feldolgozva végül is meghatározzák egy adott weboldal relevanciáját.







